
RDD编程
首先我们使用spark-shell进行编程。
RDD创建
textFile()
从文件系统加载数据创建RDD
val conf = new SparkConf().setAppName("rddtest").setMaster("lcoal")
val sc: SparkContext = new SparkContext(conf)
val data: RDD[String] = sc.textFile("E:\\tmp\\spark\\input\\f1.txt")parallelize()|markRDD
集合并行化,从一个已经存在的集合上创建RDD、
val arr = Array(1,2,3,4,5)
val data: RDD[Int] = sc.parallelize(arr)
println(data.count()) // 统计RDD元素个数parallelize 和makeRDD是一个算子,makeRDD其实就是parallelize,查看源码可以看到,如下:
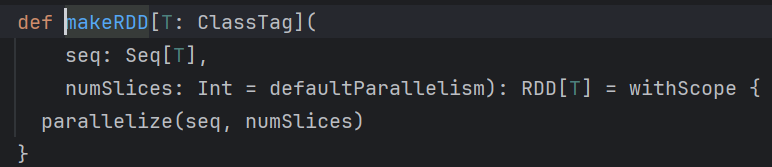
分区个数
RDD默认带有分区的,那么创建完毕rdd以后他的分区数量判定如下:
从hdfs读取文件的方式是最正规的方式,我们通过计算原理可以推出block的个数和分区数量是一致的,本地化计算。
读取文件那么是使用textFile,查看源码如下:
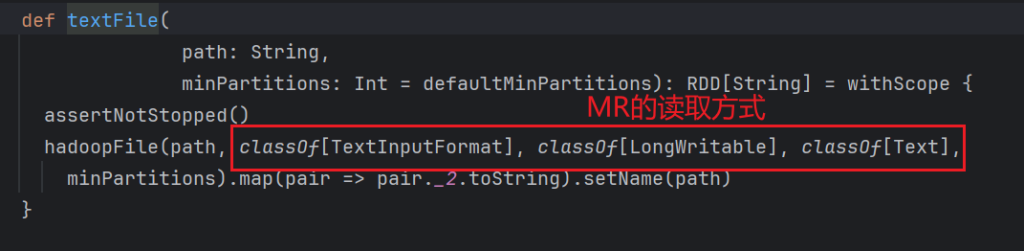
我们可以发现数据的读取使用的是textInputFormat,读取的数据内容是文本
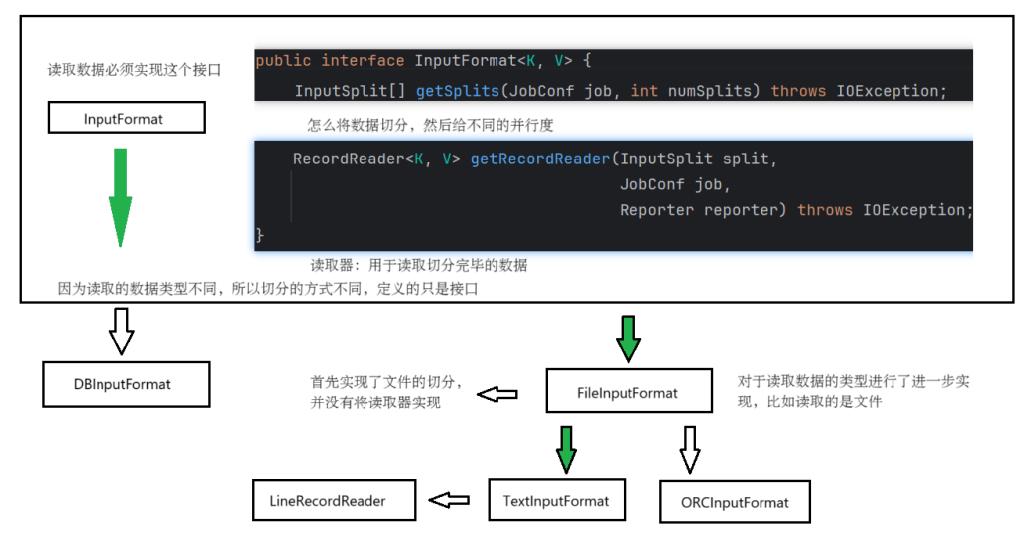
数据结构的实现由上图进行规划。
FileInputFormat中对于文件的切分进行了分割,切分几个部分就可以实现分区的个数。
文件在hdfs存储的文件在spark中的使用是不同的,存储的时候单位是block块 128M。读取的时候是以spark为主,spark的读取大小叫做split切片。
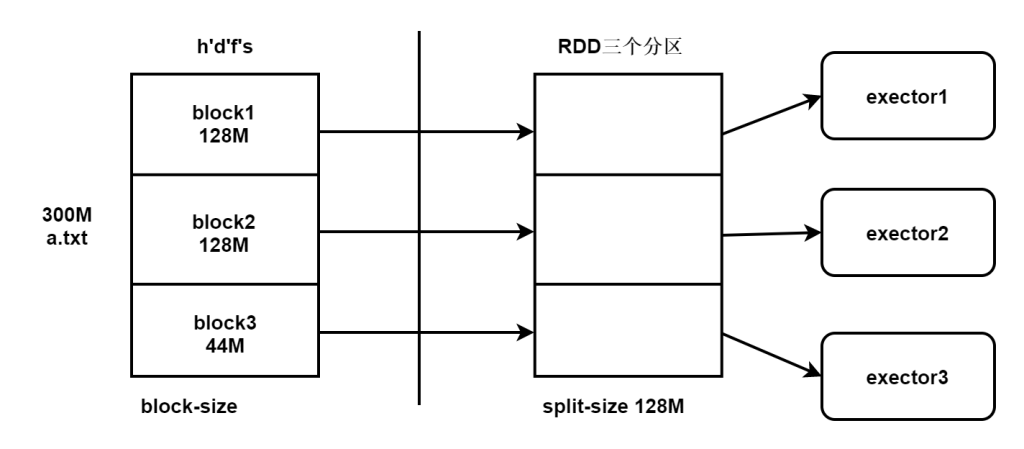
千万要将存储和计算区分开,分区的多少完全看切片是多少,和hdfs的存储无关,但是如果切片大小和block的大小一致的话那么就可以实现本地化计算。
从TextInputFormat中LineRecordReader读取器方法查看源码,可以找到getSplits
split分区的源码解析
具体split分区的源码解析如下:
// 这个方法是切分切片的方法
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
StopWatch sw = new StopWatch().start();
FileStatus[] stats = listStatus(job);
// Save the number of input files for metrics/loadgen
job.setLong(NUM_INPUT_FILES, stats.length);
long totalSize = 0; // compute total size
boolean ignoreDirs = !job.getBoolean(INPUT_DIR_RECURSIVE, false)
&& job.getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
// 获取文件总大小,检查文件类型
List<FileStatus> files = new ArrayList<>(stats.length);
for (FileStatus file: stats) { // check we have valid files
if (file.isDirectory()) {
if (!ignoreDirs) {
throw new IOException("Not a file: "+ file.getPath());
}
} else {
files.add(file);
totalSize += file.getLen();
}
}
// numSplits 期望分区大小,sc.textFile("a.txt", 3(期望分区数量))
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
FileSystem fs = path.getFileSystem(job);
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
// 判断文件是否可以切分
if (isSplitable(fs, path)) {
// 获取blockSize 的大小
long blockSize = file.getBlockSize();
// 通过goalSize, minSize, blockSize计算一个切片的大小
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
// 文件的整体长度
long bytesRemaining = length;
// 每次按照切片生成任务,现在是形成切片
// 如果剩余文件大小与切片大小的比例小于1.1
// 我们就会将文件不再切片,放到一起,节约资源,小文件不再生成一个多余任务
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
// 首先拿整体的大小减去切片大小,形成一块
length-bytesRemaining, splitSize, clusterMap);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
// 比如压缩文件就是不可切分的,如果不可切分就把整个文件当作一个整体输入
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits.toArray(new FileSplit[splits.size()]);
}
// 计算规则是按照三个值进行计算,block大小、期望切片大小取最小值,但是必须大于minSize。
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}案例如下:
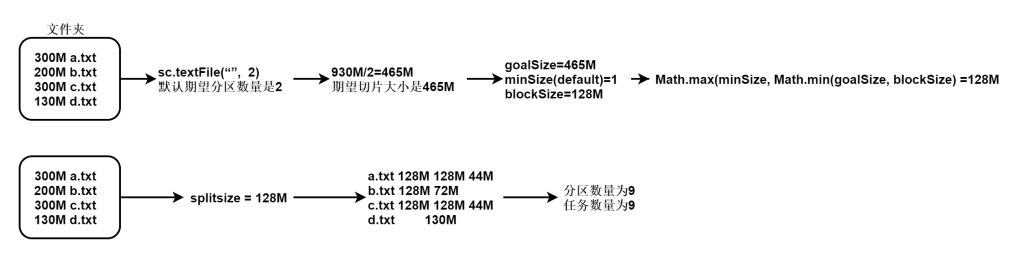
在rdd中查看partition数量的语句如下:
res0.partitions.size在读取hdfs的文件的时候,一般文件都比较大,所以期望分区在不设定的时候默认值是2,切片大小肯定大于128M,那么以128M为主肯定切片和block的数量是一致的。
集合并行化情况
根据集群中的核数进行适配,启动的时候有几个核,产生分区数量就是几个。因为在计算的过程中,我们是为了做测试,为了达到最大的性能,所以分区数量会自己适配。
scala> sc.makeRDD(Array(1,2,3,4,5,6), 10)
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> sc.makeRDD(Array(1,2,3,4,5,6), 100)
res1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:24
scala> res0.partitions.size
res2: Int = 10
scala> res1.partitions.size
res3: Int = 100RDD操作
RDD操作包括两种类型,即转换(Transformation)操作和行动(Action)操作。

对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个操作使用。RDD的转换过程是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,值遇到行动操作时,才会触发“从头到尾”的真正的计算。
常用转换操作
map(func)
将函数应用于RDD中的每个元素,将返回值构成新的RDD。
scala> sc.makeRDD(Array("1 2 3","4 5 6"),2)
res5: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[3] at makeRDD at <console>:24
// 这里实际上不是没有split的,只有在有action算子的时候,才会执行。
scala> res5.map(s => s.split(" "))
res6: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[4] at map at <console>:24
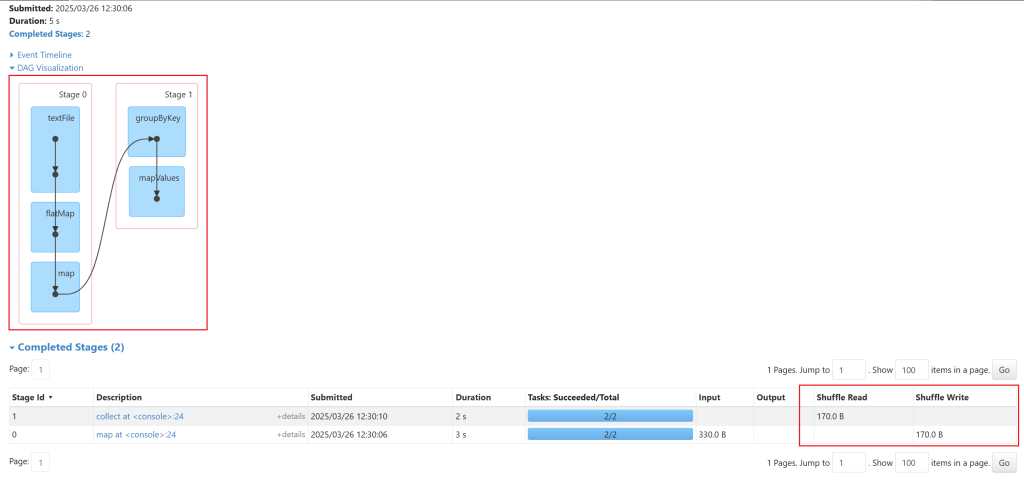
scala> res6.foreach(println)
// 进入WEB UI,查看返回结果
// [Ljava.lang.String;@7fe1314b
// [Ljava.lang.String;@6433946c
还可以查看到对应的DAG图
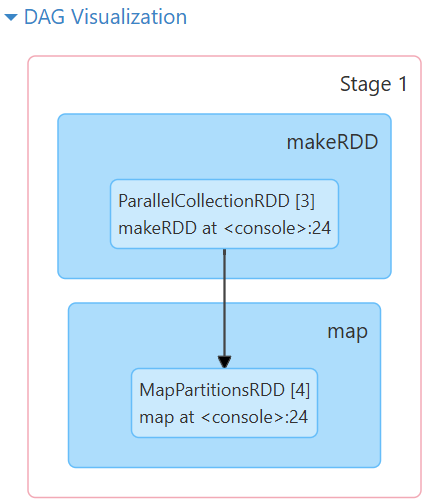
println 作用于 Array[String],它会打印 Array 的默认 toString 格式,而不会逐个打印数组中的元素。因此,会显示这样的输出。
如果希望看到具体的数组内容,可以使用 mkString 来转换数组为字符串。
res6.foreach(arr => println(arr.mkString(",")))
//输出为
//1,2,3
//4,5,6这样查看输出需要每次都打开WEB UI查看,所以可以使用collect()将数据拉回到驱动端,逐行打印数组内容。
res6.collect
// 返回结果
// res9: Array[Array[String]] = Array(Array(1, 2, 3), Array(4, 5, 6))
res6.collect().foreach(arr => println(arr.mkString(",")))
// 返回结果
// 1,2,3
// 4,5,6小心使用collect,收集回来的数据在driver,rdd是分布式的,但是driver都是放入到内存中,这个数据会造成内存溢出的问题,数据比较小的测试的内容可以收集回来。
flatMap(func)
将函数应用于RDD中的每个元素,将返回的迭代器的所有内容构成新的RDD 执行过程:map—> flat(拍扁)。
案例1
scala> val arr = Array("hello tom", "hello jack hello world", "tom world")
arr: Array[String] = Array(hello tom, hello jack hello world, tom world)
scala> sc.makeRDD(arr)
res10: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[5] at makeRDD at <console>:25
scala> res10.flatMap(_.split(" "))
res11: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at flatMap at <console>:24
scala> res11.collect
res12: Array[String] = Array(hello, tom, hello, jack, hello, world, tom, world)案例2
scala> val arr = Array("zhangsan 100 90 80 70", "lisi 60 50 40")
arr: Array[String] = Array(zhangsan 100 90 80 70, lisi 60 50 40)
scala> sc.makeRDD(arr)
res4: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[1] at makeRDD at <console>:25
scala> res2.flatMap(x => {
| val arr = x.split(" ")
| arr.tail.map((arr.head, _))
| })
res5: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[2] at flatMap at <console>:25
scala> res5.collect
[Stage 0:> (0 + 6) / 6[Stage 0:=======================================> (4 + 2) / 6 res6: Array[(String, String)] = Array((zhangsan,100), (zhangsan,90), (zhangsan,80), (zhangsan,70), (lisi,60), (lisi,50), (lisi,40))filter(func)
返回一个由通过func函数测试(返回true)的元素组成的RDD。
scala> val arr = Array(1,2,3,4,5,6,7,8)
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)
scala> sc.makeRDD(arr)
res7: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at makeRDD at <console>:25
scala> res7.filter(_>3)
res8: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at filter at <console>:24
scala> res8.collect
res9: Array[Int] = Array(4, 5, 6, 7, 8)
// 元素没了,分区还在,默认就是全部核数,spark-shell指定了六个核,所以六个分区
scala> res7.partitions.size
res12: Int = 6
scala> res8.partitions.size
res13: Int = 6分区在创建rdd的时候就已经存在了,rdd上必须存在分区,因为可以在不同的机器上进行并行执行。
在计算过程中,有的时候分区数量可能过少或者过多。比如
- 读取的数据需要进行机器学习计算,一个block里面的128M数据只能给一个任务处理,这个时候需要增加分区。
- 或者filter在过滤数据的时候,将大量的脏数据过滤掉了,大量的分区中,存在数据量很少。任务处理的时候就会浪费资源
当遇到这些情况就需要修改分区的数量。map,flatMap,filter等算子都是简单的管道形式算子,加载到内存中直接执行,不会将数据分发到别的机器,他们没有修改分区的能力。
只有shuffle类的算子能够修改分区的数量。
distinct
对rdd进行去重
scala> val arr = Array(1,1,2,2,2,3,3,3,4,4,5,5,6,6)
arr: Array[Int] = Array(1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 5, 5, 6, 6)
scala> sc.makeRDD(arr)
res14: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at makeRDD at <console>:25
scala> res14.distinct
res15: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[8] at distinct at <console>:24
scala> res15.collect
res16: Array[Int] = Array(6, 1, 2, 3, 4, 5)distinct的底层是通过分组生成的,分组存在shuffle,所以可以修改分区数量。
这个去重也可以通过groupBy来实现,实现的方式如下:
scala> sc.makeRDD(arr)
res17: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at makeRDD at <console>:25
// 6个分区
scala> res17.groupBy(t => t)
res18: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[11] at groupBy at <console>:24
// 6个分区,所以一共12个分区,12个任务
scala> res18.map(_._1).collect
res19: Array[Int] = Array(6, 1, 2, 3, 4, 5)可以看到返回的结果是相同的。
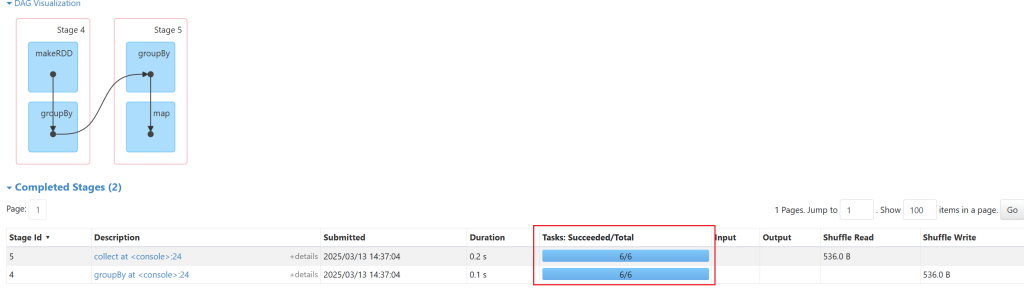
修改分区数量的方式,增加减少都可以:
scala> sc.makeRDD(arr,3)
res21: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[14] at makeRDD at <console>:25
scala> res21.distinct(5)
res22: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[17] at distinct at <console>:24
scala> res22.partitions.size
res23: Int = 5mapPartitions()
先partition,再把每个partition进行map函数。
scala> sc.makeRDD(arr)
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:25
scala> res0.map(_*2)
