
Spark SQL
Hive and Shark
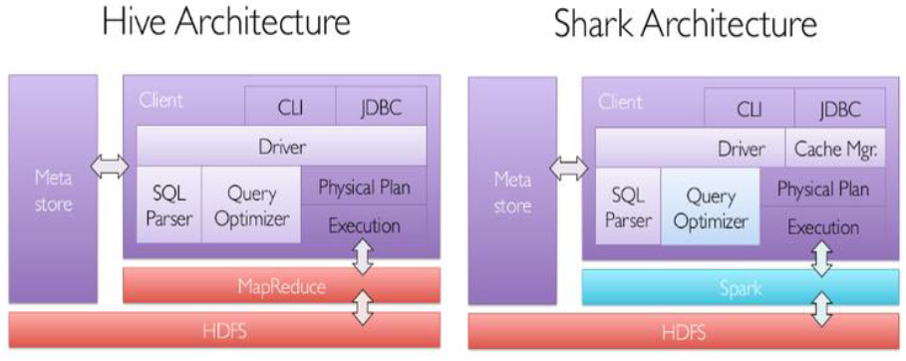
SparkSQL的前身是Shark,是给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是运行在Hadoop上的SQL-on-hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,运行效率低。为了提高SQL-on-Hadoop的效率,shark 应运而生。它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。
Spark SQL配置
安装配置hive
spark需要使用hive中的metastore服务。这里之前在hive笔记中有详细的搭建流程,就不在记录了。
配置spark
配置spark的hive-site.xml
<configuration>
<!-- HDFS start -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive使用的HDFS目录</description>
</property>
<!-- HDFS end -->
<!-- metastore start 在客户端使用时,mysql连接和metastore同时出现在配置文件中,客户端会选择使用metastore -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>校验metastore版本信息是否与sparkjar 版本一致;true:校验;false:不校验</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://nn1:9083</value>
</property>
<!-- metastore end -->
<!-- hiveserver start -->
<property>
<name>hive.server2.thrift.min.worker.threads</name>
<value>5</value>
<description>Minimum number of Thrift worker threads</description>
</property>
<property>
<name>hive.server2.thrift.max.worker.threads</name>
<value>500</value>
<description>Maximum number of Thrift worker threads</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>nn1</value>
<description>hive开启的thriftServer地址</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>20000</value>
<description>开启spark的thriftServer端口</description>
</property>
<!-- hiveserver end -->
</configuration>hive.metastore.schema.verification,用于校验 metastore版本信息是否与spark jar 版本一致;true:校验;false:不校验;
hive 有个hiveserver2服务,端口是10000;而spark 用的hiveserver2服务,配置的端口是20000,不冲突。
Spark SQL启动
先启动hdfs、yarn、metastore
spark-sql shell
spark-sql –master yarn –queue root.master –num-executors 2 –executor-memory 1G --executor-cores 2这种方式每个人一个driver彼此之间的数据无法共享。
启动任务后,发现还没跑 任务,就已经占用了 资源,因为现在还没有机制能计算出跑SQL任务会用多少内存。而hive是只有跑任务才去算占用多少资源。

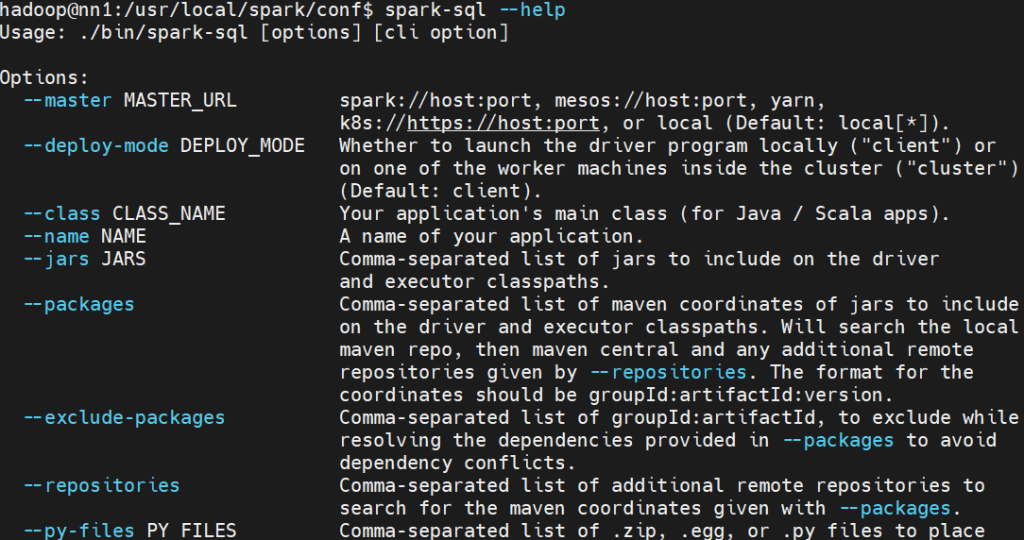
使用命令可以执行代码脚本等,通过spark-sql –help可以查看CLI命令参数。
spark thriftserver
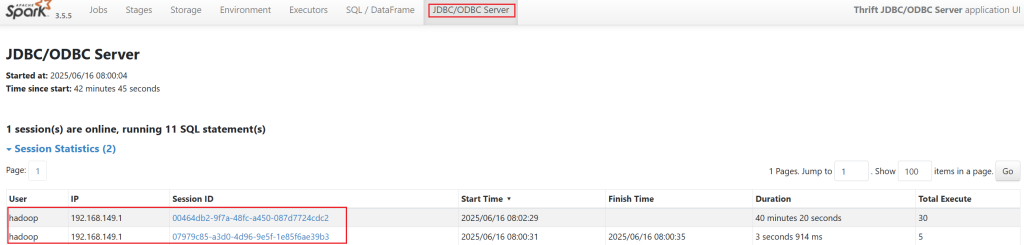
ThriftServer是一个JDBC/ODBC接口,用户可以通过JDBC/ODBC连接ThriftServer来访问SparkSQL的数据。ThriftServer在启动的时候,会启动了一个SparkSQL的应用程序,而通过JDBC/ODBC连接进来的客户端共同分享这个SparkSQL应用程序的资源,也就是说不同的用户之间可以共享数据;ThriftServer启动时还开启一个侦听器,等待JDBC客户端的连接和提交查询。所以,在配置ThriftServer的时候,至少要配置ThriftServer的主机名和端口,如果要使用Hive数据的话,还要提供Hive Metastore的uris。
这种方式所有人可以通过driver连接,彼此之间的数据可以共享。
启动
#启动yarn集群
#启动hive服务
nohup hive --service metastore > /dev/null 2>&1 &
#启动thriftserver服务
/usr/local/spark/sbin/start-thriftserver.sh --master yarn --executor-cores 1 --executor-memory 1G --queue masterbeeline 连接
beeline 分为hive 和 spark的。
/usr/local/spark/bin/beeline
!connect jdbc:hive2://nn1:20000同样也可以使用工具连接,这里我就是用了dbeaver连接的。
在WEBUI中可以查看有哪些人连接
测试sparkSQL
创建数据库
create database lmktest;
use lmktest;创建表, 这里我是无法创建student表的,因为这里使用了与hive相同的metastore。同一个mysql库,这个student的元数据在hive中已经使用了。所以就不能创建student,这里我加了一个前缀。当然,如果库名不同,就没有问题。
create table spark_student (id int, name string, age int)
row format delimited fields terminated by ' '准备数据,并将数据load进入数据表中。
load data local inpath '/home/hadoop/test/createtable/spark_student' into table spark_student;到这之前与hive的操作都是相同的,不同的是,spark可以进行缓存操作。
cache table 表名;
cache table spark_student;
-- 去除缓存
uncache table spark_student;
cache table 数据集别名 as 查询SQL
cache table cnt_table as select id,count(1) from spark_student group by id;
uncache table cnt_table;缓存也可以在WEBUI中查看

spark-webUI
怎么合理的运用并行化,比如要处理的数据最终生成的partition是30个,那你的job设置的资源就应该是10到15个cores。为什么呢?因为官方推荐的设置是(2~3)*cores = parttions,这样设置的主要原因是executor不会太闲置或者太繁忙。这里推荐的是standalone模式,如果使用的是yarn模式,那么与yarn虚拟核数1: 1就可以了。