res1: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:24
scala> res0.map
map mapPartitions mapPartitionsWithEvaluator mapPartitionsWithIndex
scala> res0.map
def map[U](f: Int => U)(implicit evidence$3: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U]
scala> res0.mapPartitions
mapPartitions mapPartitionsWithEvaluator mapPartitionsWithIndex
scala> res0.mapPartitions
def mapPartitions[U](f: Iterator[Int] => Iterator[U],preservesPartitioning: Boolean)(implicit evidence$6: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U]
scala> res0.mapPartitions(it => it.map(_*2))
res3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at mapPartitions at <console>:24
scala> res3.collect
res4: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16)
通过输出可以看出,mapPartitions里面是一个一个的Iterator迭代器,map中是一个一个的元素。每个分区都有Iterator他们是一个整体处理的。
mappartitions和map几乎一样,只不过mapPartitions是一个分区作为一个整体进行处理的。
连接处理的时候需要mapPartitions
案例如下:
- 首先创建data文件夹然后创建order.txt,输入如下内容
- 001,1,2,5,5000
- 002,2,3,6,6000
- 003,3,4,7,7000
- 004,4,5,8,8000
- 其中列含义order_id[订单编号],user_id[用户id],goods_id[商品id],number[数量],price[价格]
- 在数据库中创建一个用户表 user
- id name age
- 1 zhangsan 20
- 2 lisi 30
- 3 wangwu 40
- 4 zhaosi 50
根据order.txt中的订单内容,通过里面的用户id去表中查询用户的名称。
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test mapPartitions")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.textFile("data/order.txt")
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1).toInt,strs(2).toInt,strs(3).toInt,strs(4).toDouble)
//orderId userId goodsId number price
}).map(t=>{
val con = DriverManager.getConnection("jdbc:mysql:/127.0.0.1:3306/lmk","root","rootroot")
val prp = con.prepareStatement("select name from hainiu.user where id = ?")
val userid = t._2
prp.setInt(1,userid)
val result = prp.executeQuery()
var name:String = null
while(result.next()){
name = result.getString("name")
}
prp.close()
con.close()
(t._1,t._2,name,t._3,t._4,t._5)
}).foreach(println)
}
}以上代码不可以这么使用,因为map中一条元素会和mysql创建一个连接,元素在生产环境中,可能达到几千万,mysql是不支持这么大量的链接,并且每次都创建链接性能非常低下。
那么如果我们想要将连接数据库的con 和prp提出来是不可以的,因为如果不在sc和rdd中执行,是在driver本地执行,不上集群的。
connect对象不能提取到公共变量中,executor端想要远程使用driver端的对象是需要序列化的,连接对象是不能序列化的。
优化后的代码如下:
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test mapPartitions")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.textFile("data/order.txt")
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1).toInt,strs(2).toInt,strs(3).toInt,strs(4).toDouble)
//orderId userId goodsId number price
}).mapPartitions(it=>{
val con = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/lmk", "root", "rootroot")
val prp = con.prepareStatement("select name from hainiu.user where id = ?")
val buffer = ListBuffer[(String,Int,String,Int,Int,Double)]()
it.foreach(t=>{
val userid = t._2
prp.setInt(1, userid)
val result = prp.executeQuery()
var name: String = null
while (result.next()) {
name = result.getString("name")
}
buffer.append((t._1, t._2, name, t._3, t._4, t._5))
})
prp.close()
con.close()
buffer.toIterator
}).foreach(println)
}
}使用mapPartitions算子,一个分区创建一个连接,连接数量减少,并且不涉及到序列化问题。
mapPartitionsWithIndex
这个算子中存在两个参数的分别是分区下标和分区中整体的元素。
scala> val arr=Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> sc.makeRDD(arr, 3)
res1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:25
scala> res1.mapPartitionsWithIndex
// Int是分区下标,Iterator[Int]是分区元素
def mapPartitionsWithIndex[U](f: (Int, Iterator[Int]) => Iterator[U],preservesPartitioning: Boolean)(implicit evidence$9: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U]
scala> res1.mapPartitionsWithIndex((index,it)=> {
| it.map((_,index))
| })
res4: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[2] at mapPartitionsWithIndex at <console>:24
// 输出的就是分区和下标的映射关系
scala> res4.collect
res5: Array[(Int, Int)] = Array((1,0), (2,0), (3,0), (4,1), (5,1), (6,1), (7,2), (8,2), (9,2))
// 如果先进行过滤,再查看分区的情况
scala> res1.filter(_>3)
res8: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at filter at <console>:24
scala> res8.mapPartitionsWithIndex((index, it) => {
| it.map((_, index))
| })
res9: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[4] at mapPartitionsWithIndex at <console>:24
// 可以发现,0号分区还在,只是没有数据了,不然就没有2号分区
scala> res9.collect
res10: Array[(Int, Int)] = Array((4,1), (5,1), (6,1), (7,2), (8,2), (9,2))之前使用的算子saveAsTextFile,保存数据的算子,会将结果数据存储到hdfs的目录中。
案例:使用mapPartitionsWithIndex写出数据到hdfs中。
package com.lmk.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SparkConf, SparkContext}
import java.io.PrintWriter
object TextMapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("sink")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val arr = Array(1,2,3,4,5,6,7,8,9)
val sink_dir = "data/res"
// rdd中的fs涉及到序列化问题,所以不能使用
val fs1 = FileSystem.get(new Configuration())
if(fs1.exists(new Path(sink_dir)))
throw new Exception("output path already exists ")
else
fs1.mkdirs(new Path(sink_dir))
fs1.close()
sc.makeRDD(arr, 3).mapPartitionsWithIndex((index, it) => {
val fs = FileSystem.get(new Configuration())
val out = fs.create(new Path(sink_dir+"/part-0000"+index))
val pw = new PrintWriter(out, true)
it.foreach(line => pw.println(line))
pw.close()
out.close()
fs.close()
Iterator.empty
}).foreach((t:String)=>{})
}
}键值对(key, value)RDD操作
键值对RDD(pair RDD)是指每个RDD元素都是(key, value)键值对类型。
| 函数 | 目的 |
|---|---|
reduceByKey(func) | 合并具有相同键的值,RDD[(K,V)] => RDD[(K,V)]按照key进行分组,并通过func 进行合并计算 |
groupByKey() | 对具有相同键的值进行分组,RDD[(K,V)] => RDD[(K, Iterable)]只按照key进行分组,不对value合并计算 |
mapValues(func) | 对 PairRDD中的每个值应用一个函数,但不改变键不会对值进行合并计算 |
flatMapValues(func) | 对PairRDD 中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录 |
keys() | 返回一个仅包含键的 RDD,RDD[(K,V)] => RDD[K]返回键不去重 |
values() | 返回一个仅包含值的 RDD,RDD[(K,V)] => RDD[V] |
sortByKey() | 返回一个根据键排序的 RDD,默认是升序false:降序 |
subtractByKey(other) | 删掉RDD中键与other RDD中的键相同的元素 |
cogroup | 将两个RDD中拥有相同键的数据分组到一起,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (Iterable,Iterable))] |
join(other) | 对两个RDD进行内连接,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (V, W))]相当于MySQL 的 innerjoin |
rightOuterJoin | 对两个RDD进行右连接,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (Option[V], W))]相当于MySQL 的 rightjoin |
leftOuterJoin | 对两个RDD进行左连接,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (V, Option[W]))]相当于MySQL 的 leftjoin |
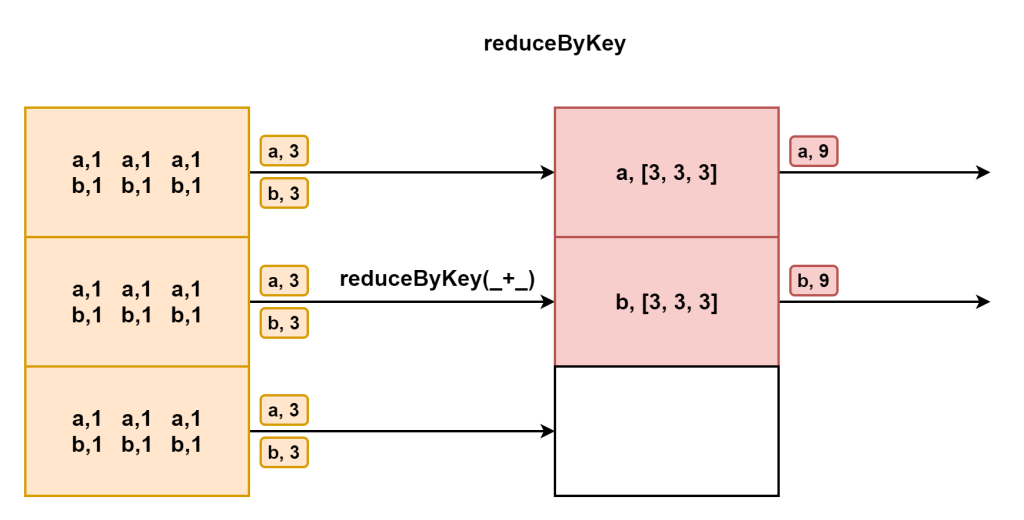
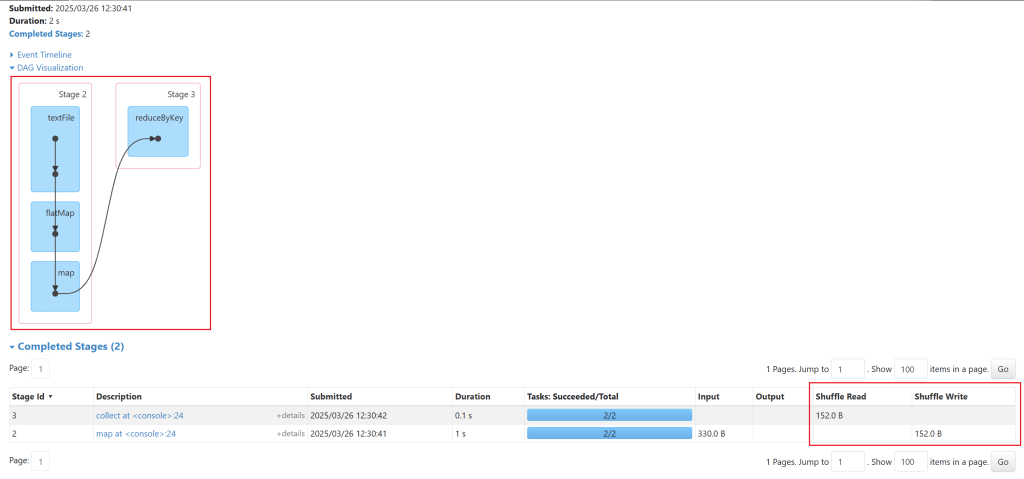
reduceByKey(func)
按照key进行合并,不仅仅能够分组还能够合并。因为有分组聚合,shuffle类算子可以修改分区数量。
scala> sc.textFile("/test/a.txt")
res15: org.apache.spark.rdd.RDD[String] = /test/a.txt MapPartitionsRDD[13] at textFile at <console>:24
scala> res15.flatMap(_.split(" "))
res16: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[14] at flatMap at <console>:24
scala> res16.map((_, 1))
res17: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[15] at map at <console>:24
// 对key进行聚合,每次拿两个value进行操作。
// res17.reduceByKey(_+_, 4) 可以修改分区数量
scala> res17.reduceByKey(_+_)
res18: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[16] at reduceByKey at <console>:24
scala> res18.collect
res19: Array[(String, Int)] = Array((tom,10), (hello,20), (wrold,10))reduceByKey实现distinct功能
scala> val arr = Array(1,1,2,2,3,3,4,4,5,5,6,6)
arr: Array[Int] = Array(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6)
scala> sc.makeRDD(arr)
res20: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[17] at makeRDD at <console>:25
scala> res20.map((_, null))
res21: org.apache.spark.rdd.RDD[(Int, Null)] = MapPartitionsRDD[18] at map at <console>:24
scala> res21.reduceByKey((a, b) => a)
res22: org.apache.spark.rdd.RDD[(Int, Null)] = ShuffledRDD[19] at reduceByKey at <console>:24
scala> res22.map(_._1)
res23: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[20] at map at <console>:24
scala> res23.collect
res24: Array[Int] = Array(6, 1, 2, 3, 4, 5)其实distinct也是使用reduceByKey实现的,源码如下:
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
def removeDuplicatesInPartition(partition: Iterator[T]): Iterator[T] = {
// Create an instance of external append only map which ignores values.