模拟数据
# 进入到nn1机器中
python3
with open("/home/hadoop/test/createtable/abc.txt","a") as f:
for i in range(100000):
f.write("%s,lmk_%s,%s\n" % (i,i,i))使用load加载文件中的数据十次进入表
load data local inpath '/home/hadoop/test/createtable/abc.txt' into table stu执行下面count语句
select count(1) from stu 在webUI中可以看到一下内容,RDD会有多少个task,也就是有多少个partition

因为读取的数据个数10个文件,对应存在10个block块,分区就是10个
单独统计每个文件的元素的个数,然后整体统计所有的元素的个数
再看任务总cores资源是多少
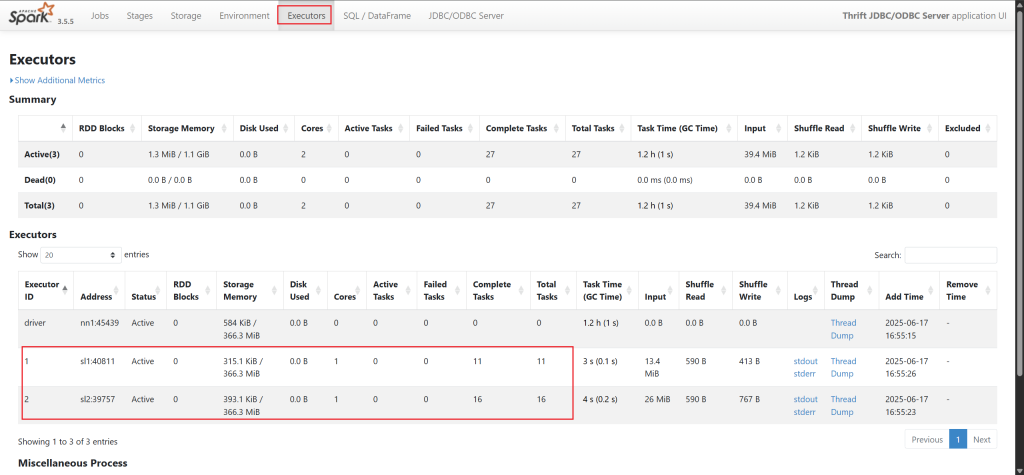
job运行11个task,提供的CPU核数2个, 相对比较合理,但CPU核有空转的。所以要尽量保证是倍数关系,不要超过,多出来的会有CPU核有空转。
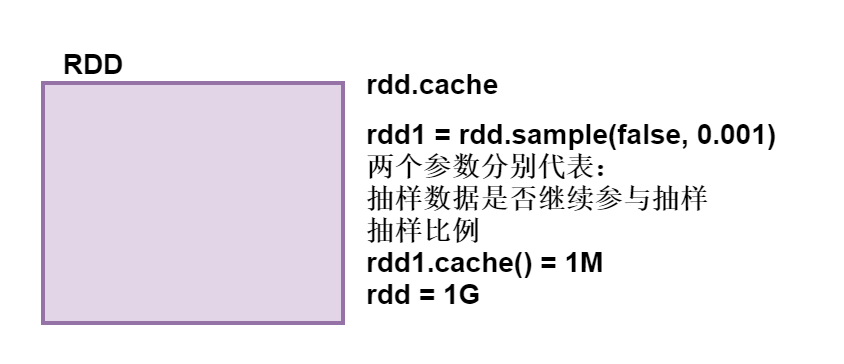
在sparkSQL里RDD会使用多大的存储空间,直接缓存表方式:
- 如果表数据是txt格式,可以根据表对应hdfs的大小来设定。
- 如果表数据是orc格式文件,那缓存的大小 = 对应hdfs的大小 * 3。
RDD操作中也有cache,查看cache的大小需要抽样。
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T] = {
require(fraction >= 0,
s"Fraction must be nonnegative, but got ${fraction}")- withReplacement:表示抽出样本后是否在放回去,true表示会放回去,这也就意味着抽出的样本可能有重复
- fraction :抽出多少,这是一个double类型的参数,0-1之间,eg:0.3表示抽出30%
- seed:表示一个种子,根据这个seed随机抽取,一般情况下只用前两个参数就可以,那么这个参数是干嘛的呢,这个参数一般用于调试,有时候不知道是程序出问题还是数据出了问题,就可以将这个参数设置为定值
JDBC连接thriftserver
首先,在pom里添加spark的hive-jdbc
<!-- 访问spark thriftserver 用的-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
</exclusion>
</exclusions>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>执行代码如下:
package com.lmk.spark
import org.apache.hive.jdbc.HiveDriver
import java.sql.{DriverManager, ResultSet}
object TestBeeline {
def main(args: Array[String]): Unit = {
// scala jdbc 连接sparksql
classOf[HiveDriver]
val con = DriverManager.getConnection("jdbc:hive2://nn1:20000", "hadoop", null)
val set : ResultSet = con.prepareStatement("select count(1) as cnt from sparktest.stu").executeQuery()
while (set.next()) {
println(set.getString("cnt"))
}
con.close()
}
}sparkSQL编程
| DataFrame操作 | scala | 说明 |
|---|---|---|
| 查看表数据 | df.show | |
| 查看表结构 | df.printSchema() | |
| 查询指定字段 | df.select(df.col(“字段名”)) | |
| 给指定字段数据+1 | df.select(df.col(“字段名”) + 1) | |
| 筛选字段值小于2 | df.filter(df.col(“字段名”) < 2) | |
| 按照字段分区count | df.groupby(“字段名”).count | 默认产生200个分区 |
| 给字段起别名 | df.select(df.col(“字段名”).as(“新字段名”)) df.select(df.col(“字段名”).alias(“新字段名”)) | |
| 模糊查询 | df.filter(df.col(“字段名”).like(“%xxx%”)) | |
| 转rdd | df.rdd |
DataFrame 对象
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这样的数据集可以用SQL查询。
方式1:toDF
package com.lmk.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
object TestSparkSql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("TestSparkSql")
val sc = new SparkContext(conf)
val sqlsc = new SQLContext(sc)
import sqlsc.implicits._
val rdd = sc.textFile("data/sparktest.txt")
.map(x => {
val strs = x.split(" ")
(strs(0).toInt, strs(1), strs(2).toInt)
})
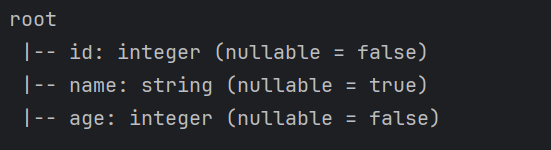
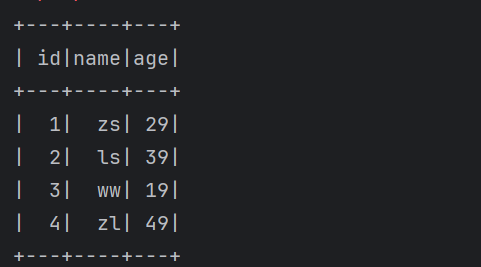
val df = rdd.toDF("id", "name", "age")
df.printSchema() // 打印表结构信息
df.show() // 以表的格式打印数据
}
}结果如下:
方式2: 使用类定义schema
package com.lmk.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
object TestSparkSql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("TestSparkSql")
val sc = new SparkContext(conf)
val sqlsc = new SQLContext(sc)
import sqlsc.implicits._
val rdd = sc.textFile("data/sparktest.txt")
.map(x => {
val strs = x.split(" ")
new student(strs(0).toInt, strs(1), strs(2).toInt)
})
// val df = rdd.toDF("id", "name", "age")
val df = rdd.toDF
df.printSchema() // 打印表结构信息
df.show() // 以表的格式打印数据
}
}
// 样例类,不用加构造器
case class student(var id: Int, var name: String, var age: Int)方式3: createDataFrame
这种方式需要将rdd和schema信息进行合并,得出一个新的DataFrame对象。
package com.lmk.spark
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object TestSparkSqlWithCreate {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestSparkSqlWithCreate")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlsc = new SQLContext(sc)
val rdd = sc.textFile("data/sparktest.txt")
.map(x => {
val strs = x.split(" ")
Row(strs(0).toInt, strs(1), strs(2).toInt)
})
// rdd + schema
val schema = StructType(
Array(
StructField("id", IntegerType),
StructField("name", StringType),
StructField("age", IntegerType)
)
)
val df = sqlsc.createDataFrame(rdd, schema)
df.printSchema()
df.show()
}
}sparksql的查询方式
第二个部分关于df的查询
sql api查询
第一种sql api的方式查询
- 使用的方式方法的形式编程
- 但是思想还是sql形式
- 和rdd编程特别相似的一种写法
package com.lmk.spark
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object TestSparkSqlWithCreate {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestSparkSqlWithCreate")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlsc = new SQLContext(sc)
val rdd = sc.textFile("data/sparktest.txt")
.map(x => {
val strs = x.split(" ")
Row(strs(0).toInt, strs(1), strs(2).toInt, strs(3))
})
// rdd + schema
val schema = StructType(
Array(
StructField("id", IntegerType),
StructField("name", StringType),
StructField("age", IntegerType),
StructField("gender", StringType)
)
)
val df = sqlsc.createDataFrame(rdd, schema)
// sql api
// select * from student where age > 20
// df.where("age > 20").show()
df.groupBy("gender").avg("age").orderBy("avg(age)").show()
// 聚合函数没有别名
// desc的关键字无法识别
// 没法实现整体的多次聚合,只能一个一个聚合
// 查询数据的高级操作
// 查询的方法中可以加入字符串表达列信息,加入列的对象表示列的信息,同时还有一些附属的高端功能
// df.orderBy("age desc")
import org.apache.spark.sql.functions._
import sqlsc.implicits._
df.select($"age".+(1)).orderBy($"age".desc).show()
df.select(col("age").+(1)).orderBy(col("age").desc).show()
df.select(df("age").+(1)).orderBy(df("age").desc).show()
// 聚合函数加别名
df.groupBy("gender").agg(count("id").as("cnt"),avg("age").as("avg_age")).orderBy($"avg_age".desc).show()
}
}api查询函数使用
// 数值函数 ceil floor round
// 字符串函数 concat concat_ws substr
// 判断 if case when
// 使用withColumn,就会多出一列可操作的列
df.withColumn("concat_col", concat_ws("<->",$"name", $"gender")).show()api查询join使用
// 分数数据
val df_score = sc.makeRDD(Array(
(1, 68, 95),
(2, 49, 84),
(3, 80, 91),
(4, 70, 92)
)).toDF("id", "math", "english")
// api方式
// 如果列相同,直接写列名
df.join(df_score, "id").show()
// 如果列不同就需要写条件
df.join(df_score, df("id") === df_score("id")).show()api查询窗口函数使用
// window
// select *, row_number() over(partition by gender order by age desc) rn from student
import org.apache.spark.sql._
import sqlsc.implicits._
df.withColumn("rn", row_number().over(Window.partitionBy("gender").orderBy($"age".desc))).where("rn = 1").show()纯sql查询
第二种纯sql形式的查询
- 首先注册表
- 然后使用sql查询
- 最终得出的还是dataFrame的对象
- 其中和rdd的编程没有任何的区别,只不过现在使用sql形式进行处理了而已
package com.lmk.spark
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object TestSparkSqlWithCreate {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestSparkSqlWithCreate")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlsc = new SQLContext(sc)
val rdd = sc.textFile("data/sparktest.txt")
.map(x => {
val strs = x.split(" ")
Row(strs(0).toInt, strs(1), strs(2).toInt, strs(3))
})
// rdd + schema
val schema = StructType(
Array(
StructField("id", IntegerType),
StructField("name", StringType),
StructField("age", IntegerType),
StructField("gender", StringType)