val map = new ExternalAppendOnlyMap[T, Null, Null](
createCombiner = _ => null,
mergeValue = (a, b) => a,
mergeCombiners = (a, b) => a)
map.insertAll(partition.map(_ -> null))
map.iterator.map(_._1)
}
partitioner match {
case Some(_) if numPartitions == partitions.length =>
mapPartitions(removeDuplicatesInPartition, preservesPartitioning = true)
case _ => map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
}
}groupByKey()
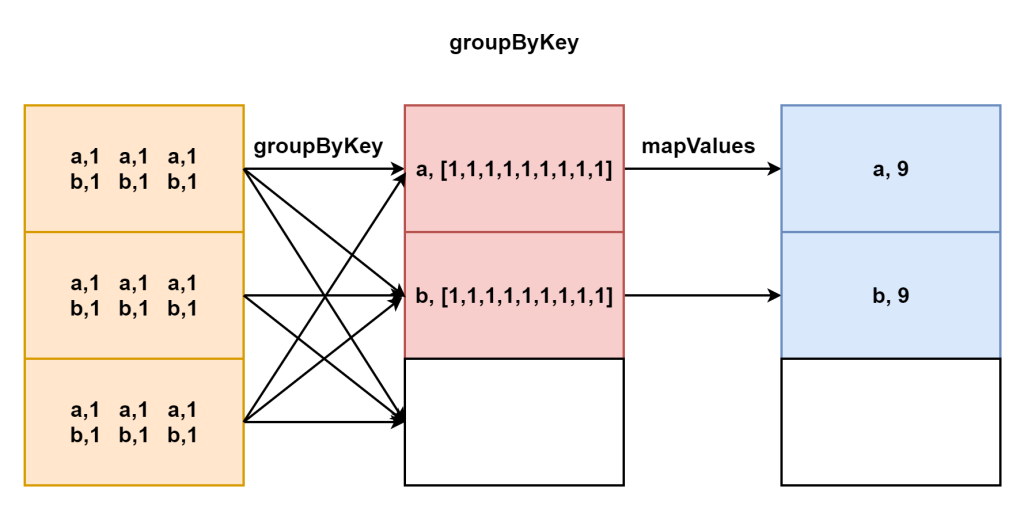
它和groupBy相比返回值 RDD[k,Iterable[v]],因为它也是shuffle类算子可以修改分区数量。
scala> sc.textFile("/test/a.txt")
res0: org.apache.spark.rdd.RDD[String] = /test/a.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> res0.flatMap(_.sp)
span split splitAt
scala> res0.flatMap(_.split(" "))
res1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:24
scala> res1.map((_, 1))
res2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:24
scala> res2.groupBy(_._1)
res4: org.apache.spark.rdd.RDD[(String, Iterable[(String, Int)])] = ShuffledRDD[5] at groupBy at <console>:24
-- 上面返回Iterable[(String, Int)])类型,不好处理,所以换一个返回int类型的
-- groupByKey必须使用(k,v)类型的数据,res2.groupByKey(2)修改分区数量
scala> res2.groupByKey()
res6: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[6] at groupByKey at <console>:24
scala> res6.mapValues(_.sum)
res7: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[7] at mapValues at <console>:24
scala> res7.collect
res8: Array[(String, Int)] = Array((tom,10), (hello,20), (wrold,10))
groupBykey也可以实现distinct去重
scala> val arr = Array(1,1,2,2,3,3,4,4,5,5,6,6)
arr: Array[Int] = Array(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6)
scala> sc.makeRDD(arr)
res9: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at makeRDD at <console>:25
scala> res9.map((_,null))
res10: org.apache.spark.rdd.RDD[(Int, Null)] = MapPartitionsRDD[9] at map at <console>:24
scala> res10.groupByKey()
res12: org.apache.spark.rdd.RDD[(Int, Iterable[Null])] = ShuffledRDD[10] at groupByKey at <console>:24
scala> res12.map(_._1)
res13: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[11] at map at <console>:24
scala> res13.collect
res14: Array[Int] = Array(6, 1, 2, 3, 4, 5)reduceByKey(func)与groupByKey()的区别
公共源码如下:
def combineByKeyWithClassTag[C](
// 初始值
createCombiner: V => C,
// 分区内算法,rdd中带有分区,首先使用mergeValue对分区内数据进行的聚合
mergeValue: (C, V) => C,
// 分区间算法,然后对分区间的数据聚合
mergeCombiners: (C, C) => C,
// 拉取数据用的partitioner
partitioner: Partitioner,
// map端进行单独聚合,map端写入数据前是否进行combiner操作
mapSideCombine: Boolean = true,
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {
if (mapSideCombine) {
throw SparkCoreErrors.cannotUseMapSideCombiningWithArrayKeyError()
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw SparkCoreErrors.hashPartitionerCannotPartitionArrayKeyError()
}
}
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}groupByKey源码如下:
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
// 只是将按照key作一个归类,不对value进行操作
// 分区内算法是把每个元素加入到ListBuffer里面,数据会越来越多
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
// map端(上游)不combiner,reduce端(下游)拉取的数据量大
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}reduceByKey源码如下:
与上面的groupByKey相比,空间使用小了。
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
// 两个func 分前后为分区内算法和分区间算法
// map端(上游)有combiner,reduce端(下游)拉取的数据量小
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}groupByKey和reduceByKey使用案例
需求:首先求出整个文档中访问量最高的前三个,每个专业中访问量最高的前两个
数据准备,内容大致如下:
http://hive.lmkspaceol.cn/lmk
http://hive.lmkspaceol.cn/lmk
http://hive.lmkspaceol.cn/lmk
http://hive.lmkspaceol.cn/lmk
http://hive.lmkspaceol.cn/lmk
http://hive.lmkspaceol.cn/l
http://hive.lmkspaceol.cn/l
http://hive.lmkspaceol.cn/l
http://hive.lmkspaceol.cn/l
http://hive.lmkspaceol.cn/lm
http://hive.lmkspaceol.cn/l
http://spark.lmkspaceol.cn/l
http://spark.lmkspaceol.cn/l整个文档中访问量最高的前三个代码如下:
package com.lmk.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import java.net.URL
object GroupTest {
def main(args: Array[String]): Unit = {
//val url = new URL("http://hive.lmkspaceol.cn/lmk")
//println(url.getHost.split("\\.")(0))
// hive.lmkspaceol.cn \\是正则的转义
//println(url.getPath.substring(1))
// /lmk
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("grouptest")
val sc = new SparkContext(conf)
val userVisit:RDD[((String, String), Int)] = sc.textFile("data/grouptest.txt")
.map(t => {
val url = new URL(t)
val subject = url.getHost.split("\\.")(0)
val user = url.getPath.substring(1)
((subject, user), 1)
}).reduceByKey(_+_)
// 不加- 是正序
userVisit.sortBy(-_._2)
.take(3)
.foreach(println)
}
}返回结果为
((zookeeper,lmk),6)
((hive,l),5)
((hdfs,lm),5)每个专业中访问量最高的前两个代码如下
// 不加- 是正序
// userVisit.sortBy(-_._2)
// .take(3)
// .foreach(println)
// (String, String), Int) 变成了 (String, (String, Int))
userVisit.map(x => (x._1._1, (x._1._2, x._2)))
// (String, Iterable[(String, Int)])
.groupByKey()
// (String, List[(String, Int)]) take取几个
.map(x => (x._1, x._2.toList.sortBy(-_._2).take(2)))
.foreach(println)输出结果为:
(spark,List((lmk,4), (lm,4)))
(hive,List((l,5), (lmk,5)))
(hdfs,List((lm,5)))
(zookeeper,List((lmk,6), (l,4)))keys
只获取key的值
scala> sc.makeRDD(List((1, "zs"), (2, "ls"), (3, "ww")))
res11: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[2] at makeRDD at <console>:24
scala> res11.keys
res12: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at keys at <console>:24
scala> res12.collect
res13: Array[Int] = Array(1, 2, 3)当然,使用map获取也可以
scala> res11.map(_._1)
res19: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at map at <console>:24
scala> res19.collect
res20: Array[Int] = Array(1, 2, 3)values
只获取value的值,同样也可以使用map获取。
scala> res11.values
res23: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[5] at values at <console>:24
scala> res23.collect
res24: Array[String] = Array(zs, ls, ww)mapValues(func)
处理map中value的值。
scala> val arr = Array(("zs", 3000), ("ls", 4000), ("ww", 5000))
arr: Array[(String, Int)] = Array((zs,3000), (ls,4000), (ww,5000))
scala> sc.makeRDD(arr)
res25: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[6] at makeRDD at <console>:25
scala> res25.mapValues(_+1000)
res26: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[7] at mapValues at <console>:24
scala> res26.collect
res27: Array[(String, Int)] = Array((zs,4000), (ls,5000), (ww,6000))flatMapValues(func)
只对value压平,前提要是kv格式,key直接保留。flatMapValues中放入的函数功能是怎么处理value变成集合形式。
scala> val arr = Array(("zs", Array(100, 93, 90)), ("ls", Array(23, 44, 94, 28)))
arr: Array[(String, Array[Int])] = Array((zs,Array(100, 93, 90)), (ls,Array(23, 44, 94, 28)))
scala> sc.makeRDD(arr)
res33: org.apache.spark.rdd.RDD[(String, Array[Int])] = ParallelCollectionRDD[10] at makeRDD at <console>:25
// 内部的公式是拿到_2,也就是数组,然后对数组进行map操作
scala> res33.flatMap(x => x._2.map((x._1, _)))
res34: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[11] at flatMap at <console>:24
scala> res34.collect
res35: Array[(String, Int)] = Array((zs,100), (zs,93), (zs,90), (ls,23), (ls,44), (ls,94), (ls,28))
// 必须写一个公式,就是直接把值落下来
scala> res33.flatMapValues(t => t)
res36: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[12] at flatMapValues at <console>:24
scala> res36.collect
res37: Array[(String, Int)] = Array((zs,100), (zs,93), (zs,90), (ls,23), (ls,44), (ls,94), (ls,28))案例2
scala> val arr = Array(("zs", "100, 23, 44"), ("ls", "83, 94, 23"))
arr: Array[(String, String)] = Array((zs,100, 23, 44), (ls,83, 94, 23))
scala> sc.makeRDD(arr)
res38: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[13] at makeRDD at <console>:25
// 因为这里就是对values操作,所以_代表的就是value,对split后的value进行压平就是结果值了。
scala> res38.flatMapValues(_.split(", "))
res41: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[15] at flatMapValues at <console>:24
scala> res41.collect
res42: Array[(String, String)] = Array((zs,100), (zs,23), (zs,44), (ls,83), (ls,94), (ls,23))flatMap使用案例
数据准备
chinese-zs,ls,ww
math-zs,zs
english-ls,ww,zl要求:获取每个老师对应的课程都是什么
分析,得到的结果类似 zs-chinese,math 。其实有点类似wordcount,还是一个对学科的聚合操作。
- 首先进行反推,通过结果zs-chinese,math。上一步数据为(zs,chinese),(zs,math)
- 通过reduceByKey(_+_)进行合并得出
代码如下:
package com.lmk.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object FlatMapTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("flatMapTest")
val sc = new SparkContext(conf)
val arr = Array("chinese-zs,ls,ww", "math-zs,zs", "english-ls,ww,zl")
val rdd:RDD[String] = sc.makeRDD(arr)
rdd.map(x => {
val strs = x.split("-")
(strs(0), strs(1))
}).flatMapValues(_.split(","))
// .swap翻转
.map(_.swap)
.reduceByKey(_+","+_)
.foreach(a=>println(a._1, a._2))
}
}
输出结果如下:
(zs,chinese,math,math)
(ww,chinese,english)
(ls,chinese,english)
(zl,english)sortByKey()
按照key进行排序,默认是升序,在参数中添加false就是倒序。
scala> sc.textFile("/test/a.txt").flatMap(_.split(" ")).map((_, 1))
res0: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:24
scala> res0.reduceByKey(_+_)
res1: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:24
scala> res1.collect
res2: Array[(String, Int)] = Array((tom,10), (hello,20), (wrold,10))
scala> res1.sortByKey()
res3: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[7] at sortByKey at <console>:24
scala> res3.collect
res4: Array[(String, Int)] = Array((hello,20), (tom,10), (wrold,10))
// 进行降序排序,并且修改分区数量(因为打乱排序,有shuffle操作)
scala> res1.sortByKey(false,3)
res5: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[10] at sortByKey at <console>:24
scala> res5.collect
res6: Array[(String, Int)] = Array((wrold,10), (tom,10), (hello,20))
// 按照values排序,反转,或者用下面的方式获取
scala> res1.map(x => (x._2, x)).sortByKey().values
res7: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[15] at values at <console>:24
scala> res7.collect
res8: Array[(String, Int)] = Array((tom,10), (wrold,10), (hello,20))sortBy()
scala> res1.sortBy(-_._2)
res10: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[20] at sortBy at <console>:24
scala> res10.collect
res11: Array[(String, Int)] = Array((hello,20), (tom,10), (wrold,10))
scala> res1.sortBy
sortBy sortByKey
scala> res1.sortBy(-_._2,false,4)
// 可以有三个参数,第二个与上面一样,写上false就是倒序,-和倒序一起,就是正序。最后一个是修改分区数量。
def sortBy[K](f: ((String, Int)) => K,ascending: Boolean,numPartitions: Int)(implicit ord: Ordering[K],implicit ctag: scala.reflect.ClassTag[K]): org.apache.spark.rdd.RDD[(String, Int)]
其实sortBy并不存在,是调用的sortByKey()。groupBy也一样,groupby底层是groupBykey。查看sortBy底层代码如下:
/**
* Return this RDD sorted by the given key function.