)
)
val df = sqlsc.createDataFrame(rdd, schema)
// 查询
df.createTempView("student")
val df1 = sqlsc.sql(
"""
|select count(1) as cnt, gender from student group by gender
|""".stripMargin)
df1.createTempView("student1")
val df2 = sqlsc.sql(
"""
|select * from student1 where cnt > 1
|""".stripMargin)
df2.show()
// 分数数据
val df_score = sc.makeRDD(Array(
(1, 68, 95),
(2, 49, 84),
(3, 80, 91),
(4, 70, 92)
)).toDF("id", "math", "english")
// sql方式
df.createTempView("student")
df_score.createTempView("score")
sqlsc.sql("select * from student s join score sc on s.id=sc.id").show()
}
}查询练习
电影推荐的练习,获取每个用户最喜欢哪个类型的电影,使用两种方式实现,代码如下:
package com.lmk.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.expressions.Window
import org.apache.spark.{SparkConf, SparkContext}
object TestMovieWithSql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestMovieWithSql")
conf.setMaster("local[*]")
conf.set("spark.shuffle.partitions", "20")
val sc = new SparkContext(conf)
val sqlsc = new SQLContext(sc)
import sqlsc.implicits._
import org.apache.spark.sql.functions._
// 处理数据
val df1 = sc.textFile("data/movies.txt")
.flatMap(x => {
val strs = x.split(",")
val mid = strs(0)
val ty = strs.reverse.head
val mvname = strs.tail.reverse.tail.reverse.mkString(" ")
ty.split("\\|").map((mid, mvname, _))
}).toDF("mid", "mvname", "type")
val df2 = sc.textFile("data/ratings.txt")
.map(x => {
val strs = x.split(",")
(strs(0), strs(1), strs(2).toDouble)
}).toDF("uid", "mid", "rate")
// 每个用户最喜欢哪个类型的电影
// sql查询方式
df1.createTempView("movie")
df2.createTempView("rating")
sqlsc.sql(
"""
|with a as (
|(select count(rate) cnt, uid, type
|from movie mv
|left join rating rt on mv.mid=rt.mid
|group by uid, type))
|
|select cnt, uid, type
|from
|(select rank() over(partition by uid order by cnt desc) rk
|,cnt
|,uid
|,type
|from a)
|where rk=1
|
|""".stripMargin).show(200, false)
// api查询方式
df1.join(df2, "mid")
.groupBy("uid", "type")
.agg(count("rate").as("cnt"))
.withColumn("rk", rank().over(Window.partitionBy("uid").orderBy($"cnt".desc)))
.where("rk = 1")
.show(200, false)
}
}
获取每个用户最喜欢哪个类型的电影后,再获取每个类型中最受欢迎的前三个电影,然后给用户推荐。
// 每个用户最喜欢哪个类型的电影
// 获取每个类型中最受欢迎的前三个电影,然后给用户推荐。
// sql查询方式
df1.createTempView("movie")
df2.createTempView("rating")
sqlsc.sql(
"""
|with ut as (
|select count(rate) cnt,
|uid, type
|from movie mv
|left join rating rt on mv.mid=rt.mid
|group by uid, type),
|
|user_fav as (select cnt, uid, type
|from
|(select rank() over(partition by uid order by cnt desc) rk
|,cnt
|,uid
|,type
|from ut)
|where rk=1),
|
|rt as (select avg(rate) avgr, mvname, mv.type
|from movie mv
|left join rating rt on mv.mid=rt.mid
|group by mvname, mv.type),
|
|mv as (select *
|from
|(select row_number() over(partition by type order by avgr desc) rn,
|type, mvname
|from rt
|) v where rn<=3)
|
|select uid,
|uf.type,
|mvname
|from user_fav uf
|left join mv on uf.type=mv.type
|
|""".stripMargin).show(200, false)
// api查询方式
val dfuf = df1.join(df2, "mid")
.groupBy("uid", "type")
.agg(count("rate").as("cnt"))
.withColumn("rk", rank().over(Window.partitionBy("uid").orderBy($"cnt".desc)))
.where("rk = 1")
df1.join(df2, "mid")
.groupBy("type", "mvname")
.agg(avg("rate").as("avgr"))
.withColumn("rn", row_number().over(Window.partitionBy("type").orderBy($"avgr".desc)))
.where("rn <= 3")
.join(dfuf, "type")
.select("uid", "type", "mvname")
.show(200, false)
}
}
SparkSQL读写数据
我们使用sparksql进行编程,编程的过程我们需要创建dataframe对象,这个对象的创建方式我们是先创建RDD然后再转换rdd变成为DataFrame对象。