*/
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {
// 首先使用KeyBy,将这个指定的K变成key进行排序
this.keyBy[K](f)
// 这里其实调用的是sortByKey
.sortByKey(ascending, numPartitions)
//最后只保留values
.values
}
/**
* Creates tuples of the elements in this RDD by applying `f`.
*/
def keyBy[K](f: T => K): RDD[(K, T)] = withScope {
val cleanedF = sc.clean(f)
// 例如对(hello,3),(world,2),使用_._2排序。先变成(3,(hello,3)),(2,(world,2))
map(x => (cleanedF(x), x))
}join()
也就是innerjoin。按照key进行关联,只保留能关联上的数据。
scala> val arr = Array(("zs",300),("ls",400),("ww",500),("zl", 600))
arr: Array[(String, Int)] = Array((zs,300), (ls,400), (ww,500), (zl,600))
scala> val arr2 = Array(("zs",22),("ls",39),("ww",42),("ss",4))
arr2: Array[(String, Int)] = Array((zs,22), (ls,39), (ww,42), (ss,4))
scala> sc.makeRDD(arr)
res16: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[26] at makeRDD at <console>:25
scala> sc.makeRDD(arr2)
res17: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[27] at makeRDD at <console>:25
scala> res16 join res17
res18: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[30] at join at <console>:25
scala> res18.collect
res19: Array[(String, (Int, Int))] = Array((ls,(400,39)), (zs,(300,22)), (ww,(500,42)))
// 进行薪资计算
scala> res18.mapValues(x => x._1*x._2)
res20: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[31] at mapValues at <console>:24
scala> res20.collect
res21: Array[(String, Int)] = Array((ls,15600), (zs,6600), (ww,21000))leftOuterJoin
与left join类似,保留左边主表的所有信息,按照key补全右边表的信息。
// Option[Int]就代表可能存在空值
scala> res16 leftOuterJoin res17
res23: org.apache.spark.rdd.RDD[(String, (Int, Option[Int]))] = MapPartitionsRDD[34] at leftOuterJoin at <console>:25
scala> res23.collect
res24: Array[(String, (Int, Option[Int]))] = Array((ls,(400,Some(39))), (zl,(600,None)), (zs,(300,Some(22))), (ww,(500,Some(42))))
// getOrElse(0)有值拿出来,没有值就是0
scala> res23.mapValues(x => x._1*x._2.getOrElse(0))
res25: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[35] at mapValues at <console>:24
scala> res25.collect
res26: Array[(String, Int)] = Array((ls,15600), (zl,0), (zs,6600), (ww,21000))rightOuterJoin()
与right join类似,与上面相同,只不过主表不一样,不多介绍了。需要注意,不同的是返回类型。
cogroup()
全外连接,与full join类似。
scala> val arr = Array(("zs",300),("ls",400),("ww",500),("zl", 600))
arr: Array[(String, Int)] = Array((zs,300), (ls,400), (ww,500), (zl,600))
scala> val arr2 = Array(("zs",22),("ls",39),("ww",42),("ss",4))
arr2: Array[(String, Int)] = Array((zs,22), (ls,39), (ww,42), (ss,4))
scala> sc.makeRDD(arr)
res0: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at makeRDD at <console>:25
scala> sc.makeRDD(arr2)
res1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[1] at makeRDD at <console>:25
// 注意这里的返回类型是Iterable,因为是外连接,所以除去关联字段的其他字段都有可能是多个,所以这里返回的类型是一个集合。
scala> res0 cogroup res1
res2: org.apache.spark.rdd.RDD[(String, (Iterable[Int], Iterable[Int]))] = MapPartitionsRDD[3] at cogroup at <console>:25
scala> res2.collect
res3: Array[(String, (Iterable[Int], Iterable[Int]))] = Array((ls,(CompactBuffer(400),CompactBuffer(39))), (ss,(CompactBuffer(),CompactBuffer(4))), (zl,(CompactBuffer(600),CompactBuffer())), (zs,(CompactBuffer(300),CompactBuffer(22))), (ww,(CompactBuffer(500),CompactBuffer(42))))
// 因为value的类型不同,所以处理的方式也有所改变
scala> res2.mapValues(x => x._1.sum * x._2.sum)
res5: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[4] at mapValues at <console>:24
scala> res5.collect
res6: Array[(String, Int)] = Array((ls,15600), (ss,0), (zl,0), (zs,6600), (ww,21000))
rdd上的分区器
groupBy、groupByKey、reduceByKey、sortBy、sortByKey、join[cogroup、left、inner、right]在使用他们的时候都存在shuffle操作。
shuffle的过程是因为数据产生了打乱重分,分组、排序、join等算子需要将数据重新排版。
shuffle的过程是将上游的数据处理完毕写入到自己的磁盘上,然后下游的数据从磁盘上拉取。
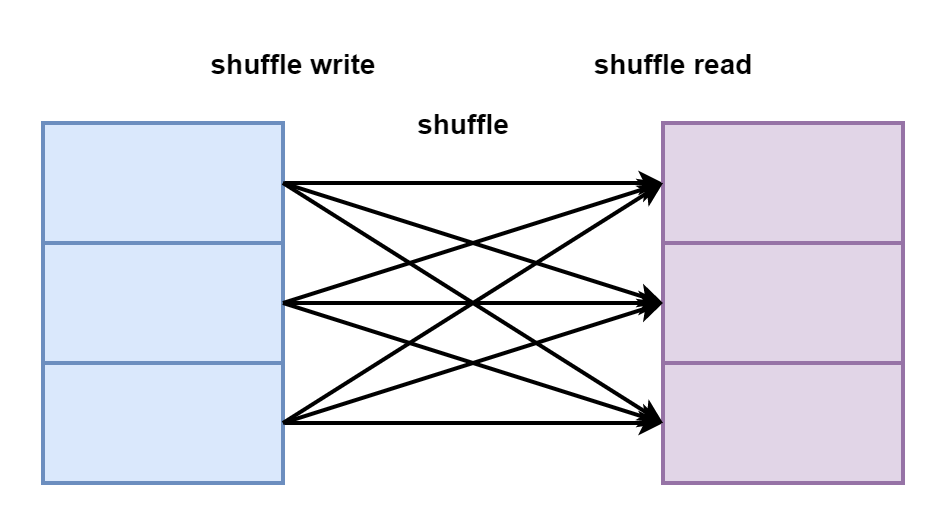
重新排版,打乱重分是需要存在规则的。中间数据流向规则叫分区器partitioner,一般存在于shuffle类算子中。
分区器也可以单独存在,人为定义分发的规则。
分组类算子 groupBy、groupByKey、reduceByKey自带的分区器为HashPartitioner


排序类算子sortBy、sortByKey自带的分区器为rangePartitioner
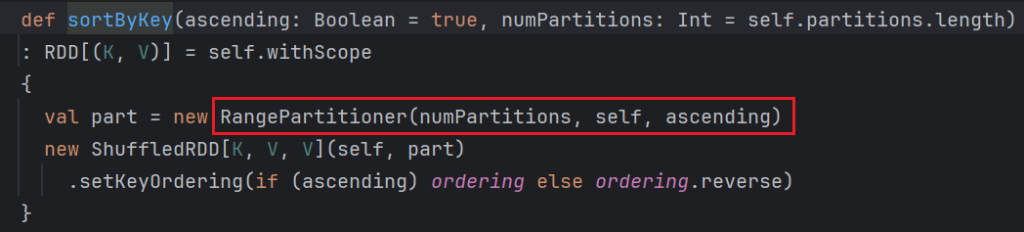
HashPartitioner
规则:按照key的hashCode%下游的分区数量 = 分区编号

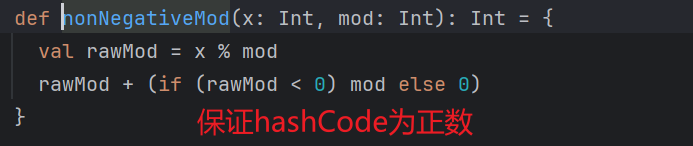
hash取余的方式,不管数据分发到下游的什么分区中,最终结果都是相同数据分发到一起
scala> val arr = Array(1,2,3,4,5,6,7,8,9)
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> sc.makeRDD(arr)
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:25
scala> res0.mapPartitionsWithIndex((index, x) => x.map((index,_)))
res1: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[1] at mapPartitionsWithIndex at <console>:24
scala> res1.collect
res2: Array[(Int, Int)] = Array((0,1), (1,2), (1,3), (2,4), (3,5), (3,6), (4,7), (5,8), (5,9))
scala> res0.map(x => (x, x))
res3: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[2] at map at <console>:24
// 现在是没有分区器的
scala> res0.partitioner
res4: Option[org.apache.spark.Partitioner] = None
// 这里有6个分区
scala> res3.reduceByKey(_+_)
res5: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[3] at reduceByKey at <console>:24
// 现在已经有Hash分区器了
scala> res5.partitioner
res6: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@6)
scala> res5.mapPartitionsWithIndex((index,x) => x.map((index, _)))
res8: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[4] at mapPartitionsWithIndex at <console>:24
scala> res8.collect
res9: Array[(Int, (Int, Int))] = Array((0,(6,6)), (1,(1,1)), (1,(7,7)), (2,(8,8)), (2,(2,2)), (3,(3,3)), (3,(9,9)), (4,(4,4)), (5,(5,5)))例如案例中,就是按照Key.hashcode进行分区,int类型的hashcode就是自己本身。
Hash分区器的规则致使我们可以任意修改下游的分区数量,入下面的代码:
scala> res3.reduceByKey(_+_, 20)
res10: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[5] at reduceByKey at <console>:24
scala> res10.partitions.size
res12: Int = 20
scala> res3.reduceByKey(_+_, 2)
res13: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[6] at reduceByKey at <console>:24
scala> res13.partitions.size
res14: Int = 2rangePartitioner
hashPartitioner规则非常简单,直接规定一个数据按照hashcode规则进行分配,但是可能会出现数据倾斜问题。
range分区规则种存在两个方法
1. rangeBounds
界限,在使用这个分区器之前,先做一个界限划定

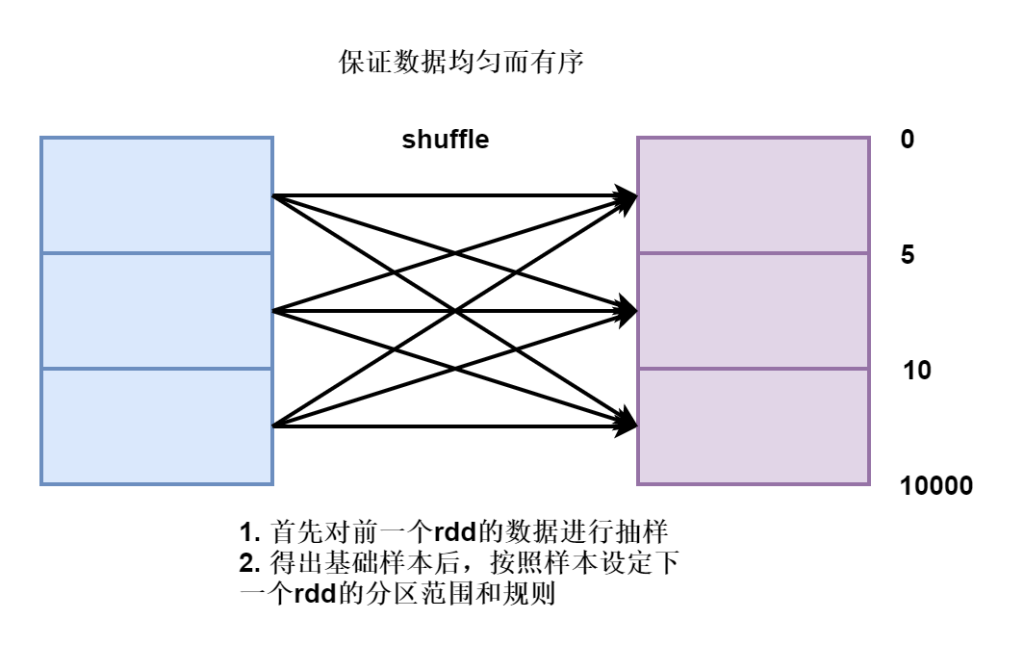
首先使用水塘抽样算法,在未知的数据集中抽取能够代表整个数据集的样本,根据样本进行规则设定。
2. getPartitions
上面完成后再使用getPartitions的方法,获取对应partitions
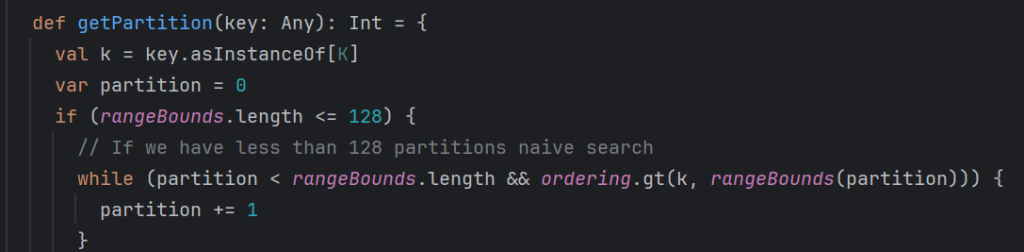
首先进行水塘抽样,规定数据的流向后再执行整体逻辑,会先触发计算
scala> sc.textFile("/test/a.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
res17: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[11] at reduceByKey at <console>:24
scala> res17.sortByKey()
res18: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[14] at sortByKey at <console>:24
原本转换类的算子是不触发计算的,只有行动类算子才会触发计算,但是发现还是触发计算(部分)了。因为计算之前先进行水塘抽样,能够规定下游数据规则,再进行数据的计算。
scala> val arr = Array(1,9,3,4,5,7,2,6,8)
arr: Array[Int] = Array(1, 9, 3, 4, 5, 7, 2, 6, 8)
scala> sc.makeRDD(arr, 3)
res19: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[15] at makeRDD at <console>:25
scala> res19.sortBy(x => x)
res20: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[20] at sortBy at <console>:24
// 这里没有分区器,是因为之前说过,sortBy是通过sortByKey实现的,但是由于一开始map拼上key,后面又map将key去掉,所有最后不带分区器了。
scala> res20.partitioner