但是sparksql提供了多种便捷读取的方式
// 原始读取方式
sc.textfile().toRDD
sqlsc.createDataFrame(rdd, schma)
// 更便捷的读取方式
sqlSc.read.text|orc|parquet|jdbc|csv|json
df.write.text|orc|parquet|jdbc|csv|jsonwrite存储数据的时候也是文件夹的,而且文件夹不能存在
- text文本普通文本,但是这个文本必须只能保存一列内容
- csv是一个介于文本和excel之间的一种格式,如果是文本打开用逗号分隔的
以上两个文本都是只有内容的,没有列的
- orc格式一个列式存储格式,hive专有的
- parquet列式存储,顶级项目
以上都是列式存储问题,优点(1.列式存储,检索效率高,防止冗余查询 2.带有汇总信息,查询特别快 3.带有轻量级索引,可以跳过大部分数据进行检索),他们都是二进制文件,带有格式信息
- json是一种字符串结构,本质就是字符串,但是存在kv,例子 {“name”:“zhangsan”,“age”:20}
多平台解析方便,带有格式信息
- jdbc 方式,它是一种协议,只要符合jdbc规范的服务都可以连接,mysql,oracle,hive,sparksql
输出数据
// api查询方式
val dfuf = df1.join(df2, "mid")
.groupBy("uid", "type")
.agg(count("rate").as("cnt"))
.withColumn("rk", rank().over(Window.partitionBy("uid").orderBy($"cnt".desc)))
.where("rk = 1")
val df3 = df1.join(df2, "mid")
.groupBy("type", "mvname")
.agg(avg("rate").as("avgr"))
.withColumn("rn", row_number().over(Window.partitionBy("type").orderBy($"avgr".desc)))
.where("rn <= 3")
.join(dfuf, "type")
.select("uid", "type", "mvname")
//.show(200, false)
//df3.write.csv("data/csv")
df3.write.format("org.apache.spark.sql.execution.datasources.v2.csv.CSVDataSourceV2").save("data/csv")
//df3.write.json("data/json")
df3.write.format("org.apache.spark.sql.execution.datasources.v2.json.JsonDataSourceV2").save("data/json")
df3.write.orc("data/orc")
//df3.write.parquet("data/parquet")
df3.write.format("org.apache.spark.sql.execution.datasources.v2.parquet.ParquetDataSourceV2").save("data/parquet")
// text
df3.withColumn("line", concat_ws(",", $"uid", $"type", $"mvname")).select("line")
.write
.format("org.apache.spark.sql.execution.datasources.v2.text.TextDataSourceV2").save("data/text")
val pro = new Properties()
pro.put("user", "root")
pro.put("password", "123456")
df3.write.jdbc("jdbc:mysql://nn1:3306/lmktest", "movie", pro)读取数据
package com.lmk.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
import java.util.Properties
object TextReadData {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("TextReadData")
val sc = new SparkContext(conf)
val sqlsc = new SQLContext(sc)
sqlsc.read.format("org.apache.spark.sql.execution.datasources.v2.csv.CSVDataSourceV2").load("data/csv").show()
sqlsc.read.format("org.apache.spark.sql.execution.datasources.v2.json.JsonDataSourceV2").load("data/json")
sqlsc.read.format("org.apache.spark.sql.execution.datasources.v2.parquet.ParquetDataSourceV2").load("data/parquet")
sqlsc.read.orc("data/orc").show()
sqlsc.read.format("org.apache.spark.sql.execution.datasources.v2.text.TextDataSourceV2").load("data/text")
val pro = new Properties()
pro.put("user", "root")
pro.put("password", "123456")
sqlsc.read.jdbc("jdbc:mysql://nn1:3306/lmktest", "movie", pro)
}
}读取hive数据
将hive-site.xml,core-site.xml,hdfs-site.xml放入到src/main/resources
package com.lmk.spark
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
object TestHive {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestHive")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
// sparksql --> sqlSc
// hive --> hiveSc ,包含sqlSc
val hsc = new HiveContext(sc)
hsc.sql("show databases").show()
hsc.sql(
"""
|
|select *
|from student
|limit 10
|""".stripMargin).show()
}
}这里我在使用的时候并没有连接我集群对应的metastore,使用了本地的hive。
这里需要在hive-site.xml中添加
<property>
<name>hive.metastore.uris</name>
<value>thrift://nn1:9083</value>
<description>Hive metastore thrift 服务地址,Spark 连接所必需</description>
</property>sparksession
之前使用的操作对象有三个
- sparkContext主要是为了rdd编程而产生的一个操作对象
- sqlContext主要是为了sparksql的编程而产生的