res21: Option[org.apache.spark.Partitioner] = None
scala> res19.map(t => (t, t))
res23: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[21] at map at <console>:24
scala> res23.sortByKey()
res24: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[24] at sortByKey at <console>:24
scala> res24.partitioner
res25: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.RangePartitioner@852b)
scala> res26.mapPartitionsWithIndex((index, it)=>it.map((index,_)))
res28: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[28] at mapPartitionsWithIndex at <console>:24
// 可以看到分布很均匀
scala> res28.collect
res30: Array[(Int, (Int, Int))] = Array((0,(1,1)), (0,(2,2)), (0,(3,3)), (0,(4,4)), (0,(5,5)), (1,(6,6)), (1,(7,7)), (1,(8,8)), (1,(9,9)))range分区器,是先做抽样,然后指定下游的数据界限。可以修改分区数量,但是分区数量不能大于元素个数,必须保证每个分区中都有元素。
scala> res24.sortByKey(true, 20)
res31: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[31] at sortByKey at <console>:24
// 可以看到分区数量还是9
scala> res31.partitions.size
res32: Int = 9自定义分区器
工作中,还可能会遇到数据分类的情况,想要根据自己的需求定义分区的规则,让符合规则的数据发送到不同的分区中,这时候就需要自定义分区器了。
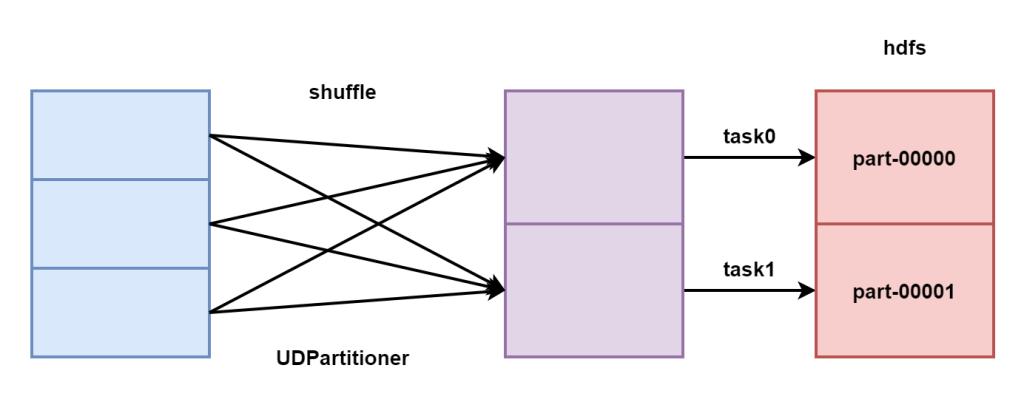
案例需求如下
- 将wordcount练习的数据按照规定规则分发到不同分区中
- hello放到一个分区中,其他分到另一个分区中
定义分区器,让数据发送到不同的分区,从而不同的task任务输出的文件结果也不同。
分区器的定义需要实现分区器的接口
class MyPartitioner extends Partitioner{
// 定义下游存在几个分区
override def numPartitions: Int = ???
// 按照key设定分区位置
override def getPartition(key: Any): Int = ???
}代码实现如下:
package com.lmk.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
object WordCountForPartitioner {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("WordCountForPartitioner")
val sc = new SparkContext(conf)
// stage1
val rdd = sc.textFile("data/a.txt")
.flatMap(_.split(" "))
.map((_, 1))
// stage2
.reduceByKey(_+_)
// stage3
val rdd2 = rdd.partitionBy(new MyPartitioner)
val fs = FileSystem.get(new Configuration())
val out = "data/res"
if (fs.exists(new Path(out)))
fs.delete(new Path(out), true)
rdd2.saveAsTextFile("data/res")
}
}
class MyPartitioner extends Partitioner{
// 定义下游存在几个分区
override def numPartitions: Int = 2
// 按照key设定分区位置
override def getPartition(key: Any): Int = {
if(key.toString.equals("hello"))
0
else
1
}
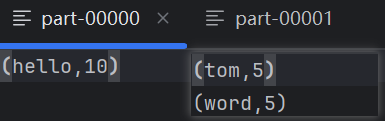
}返回文件结果如下:
案例
需求:以grouptest.txt中的数据为基础,里面是url格式的。用自定义分区的方式实现主题top2
分析需求如下:
- 首先求出每个人员的访问量
- 按照主题将访问量分区
- 使用mapPartitions一次性取出一个分区进行排序
代码如下:
package com.lmk.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import java.net.URL
object GroupTextForPartitioner {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("GroupTextForPartitioner")
val sc = new SparkContext(conf)
val rdd:RDD[((String, String), Int)] = sc.textFile("data/grouptest.txt")
.map(t => {
val url = new URL(t) // http://hive.lmkspaceol.cn/lmk
val host = url.getHost // hive.lmkspaceol.cn
val path = url.getPath // /lmk
val subject = host.split("\\.")(0) // hive
val user = path.substring(1) // lmk
((subject, user), 1)
}).reduceByKey(_+_)
// 获取主题数量
val rdd2:RDD[String] = rdd.keys.map(_._1).distinct()
// 将数据收集回来当作参数传递,rdd不会当作参数传递,数组格式
val arritems = rdd2.collect()
val rdd1:RDD[((String, String), Int)] = rdd.partitionBy(new UserPartitioner(arritems))
rdd1.mapPartitions(x => {
// 因为数据是迭代器形式的所以先tolist,最后再转成Iterator
x.toList.sortBy(-_._2).take(2).toIterator
}).foreach(println)
}
}
// 类之间数据的传递使用构造器
class UserPartitioner(arr:Array[String]) extends Partitioner {
override def numPartitions: Int = arr.size
// 因为分区数量等于数组长度,所以数组的下标就是分区号
override def getPartition(key: Any): Int = {
val item = key.asInstanceOf[(String, String)]._1
arr.indexOf(item)
}
}
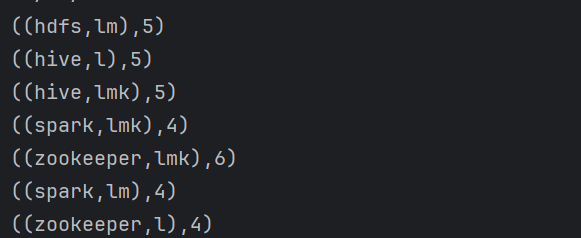
结果如下:
join的原理
join是两个结果集之间的连接,需要对数据进行匹配,首先我们试一下是否存在shuffle。
如果两个rdd都没有分区器,分区个数一致。如下
scala> val arr = Array(("zs",300),("ls",400),("ww",500),("zl", 600))
arr: Array[(String, Int)] = Array((zs,300), (ls,400), (ww,500), (zl,600))
scala> val arr2 = Array(("zs",22),("ls",39),("ww",42),("ss",4))
arr2: Array[(String, Int)] = Array((zs,22), (ls,39), (ww,42), (ss,4))
scala> sc.makeRDD(arr)
res0: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at makeRDD at <console>:25
scala> sc.makeRDD(arr2)
res1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[1] at makeRDD at <console>:25
scala> res0 join res1
res2: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[4] at join at <console>:25
scala> res2.collect
res3: Array[(String, (Int, Int))] = Array((ls,(400,39)), (zs,(300,22)), (ww,(500,42)))
scala> res2.partitions.size
res7: Int = 6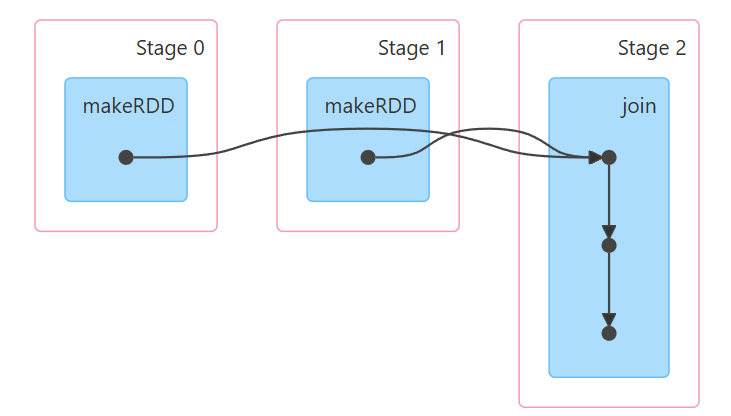
分区个数相同情况,join后分区个数是不变的。
对于分区个数不一致的情况,rdd分区个数以多的为准。
scala> sc.makeRDD(arr,4)
res9: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[5] at makeRDD at <console>:25
scala> sc.makeRDD(arr2,3)
res10: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[6] at makeRDD at <console>:25
scala> res9 join res10
res11: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[9] at join at <console>:25
scala> res11.partitions.size
res12: Int = 4
如果分区个数一样,分区器一样,那join就没有shuffle,分区个数也不变。
scala> val arr = Array(("zs",300),("ls",400),("ww",500),("zl", 600))
arr: Array[(String, Int)] = Array((zs,300), (ls,400), (ww,500), (zl,600))
scala> val arr2 = Array(("zs",22),("ls",39),("ww",42),("ss",4))
arr2: Array[(String, Int)] = Array((zs,22), (ls,39), (ww,42), (ss,4))
scala> sc.makeRDD(arr)
res17: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[15] at makeRDD at <console>:25
scala> sc.makeRDD(arr2)
res18: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[16] at makeRDD at <console>:25
scala> res17.reduceByKey(_+_)
res19: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[17] at reduceByKey at <console>:24
scala> res18.reduceByKey(_+_)
res20: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[18] at reduceByKey at <console>:24
scala> res19 join res20
res21: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[21] at join at <console>:25
scala> res21.collect
res22: Array[(String, (Int, Int))] = Array((ls,(400,39)), (zs,(300,22)), (ww,(500,42)))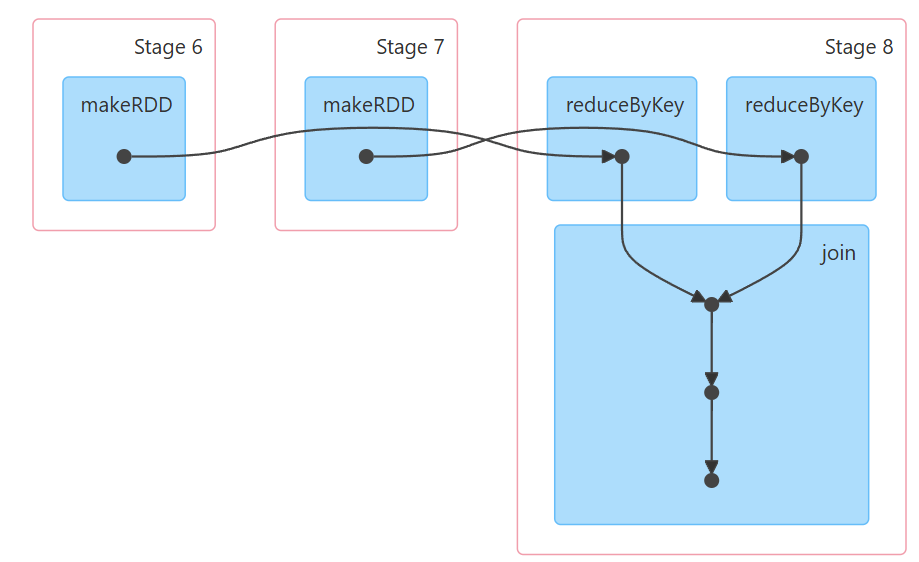
如果分区个数不一样,分区器一样,会存在shuffle,分区个数以多的为准。
scala> val arr = Array(("zs",300),("ls",400),("ww",500),("zl", 600))
arr: Array[(String, Int)] = Array((zs,300), (ls,400), (ww,500), (zl,600))
scala> val arr2 = Array(("zs",22),("ls",39),("ww",42),("ss",4))
arr2: Array[(String, Int)] = Array((zs,22), (ls,39), (ww,42), (ss,4))
scala> sc.makeRDD(arr, 4)
res23: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[22] at makeRDD at <console>:25
scala> sc.makeRDD(arr, 3)
res24: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[23] at makeRDD at <console>:25
scala> res23.reduceByKey(_+_)
res26: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[24] at reduceByKey at <console>:24
scala> res24.reduceByKey(_+_)
res27: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[25] at reduceByKey at <console>:24
scala> res26 join res27
res28: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[28] at join at <console>:25
scala> res28.collect