- hiveContext主要是操作hive的对象
归一化的对象就是sparksession,融合了sc、sqlSc、hsc三种。
package com.lmk.spark
import org.apache.spark.sql.SparkSession
object TestSession {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.enableHiveSupport() // 加上就可以操作hive
.master("local[*]").appName("TestSession").getOrCreate()
// session 包含sqlsc hivesc
import session.implicits._
val sc = session.sparkContext
// 使用sql查询hive中的数据
session.sql("show databases").show()
val df = sc.textFile("data/a.txt").map(x => {
val strs = x.split(" ")
(strs(0), strs(1), strs(2), strs(3))
}).toDF("id", "name", "age", "city")
df.show()
}
}dataset
dataset 是 dataFrame的一个升级版对象,dataFrame是一个传统的sql编程对象。如果想要使用dataFrame进行灵活开发比较困难。
对于dataset,与dataFrame是一个类别的对象,都是可以进行sql查询数据的,并且可以支持rdd上面的方法。所以需要对一个表对象进行二次处理的情况下,尽量使用dataset。
package com.lmk.spark
import org.apache.spark.sql.{Dataset, SparkSession}
object TestDSAndDF {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("TestDSAndDF").getOrCreate()
import session.implicits._
val ds: Dataset[String] = session.read.textFile("file:///D:\\ProgramFile\\spark\\data\\a.txt")
ds.map(x => {
val strs = x.split(" ")
(strs(0), strs(1), strs(2), strs(3))
})
// val df = session.read.format("org.apache.spark.sql.execution.datasources.v2.text.TextDataSourceV2")
// .load("file:///D:\\ProgramFile\\spark\\data\\a.txt")
// val ds: Dataset[(String, String, String, String)] = df.map(r => {
// val line = r.getAs[String]("value")
// val strs = line.split(" ")
// (strs(0), strs(1), strs(2), strs(3))
// })
}
}rdd、df、ds之间的区别
- 概念区别
- rdd:弹性分布式数据集;
- DataFrame:是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这样的数据集可以用SQL查询。DataFrame 是 DataSet[Row];
- DataSet:Dataset是一个强类型的特定领域的对象,Dataset也被称为DataFrame的类型化视图,这种DataFrame是Row类型的Dataset,即Dataset[Row]。
- rdd不支持sql查询
- ds数据类型灵活度比较高,df放入的仅仅是row类型
- ds可以使用toDF转换成df,但是df无法转换成ds
RDD、DataFrame、Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换;
val session = SparkSession.builder().master("local[*]").appName("TestDSAndDF").getOrCreate()
import session.implicits._
val ds: Dataset[String] = session.read.textFile("file:///D:\\ProgramFile\\spark\\data\\a.txt")
ds.map(x => {
val strs = x.split(" ")
(strs(0), strs(1), strs(2), strs(3))
})
ds.toDF()
ds.rdd
val rdd = session.sparkContext.textFile("file:///D:\\ProgramFile\\spark\\data\\a.txt")
rdd.toDF()
rdd.toDS()
val df = session.read.format("org.apache.spark.sql.execution.datasources.v2.text.TextDataSourceV2")
.load("file:///D:\\ProgramFile\\spark\\data\\a.txt")
df.rddspark-sql的UDF
UDF、UDAF、UDTF的定义与之前hive学习中的一样。
- UDF:一对一,函数接受一行中一个或多个字段,返回一个值;
- UDAF:聚合函数,多行作为参数,返回一行数据;
- UDTF:拆分函数,一行输出多行数据。
udf
数据准备
1 zs 20000 10000
2 ls 21000 17000
3 ww 24000 20000代码实现如下:
package com.lmk.spark
import org.apache.spark.sql.{SparkSession, functions}
object TestUDF {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("TestUDF").getOrCreate()
import session.implicits._
val df = session.sparkContext.textFile("data/salary.txt")
.map(x => {
val strs = x.split(" ")
(strs(0), strs(1), strs(2).toInt, strs(3).toInt)
})
.toDF("id", "name", "salary", "bonus")
df.createOrReplaceTempView("salary")
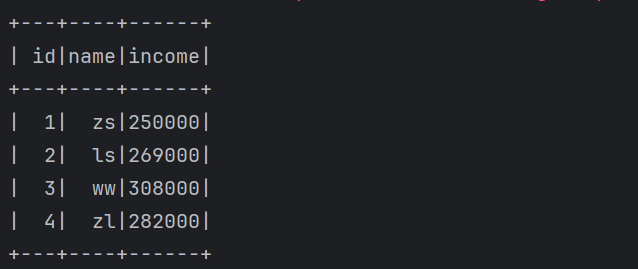
session.udf.register("all_income", (salary: Int, bonus: Int) => {
salary * 12 + bonus
})
//使用sql的方式调用
session.sql("select id, name, all_income(salary, bonus) income from salary").show()
// 使用api的方式调用
import org.apache.spark.sql.functions._
df.withColumn("income", functions.callUDF("all_income", $"salary", $"bonus"))
.select("id", "name", "income")
.show()
}
}结果如下:
udaf
开发的指南可以在官网spark.apache.org查看
老版本实现代码如下:
package com.lmk.spark
import org.apache.spark.sql.{Encoder, Encoders, SparkSession, functions}
import org.apache.spark.sql.expressions.Aggregator
object TestUDAF {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("TestUDAF").getOrCreate()
import session.implicits._
val df = session.sparkContext.textFile("data/sparktest.txt")
.map(x => {
val strs = x.split(" ")
(strs(0).toInt, strs(1), strs(2).toInt, strs(3))
}).toDF("id", "name", "age", "gender")
// avg(age)
import org.apache.spark.sql.functions._
val df1 = df.agg(avg("age"))
val df2 = df.groupBy("gender").agg(avg("age"))
val sum = new MySum
val mysum = functions.udaf(new MySum)
df.createTempView("student")
session.sql("select mysum(age) from student").show()
}
}
class MySum extends Aggregator[Int, Int, Int] {
// 初始化
override def zero: Int = 0
// 获取一个值,累加逻辑
override def reduce(b: Int, a: Int): Int = a + b
// 最终合并
override def merge(b1: Int, b2: Int): Int = b1 + b2
// 结束返回
override def finish(reduction: Int): Int = reduction
// 累加的结果类型
override def bufferEncoder: Encoder[Int] = Encoders.scalaInt
// 最终结果类型
override def outputEncoder: Encoder[Int] = Encoders.scalaInt
}新版本实现代码如下:
package com.lmk.spark
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, IntegerType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
object TestUDAF {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("TestUDAF").getOrCreate()
import session.implicits._
val df = session.sparkContext.textFile("data/sparktest.txt")
.map(x => {
val strs = x.split(" ")
(strs(0).toInt, strs(1), strs(2).toInt, strs(3))
}).toDF("id", "name", "age", "gender")
// avg(age)
import org.apache.spark.sql.functions._
val df1 = df.agg(avg("age"))
val df2 = df.groupBy("gender").agg(avg("age"))
// val sum = new MySum
// val mysum = functions.udaf(new MySum)
// 注册 UDAF 为 SQL 函数
session.udf.register("mysum", new MySumUDAF)
df.createOrReplaceTempView("people")
df.createTempView("student")
session.sql("select mysum(age) from student").show()
}
}
/**
* 新版 Spark 中,不能直接用 Aggregator 注册 SQL 函数,必须改写为 UserDefinedAggregateFunction
* 否则只能用于 DSL 中。
*/
class MySumUDAF extends UserDefinedAggregateFunction {
// 输入的数据类型
override def inputSchema: StructType = StructType(StructField("value", IntegerType) :: Nil)
// 中间 buffer 类型(累加)
override def bufferSchema: StructType = StructType(StructField("sum", IntegerType) :: Nil)
// 最终返回类型
override def dataType: DataType = IntegerType
override def deterministic: Boolean = true
// 初始化 buffer
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0
}
// 更新 buffer
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getInt(0) + input.getInt(0)
}
}
// 合并 buffer(用于分区之间)
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getInt(0) + buffer2.getInt(0)
}
// 返回最终结果
override def evaluate(buffer: Row): Any = buffer.getInt(0)
}avg的实现
package com.lmk.spark
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession, functions}
object TestUDAF {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("TestUDAF").getOrCreate()
import session.implicits._
val df = session.sparkContext.textFile("data/sparktest.txt")
.map(x => {
val strs = x.split(" ")
(strs(0).toInt, strs(1), strs(2).toInt, strs(3))
}).toDF("id", "name", "age", "gender")
println("--- 使用 Spark 内置的 avg 函数 ---")
import org.apache.spark.sql.functions._
df.agg(avg("age")).show()
df.groupBy("gender").agg(avg("age")).show()
// 注册我们自定义的平均值 UDAF