res29: Array[(String, (Int, Int))] = Array((ww,(500,500)), (zs,(300,300)), (zl,(600,600)), (ls,(400,400)))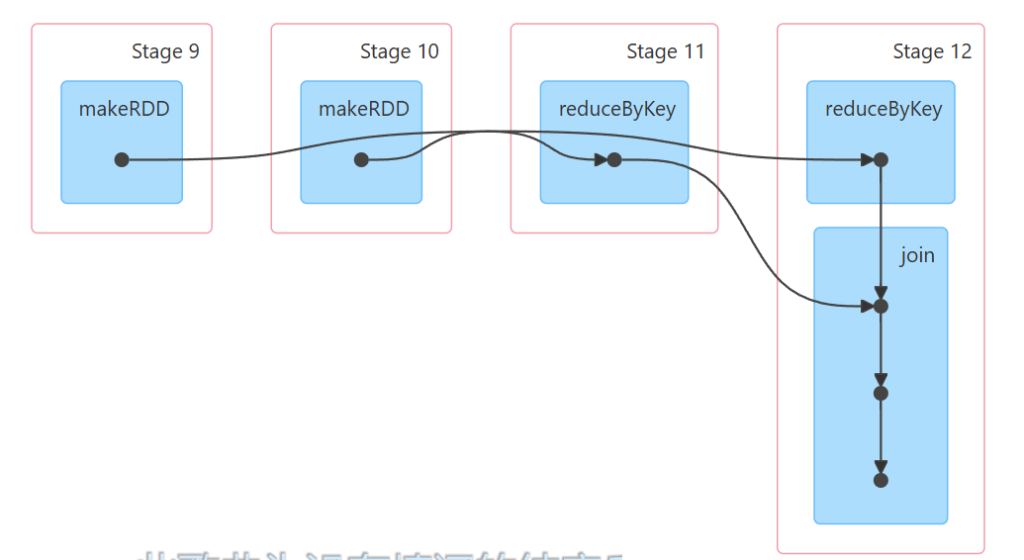
一个带有分区器一个不带分区器,那么以带有分区器的rdd分区数量为主,并且存在shuffle。
scala> arr
res32: Array[(String, Int)] = Array((zs,300), (ls,400), (ww,500), (zl,600))
scala> arr2
res33: Array[(String, Int)] = Array((zs,22), (ls,39), (ww,42), (ss,4))
scala> sc.makeRDD(arr, 3)
res34: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[29] at makeRDD at <console>:25
scala> sc.makeRDD(arr2, 4)
res35: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[30] at makeRDD at <console>:25
scala> res34.reduceByKey(_+_)
res36: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[31] at reduceByKey at <console>:24
scala> res36 join res35
res37: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[34] at join at <console>:25
scala> res37.collect
res38: Array[(String, (Int, Int))] = Array((zs,(300,22)), (ls,(400,39)), (ww,(500,42)))
scala> res37.partitions.size
res39: Int = 3
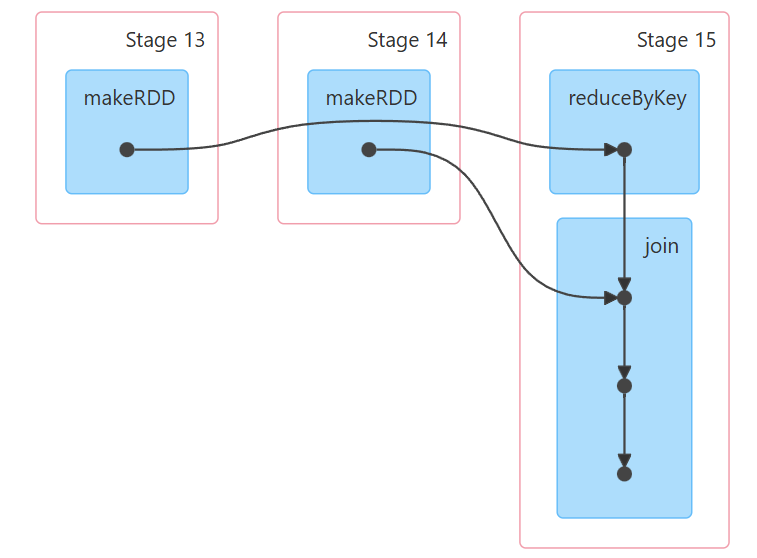
案例
在实际应用场景中,常见的是多表联合查询
需求如下:
// 表1 movies电影表
// movie_id movie_name movie_types
// 文件数据样例为1, Toy Story (1995), Animation|Children's|Comedy
// 表2 ratings评分表
// user_id movie_id score timestamp
// 文件数据样例为 1,1193,5,978300760
// 问题1 每个用户最喜欢哪个类型的电影
// 问题2 每个类型中评分最高的前三个电影
// 问题3 给每个用户推荐最喜欢的类型的前三个电影问题1
代码实现如下:
package com.lmk.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object TestMovie {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("testmovie")
val sc = new SparkContext(conf)
val movieRDD:RDD[(String,(String,String))] = sc.textFile("data/movies.txt")
.map(x => {
val strs = x.split(",")
// head获取第一个元素
val mid = strs.head
// reverse反转
val types = strs.reverse.head
// tail去掉第一个元素,然后反转后再去掉第一个元素,再反转回来,就是中间内容
// strs.tail.reverse.tail返回类型和 strs 一样
// mkString把一个数组(或集合)中的所有元素,用空格 " " 连接成一个字符串。
val name = strs.tail.reverse.tail.mkString(" ")
(mid, name, types)
}).flatMap(x => {
x._3.split("\\|").map((x._1, x._2, _))
//(11, The (1995)" "American President,Comedy)
//(11, The (1995)" "American President,Drama)
//(11, The (1995)" "American President,Romance)
}).map(x => (x._1, (x._2, x._3)))
// mid name type
// 将id当作key进行关联使用
val ratingsRDD:RDD[(String,(String,Double))] = sc.textFile("data/ratings.txt")
// 1,16,4.0,1217897793
.map(x => {
val strs = x.split(",")
// 评分需要计算,转换一下格式。
// 因为需要使用电影id做key进行关联,所以将他放在第一个
// mid userid score
(strs(1), (strs(0), strs(2).toDouble))
})
// mid name type userid score
val baseData:RDD[(String,((String, String), (String, Double)))] = movieRDD.join(ratingsRDD)
val userTypeCount:RDD[((String,String),Int)] = baseData.map(x => {
((x._2._2._1,x._2._1._2), 1)
}).reduceByKey(_+_)
val userTypeCountGroup:RDD[(String, Iterable[(String, Int)])] = userTypeCount.map(x => {
(x._1._1,(x._1._2,x._2))
}).groupByKey()
val userTypeTop1:RDD[(String, (String, Int))] = userTypeCountGroup.mapValues(x => {
// x.toList.sortBy(-_._2).take(1)
// 整体排序效率太低,只要一个最大值,不进行全局排序
var max = 0
var max_tp: (String, Int) = null
x.foreach(tp => {
if (tp._2 > max) {
max_tp = tp
max = tp._2
}
})
max_tp
})
userTypeTop1.foreach(println)
}
}
结果:
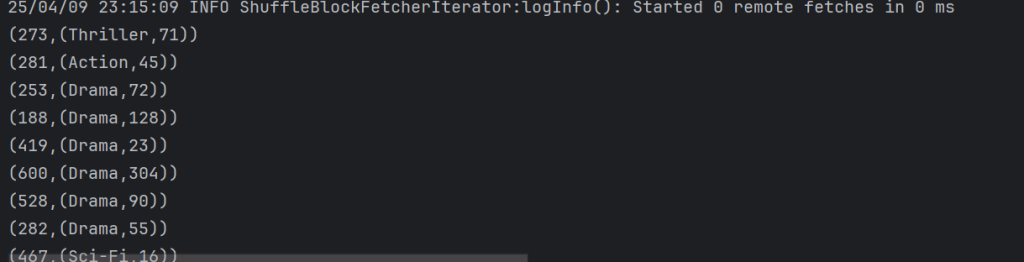
问题2
代码如下:
package com.lmk.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object TestMovieType {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("testmovietype")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val movieRDD:RDD[(String,(String,String))] = sc.textFile("data/movies.txt")
.map(x => {
val strs = x.split(",")
val mid = strs.head
val types = strs.reverse.head
val name = strs.tail.reverse.tail.reverse.mkString(" ")
(mid, name, types)
}).flatMap(x => {
x._3.split("\\|").map((x._1, x._2, _))
}).map(x => (x._1, (x._2, x._3)))
val ratringRDD:RDD[(String,(String,Double))] = sc.textFile("data/ratings.txt")
.map(x => {
val strs = x.split(",")
(strs(1), (strs(0), strs(2).toDouble))
})
val baseData: RDD[(String, ((String, String), (String, Double)))] = movieRDD.join(ratringRDD)
val groupData: RDD[((String, String), Iterable[Double])] = baseData.map(x => {
((x._2._1._2, x._2._1._1), x._2._2._2)
}).groupByKey()
val avgData: RDD[((String, String), Double)] = groupData.mapValues(x => {
x.sum / x.size
})
val groupAvgData: RDD[(String, Iterable[(String, Double)])] = avgData.map(x => {
(x._1._1, (x._1._2, x._2))
}).groupByKey()
groupAvgData.mapValues(x => {
x.toList.sortBy(-_._2).take(3)
}).foreach(println)
}
}
结果如下:

问题3
代码实现如下:
package com.lmk.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object TestMovieUser {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("testmovieuser")
val sc = new SparkContext(conf)
val movieRDD: RDD[(String, (String, String))] = sc.textFile("data/movies.txt")
.map(x => {
val strs = x.split(",")
val mid = strs.head
val types = strs.reverse.head
val name = strs.tail.reverse.tail.reverse.mkString(" ")
(mid, name, types)
}).flatMap(x => {
x._3.split("\\|").map((x._1, x._2, _))
}).map(x => (x._1, (x._2, x._3)))
val ratingsRDD: RDD[(String, (String, Double))] = sc.textFile("data/ratings.txt")
.map(x => {
val strs = x.split(",")
(strs(1), (strs(0), strs(2).toDouble))
})
val baseData: RDD[(String, ((String, String), (String, Double)))] = movieRDD.join(ratingsRDD)
val groupData: RDD[((String, String), Iterable[Double])] = baseData.map(x => {
((x._2._1._2, x._2._1._1), x._2._2._2)
}).groupByKey()
val groupTypeData: RDD[(String, List[(String, Double)])] = groupData.mapValues(x => {
x.sum / x.size
}).map(x => {
(x._1._2, (x._1._1, x._2))
}).groupByKey().mapValues(x => {
x.toList.sortBy(-_._2).take(3)
})
val userType: RDD[(String, String)] = baseData.map(x => {
((x._2._1._2, x._2._2._1), 1)
}).reduceByKey(_ + _)
.map(x => {
(x._1._2, (x._1._1, x._2))
}).groupByKey()
.mapValues(x => {
var max = 0
var max_tp: (String, Int) = null
x.foreach(tp => {
if (max < tp._2) {
max_tp = tp
max = tp._2
}
})
max_tp
}).map(x => {
(x._2._1, x._1)
})
val typeMovie: RDD[(String, String)] = groupTypeData.flatMap(x => {
x._2.map(y => {
(y._1, x._1)
})
})
typeMovie.join(userType).map(x => {
(x._2._2, x._2._1)
}).foreach(println)
}
}
返回结果如下:
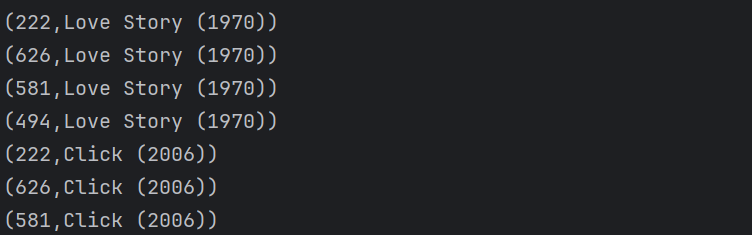
二次排序
当我们想要排序的时候,想要优先使用一个字段排序,如果这个字段相同使用另外一个字段排序。
这种情况使用自带的sortBy是实现不了的。需要我们自定义排序规则
package com.lmk.spark
import org.apache.spark.{SparkConf, SparkContext}
object SecondarySort {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("SecondarySort")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.textFile("data/score.txt")
.map(x => {
val strs = x.split(" ")
// 这里我们将元素转换成了MyScore的对象,输出MyScore的对象
// 对象序列化了,所以需要toString方法才能看到内容
// new MyScore(strs(0), strs(1).toInt, strs(2).toInt)
//}).sortBy(x=>x)
(strs(0), strs(1).toInt, strs(2).toInt)
// 这里这种方式输出的就是原本的数据,但是规则使用了自定义的规则
}).sortBy(x=>new MyScore(x._1, x._2, x._3))
.foreach(println)
}
// 想要远程传输,就需要序列化,继承序列化接口
class MyScore(var name: String, var math: Int, var english: Int) extends Ordered[MyScore] with Serializable {
override def compare(that: MyScore): Int = {
val mathRes = this.math - that.math
if (mathRes != 0)