session.udf.register("myavg", new MyAvgUDAF)
df.createOrReplaceTempView("people")
println("--- 使用 SQL 和自定义的 myavg 函数 ---")
// 计算全体的平均年龄
session.sql("SELECT myavg(age) as custom_avg_age FROM people").show()
// 按性别计算平均年龄
session.sql("SELECT gender, myavg(age) as custom_avg_age FROM people GROUP BY gender").show()
// 如果想在 DSL 中使用
println("--- 使用 DSL 和自定义的 myavg 函数 ---")
val myavg_udaf = new MyAvgUDAF()
// 注意:在DSL中使用时,udaf函数需要从 functions 中导入,而不是 session.udf
df.agg(myavg_udaf($"age").as("custom_avg_age_dsl")).show()
df.groupBy("gender").agg(myavg_udaf($"age").as("custom_avg_age_dsl")).show()
session.stop()
}
}
/**
* 新版 Spark 中,不能直接用 Aggregator 注册 SQL 函数,必须改写为 UserDefinedAggregateFunction
* 否则只能用于 DSL 中。
*/
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
/**
* 自定义 UDAF (User-Defined Aggregate Function) 来计算平均值。
* 计算平均值需要维护两个状态:总和 (sum) 和 数量 (count)。
*/
class MyAvgUDAF extends UserDefinedAggregateFunction {
// 1. 输入数据结构:我们聚合的列的数据类型,这里假设是整型。
override def inputSchema: StructType = StructType(StructField("value", IntegerType) :: Nil)
// 2. 聚合缓冲区数据结构:在聚合过程中需要维护的中间状态。
// 我们需要一个 LongType 来存储总和(防止整数溢出),以及一个 LongType 来存储计数。
override def bufferSchema: StructType = StructType(
StructField("sum", LongType) ::
StructField("count", LongType) :: Nil
)
// 3. 函数返回值数据类型:平均值通常是小数,所以使用 DoubleType。
override def dataType: DataType = DoubleType
// 4. 确定性:对于相同的输入,是否总是返回相同的输出。平均值是确定的,所以为 true。
override def deterministic: Boolean = true
// 5. 初始化聚合缓冲区。在处理新分区之前调用。
// 总和和计数都从 0 开始。
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L // 初始化 sum
buffer(1) = 0L // 初始化 count
}
// 6. 更新缓冲区:当有新数据时,如何更新缓冲区。
// 这个方法在每个分区内,每行数据都会调用一次。
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getInt(0) // 累加 sum
buffer(1) = buffer.getLong(1) + 1 // 累加 count
}
}
// 7. 合并缓冲区:如何合并两个分区的聚合结果。
// 将一个分区的 sum 和 count 合并到另一个分区。
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0) // 合并 sum
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1) // 合并 count
}
// 8. 计算最终结果:在所有数据处理完成后,如何通过缓冲区计算最终结果。
override def evaluate(buffer: Row): Any = {
val count = buffer.getLong(1)
if (count == 0) {
// 如果计数为0(例如,输入为空或全为NULL),返回 null 或者 0.0
// 返回 null 更符合 SQL 语义
null
} else {
// 最终结果是 总和 / 数量。必须进行类型转换,否则会是整数除法。
buffer.getLong(0).toDouble / count
}
}
}
udtf
一变多
spark中不能定义拆分函数,但是可以使用hive中的udtf =》 explode
package com.lmk.spark
import org.apache.spark.sql.SparkSession
object Testexplode {
def main(args: Array[String]): Unit = {
val session = new SparkSession.Builder().master("local[*]").appName("Testexplode").getOrCreate()
import session.implicits._
val df = session.sparkContext.textFile("data/m.txt")
.map(x => {
val strs = x.split(",")
(strs(0), strs(1), strs(2))
}).toDF("id", "name", "actors")
df.createTempView("movie")
// '\\|' -> SQL 解析后变成 \| -> 正则表达式引擎将其识别为字面量的 |。 这里需要用\\\\
//session.sql("select explode(split(actors, '\\\\|')) from movie").show()
session.sql("select id, name, actor from movie lateral view explode(split(actors, '\\\\|')) as actor").show()
}
}
LATERAL VIEW介绍
LATERAL VIEW 就像一个虚拟的 JOIN,它能将一个包含数组或 Map 的行“展开”(explode)成多行,然后将这些展开后的新行与原始行的数据“连接”起来。
就像上面的案例。它将原始行 (id=1, title=wjd) 的信息,附加到 explode 生成的每一行上。exploded_table as actor 为这个过程创建了一个包含单列 actor 的临时视图。
| id | title | actor_list | + | (新列 actor) |
|---|---|---|---|---|
| 1 | wjd | ldh|lcw|zzw | ldh | |
| 1 | wjd | ldh|lcw|zzw | lcw | |
| 1 | wjd | ldh|lcw|zzw | zzw |
LATERAL VIEW EXPLODE 允许你在查询时才进行数据的“反范式化”或“扁平化”,直接处理那些存储为数组或字符串的嵌套数据。这在大数据场景下非常灵活和高效,因为它避免了预先进行复杂的数据清洗和转换,可以直接在原始的、半结构化的数据上进行分析。