mathRes else this.english - that.english
}
override def toString: String = s"name=${name} + math=${math} + english=${english}"
}
}
RDD间操作
| 函数 | 目的 | 示例 | 结果 |
|---|---|---|---|
union(other) | 生成一个包含两个RDD中所有元素的RDD | rdd.union(other) | {1, 2, 3, 4, 5} |
intersection(other) | 求两个RDD交集的RDD | rdd.intersection(other) | {3} |
subtract(other) | 移除一个RDD的内容,差集 | rdd.subtract(other) | {1, 2} |
cartesian(other) | 与另一个RDD的笛卡尔积 | rdd.cartesian(other) | {(1, 3), (1, 4)....} |
注意:类型要一致
union
合并两个RDD,注意这里是不去重的。之间简单的合并,分区个数也是之间加起来的,虽然分区个数变了,但是不存在shuffle。
需要注意的是,一个stage中task任务的个数以最后一个RDD的分区个数为主。union或者coalesce都可能产生这种影响。如下图
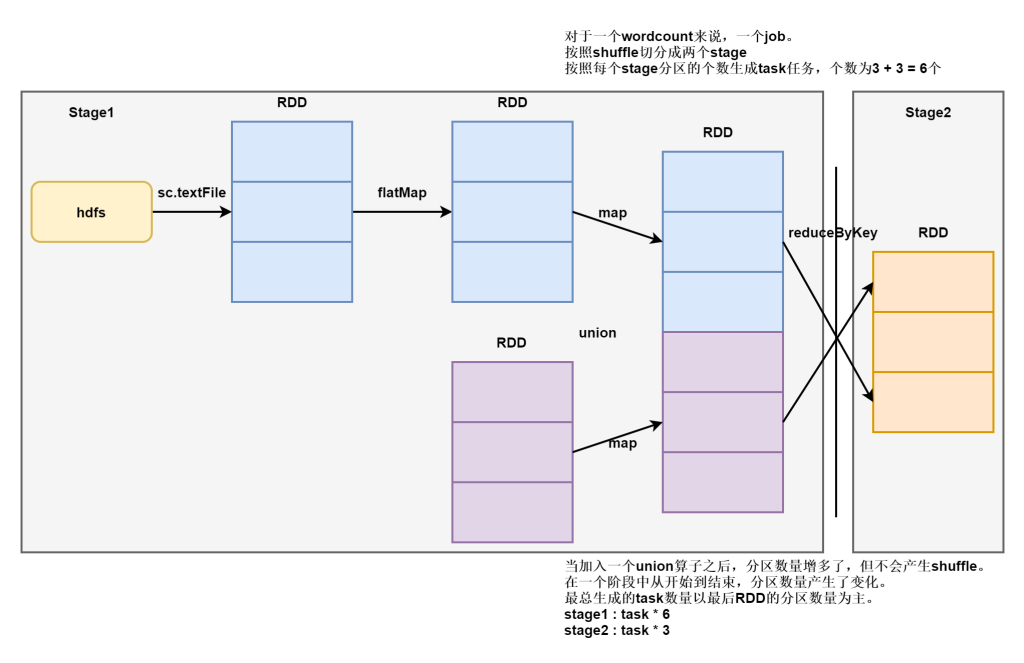
scala> val arr = Array(1,2,3,4,5)
arr: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val arr1 = Array(3,4,5,6,7)
arr1: Array[Int] = Array(3, 4, 5, 6, 7)
scala> sc.makeRDD(arr)
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:25
scala> sc.makeRDD(arr1)
res1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:25
scala> res0 union res1
res2: org.apache.spark.rdd.RDD[Int] = UnionRDD[2] at union at <console>:25
scala> res2.collect
res3: Array[Int] = Array(1, 2, 3, 4, 5, 3, 4, 5, 6, 7)
scala> res2.partitions.size
res14: Int = 12intersection
取两个RDD交集,这里可以看出是去重的。
scala> res0 intersection res1
res4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[8] at intersection at <console>:25
scala> res4.collect
res5: Array[Int] = Array(3, 4, 5)subtract
对一个RDD移除令一个RDD的内容,做减法。
scala> res0 subtract res1
res6: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[12] at subtract at <console>:25
scala> res6.collect
res7: Array[Int] = Array(1, 2)
scala> res1 subtract res0
res8: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[16] at subtract at <console>:25
scala> res8.collect
res9: Array[Int] = Array(6, 7)cartesian
与另一个RDD做笛卡尔积,不只是数据笛卡尔积了,分区也会笛卡尔积。
scala> res0 cartesian res1
res10: org.apache.spark.rdd.RDD[(Int, Int)] = CartesianRDD[17] at cartesian at <console>:25
scala> res10.collect
res11: Array[(Int, Int)] = Array((1,3), (1,4), (1,5), (1,6), (1,7), (2,3), (2,4), (2,5), (2,6), (2,7), (3,3), (3,4), (3,5), (3,6), (3,7), (4,3), (4,4), (4,5), (4,6), (4,7), (5,3), (5,4), (5,5), (5,6), (5,7))
scala> res10.partitions.size
res13: Int = 36分区数量修改算子coalesce 与 repartition
这两个算子是专门调整分区数量的,之前也了解过,存在shuffle的算子可以修改分区数量。
比如groupBy、groupByKey、reduceByKey、distinct可以任意修改分区数量,分区器是HashPartitioner
比如sortBy、sortByKey可以修改但不能大于元素个数,分区器是RangePartitioner,需要先做水塘抽样,均衡数据量规定上下限。
coalesce 与 repartition不同的是coalesce只能减少分区数量,而且不存在shuffle。repartition可以加也可以减,存在shuffle流程。
对于有些特殊的情况需要修改分区的数量。比如下面的情况:
- 大量数据处理时,压力过大,需要增加分区数量
- 在数据清洗的过程中,删除大量脏数据,分区数量过多,无意义占用资源,需要减少分区数量。
scala> val arr = Array(1,2,3,4,5,6)
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6)
scala> sc.makeRDD(arr)
res15: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[18] at makeRDD at <console>:25
scala> res15.coalesce(2)
res16: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[19] at coalesce at <console>:24
scala> res16.partitions.size
res17: Int = 2
scala> res15.coalesce(12)
res18: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[20] at coalesce at <console>:24
scala> res18.partitions.size
res19: Int = 6
scala> res15.repartition(2)
res20: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[24] at repartition at <console>:24
scala> res20.partitions.size
res21: Int = 2
scala> res15.repartition(12)
res22: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[28] at repartition at <console>:24
scala> res22.partitions.size
res23: Int = 12查看repartition源码如下:
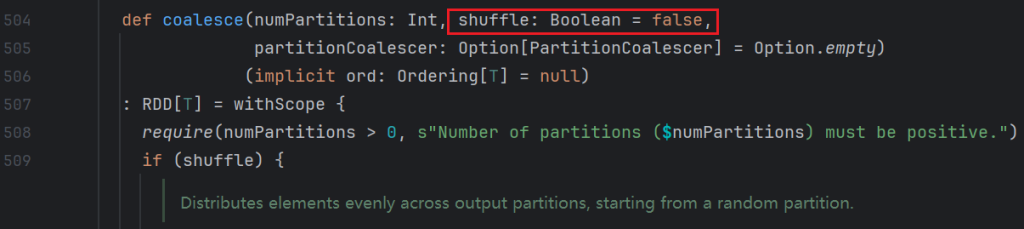
repartition其实调用 了coalesce。将shuffle改成了true
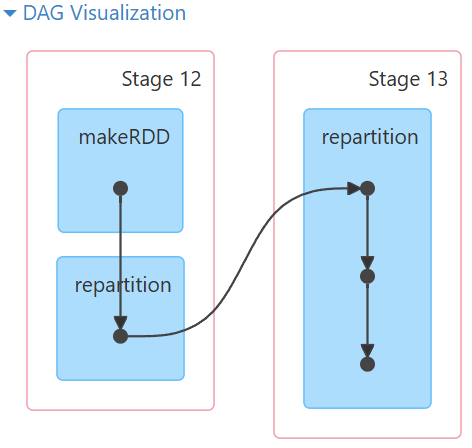

coalesce默认shuffle是false,所以coalesce不带shuffle。减少的时候,没有打乱重分,减少的时候,将两个分区合并成一个。
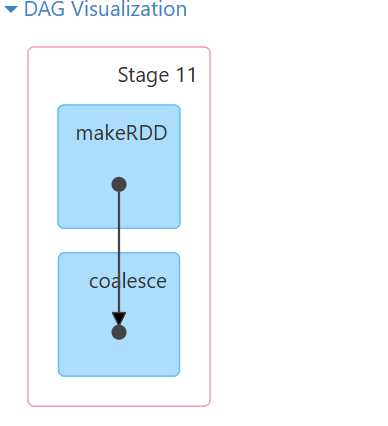
其他转换操作
foldByKey
def foldByKey(zeroValue: V)func: (V, V) => V):RDD[(K,V)]
参数zeroValue:是一个初始化值,它可以是任意类型。
参数func:是一个函数,两个输入参数相同。
带有shuffle并且可以修改分区。

scala> val arr = Array(("a", 1), ("b", 1), ("a", 1), ("b", 1), ("a", 1), ("c", 1))
arr: Array[(String, Int)] = Array((a,1), (b,1), (a,1), (b,1), (a,1), (c,1))
scala> sc.makeRDD(arr, 3)
res29: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[35] at makeRDD at <console>:25
scala> res29.reduceByKey(_+_)
res30: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[36] at reduceByKey at <console>:24
scala> res30.collect
res31: Array[(String, Int)] = Array((c,1), (a,3), (b,2))
scala> res29.foldByKey
def foldByKey(zeroValue: Int)(func: (Int, Int) => Int): org.apache.spark.rdd.RDD[(String, Int)]
def foldByKey(zeroValue: Int,numPartitions: Int)(func: (Int, Int) => Int): org.apache.spark.rdd.RDD[(String, Int)]
def foldByKey(zeroValue: Int,partitioner: org.apache.spark.Partitioner)(func: (Int, Int) => Int): org.apache.spark.rdd.RDD[(String, Int)]
scala> res29.foldByKey(0, 6)(_+_)
res32: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[37] at foldByKey at <console>:24
scala> res32.partitions.size
res33: Int = 6
scala> res32.collect
res35: Array[(String, Int)] = Array((a,3), (b,2), (c,1))
scala> res29.foldByKey(10, 6)(_+_)
res36: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[38] at foldByKey at <console>:24
scala> res36.collect
res37: Array[(String, Int)] = Array((a,33), (b,22), (c,11))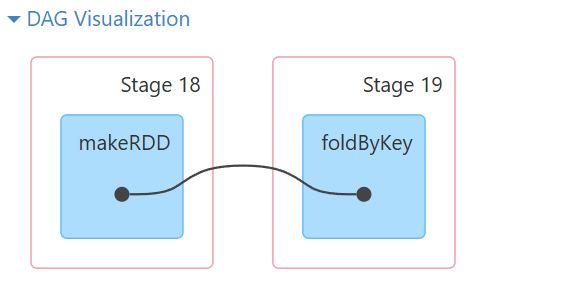
aggregateByKey
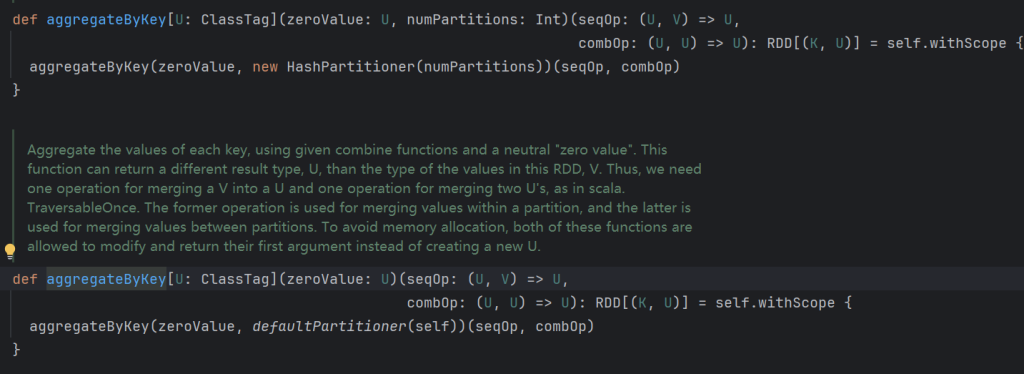
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U, combOp:(U, U)=>U):RDD(K,U)
zero value(初始值)∶给每一个分区中的每一种key一个初始值。
seqOp(分区内):函数用于在每一个分区中用初始值逐步迭代value 。
combOp(分区间):函数用于合并每个分区中的结果。
带有初始值的reduceByKey,分区内的算法和分区间的算法可以不一样,有shuffle流程,使用hash分区器。
scala> val arr = Array(("a", 1), ("b", 1), ("a", 1), ("b", 1), ("a", 1), ("c", 1))
arr: Array[(String, Int)] = Array((a,1), (b,1), (a,1), (b,1), (a,1), (c,1))
scala> sc.makeRDD(arr, 3)
res39: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[40] at makeRDD at <console>:25
// 现在分区中做什么操作,然后再整体做什么操作
scala> res39.aggregateByKey(0)(_+_,_+_)
res40: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[41] at aggregateByKey at <console>:24
scala> res40.collect
res41: Array[(String, Int)] = Array((c,1), (a,3), (b,2))
scala> res39.aggregateByKey
def aggregateByKey[U](zeroValue: U)(seqOp: (U, Int) => U,combOp: (U, U) => U)(implicit evidence$3: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[(String, U)]
def aggregateByKey[U](zeroValue: U,numPartitions: Int)(seqOp: (U, Int) => U,combOp: (U, U) => U)(implicit evidence$2: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[(String, U)]
def aggregateByKey[U](zeroValue: U,partitioner: org.apache.spark.Partitioner)(seqOp: (U, Int) => U,combOp: (U, U) => U)(implicit evidence$1: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[(String, U)]
scala> res39.aggregateByKey(10, 9)(_+_,_+_)
res42: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[42] at aggregateByKey at <console>:24
scala> res42.partitions.size
res43: Int = 9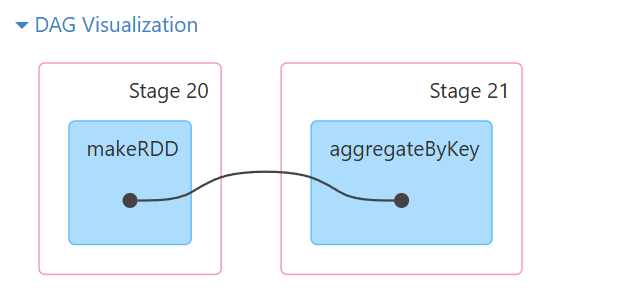
combineByKey
def combineByKey[C](
// 初始化值,可以是函数
createCombiner: V => C,
// 局部聚合
mergeValue: (C, V) => C
// 全局聚合
mergeCombiners: (C, C) => C): RDD[(K, C)]createCombiner(转换数据的结构):combineByKey会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey会使用一个叫作createCombiner的函数来创建那个键对应的累加器的初始值。
mergeValue(分区内):如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue方法将该键的累加器对应的当前值与这个新的值进行合并。
mergeCombiners(分区间):由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners方法将各分区结果进行合并。
此操作针对相同K,将V合并成一个集合。
scala> val arr = Array(("a", 1), ("b", 1), ("a", 1), ("b", 1), ("a", 1), ("c", 1))
arr: Array[(String, Int)] = Array((a,1), (b,1), (a,1), (b,1), (a,1), (c,1))
scala> sc.makeRDD(arr, 3)
res44: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[43] at makeRDD at <console>:25
scala> res44.combineByKey
combineByKey combineByKeyWithClassTag
scala> res44.combineByKey
def combineByKey[C](createCombiner: Int => C,mergeValue: (C, Int) => C,mergeCombiners: (C, C) => C): org.apache.spark.rdd.RDD[(String, C)]
def combineByKey[C](createCombiner: Int => C,mergeValue: (C, Int) => C,mergeCombiners: (C, C) => C,numPartitions: Int): org.apache.spark.rdd.RDD[(String, C)]
def combineByKey[C](createCombiner: Int => C,mergeValue: (C, Int) => C,mergeCombiners: (C, C) => C,partitioner: org.apache.spark.Partitioner,mapSideCombine: Boolean,serializer: org.apache.spark.serializer.Serializer): org.apache.spark.rdd.RDD[(String, C)]
// 报错了,需要指定格式
scala> res44.combineByKey(x => x, _+_, _+_)
<console>:24: error: missing parameter type for expanded function ((x$1: <error>, x$2: Int) => x$1.$plus(x$2))
res44.combineByKey(x => x, _+_, _+_)
^
<console>:24: error: missing parameter type for expanded function ((x$3: <error>, x$4) => x$3.$plus(x$4))
res44.combineByKey(x => x, _+_, _+_)
^
<console>:24: error: missing parameter type for expanded function ((x$3: <error>, x$4: <error>) => x$3.$plus(x$4))
res44.combineByKey(x => x, _+_, _+_)
^
scala> res44.combineByKey((x:Int) => x, (a:Int, b:Int) => a + b, (a:Int, b:Int) => a + b)
res46: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[44] at combineByKey at <console>:24
scala> res46.collect
res47: Array[(String, Int)] = Array((c,1), (a,3), (b,2))
scala> res44.combineByKey((x:Int) => x + 10, (a:Int, b:Int) => a + b, (a:Int, b:Int) => a + b)
res48: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[45] at combineByKey at <console>:24
scala> res48.collect
res49: Array[(String, Int)] = Array((c,11), (a,33), (b,22))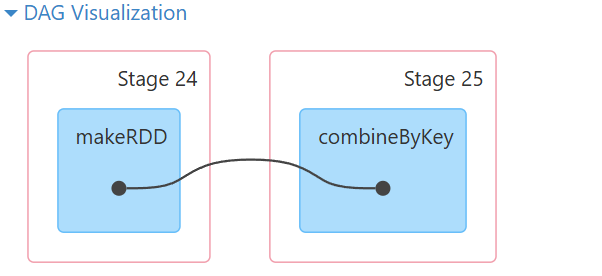
filterByRange
filter过滤元素,在排序完毕以后的结果集上面使用,按照范围得出符合元素规则的子结果集。
子结果集是原来rdd的一个片段,分区和元素的部署对应情况不变。
scala> val arr = Array((1,1), (2,2), (3,3), (4,4), (5,5), (6,6))
arr: Array[(Int, Int)] = Array((1,1), (2,2), (3,3), (4,4), (5,5), (6,6))
scala> sc.makeRDD(arr, 4)
res11: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[8] at makeRDD at <console>:25
scala> res11.sortByKey()
res12: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[11] at sortByKey at <console>:24
scala> res12.mapPartitionsWithIndex((index, it) => it.map((index, _)))
res13: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[12] at mapPartitionsWithIndex at <console>:24
scala> res13.collect
res14: Array[(Int, (Int, Int))] = Array((0,(1,1)), (0,(2,2)), (1,(3,3)), (2,(4,4)), (2,(5,5)), (3,(6,6)))
scala> res12.filterByRange(2, 3)
res19: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[16] at filterByRange at <console>:24
// 可以看出是按照范围进行过滤,与分区无关
scala> res19.collect
res20: Array[(Int, Int)] = Array((2,2), (3,3))
scala> res12.filterByRange(0, 2)
res22: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[18] at filterByRange at <console>:24
scala> res22.collect
res23: Array[(Int, Int)] = Array((1,1), (2,2))
scala> res19.mapPartitionsWithIndex((index, it) => it.map((index, _)))
res25: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[19] at mapPartitionsWithIndex at <console>:24
// 新的RDD就只有两个分区了
scala> res25.collect
res26: Array[(Int, (Int, Int))] = Array((0,(2,2)), (1,(3,3)))
scala> res12.filterByRange(2, 5)
res29: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[23] at filterByRange at <console>:24
scala> res29.collect
res30: Array[(Int, Int)] = Array((2,2), (3,3), (4,4), (5,5))
行动类算子(action)
| 函数 | 目的 | 示例 | 结果 |
|---|---|---|---|
collect() | 以数组的形式返回RDD中的所有元素 | rdd.collect() | {1, 2, 3, 3} |
collectAsMap() | 该函数用于Pair RDD,最终返回Map类型的结果 | rdd2.collectAsMap() | Map("a"->1, "b"->2) |
count() | 返回RDD中的元素个数 | rdd.count() | 4 |
countByValue() | 返回各元素在RDD中出现的次数 | rdd.countByValue() | {(1, 1), (2, 1), (3, 2)} |
take(n) | 从RDD中返回n个元素 | rdd.take(1) | {1} |
first() | 从RDD中返回第一个元素 | rdd.first() | 1 |
top(num) | 返回最大的num个元素 | rdd.top(2) | {3, 3} |
takeOrdered(num)(ordering) | 按照指定顺序返回前面num个元素 | rdd.takeOrdered(2) | {1, 2} |
reduce(func) | 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素,比如求和 | rdd.reduce((a,b)=>a+b) | ((1+2) + 3) + 3) = 9 |
fold(zero)(func) | 和reduce一样,给定初值,每个分区计算时都会使用此初值 | rdd.fold(1)((a,b)=>a+b) | 2个分区时结果:1+ ((1+1) + 2) + ((1 +3) +3) |
aggregate(zeroValue)(seqOp,combOp) | 和reduce类似,但可以返回类型不同的结果 | rdd.aggregate(0)((x,y) => x + y, (x,y) => x + y) | 9 |
foreach(func) | 对每个元素使用func函数 | rdd.foreach(println(_)) | 在executor端打印输出所有元素 |
foreachPartition | 每个分区遍历一次 |
使用案例如下:
collect()
collect将RDD类型的数据转化为数组,同时会从远程集群拉取所有数据到driver端,谨慎使用。
scala> val arr = Array(1,2,3,4,5,6,7,8,9)
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> sc.makeRDD(arr, 3)
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:25
scala> res0.collect
res1: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)collectAsMap()
collectAsMap函数返回所有元素集合,使用时需要rdd时(k,v)数据,不过该集合是去掉的重复的key的集合,如果元素重该复集合中保留的元素是位置最后的一组。
toMap也会去重, collect + toMap = collectAsMap
scala> res0.map(x => (x, x))
res3: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[1] at map at <console>:24
scala> res3.collectAsMap
res4: scala.collection.Map[Int,Int] = Map(8 -> 8, 2 -> 2, 5 -> 5, 4 -> 4, 7 -> 7, 1 -> 1, 9 -> 9, 3 -> 3, 6 -> 6)
scala> res3.collect
res5: Array[(Int, Int)] = Array((1,1), (2,2), (3,3), (4,4), (5,5), (6,6), (7,7), (8,8), (9,9))
// toMap也会去重, collect + toMap = collectAsMap
scala> res5.toMap
res6: scala.collection.immutable.Map[Int,Int] = Map(5 -> 5, 1 -> 1, 6 -> 6, 9 -> 9, 2 -> 2, 7 -> 7, 3 -> 3, 8 -> 8, 4 -> 4)
scala> val arr1 = Array(1,2,3,4,5,2,3,4,5)
arr1: Array[Int] = Array(1, 2, 3, 4, 5, 2, 3, 4, 5)
scala> sc.parallelize(arr1)
res7: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:25
scala> res7.map(x => (x, x))
res8: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[3] at map at <console>:24
// 去重了
scala> res8.collectAsMap
res9: scala.collection.Map[Int,Int] = Map(2 -> 2, 5 -> 5, 4 -> 4, 1 -> 1, 3 -> 3)count()
返回整个 RDD 的元素个数。
scala> res7.count
res12: Long = 9countByValue()
返回各元素在RDD中出现的次数,会自动变成k,v格式返回。
scala> val arr1 = Array(1,2,3,4,5,2,3,4,5)
arr1: Array[Int] = Array(1, 2, 3, 4, 5, 2, 3, 4, 5)
scala> sc.parallelize(arr1)
res15: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:25
scala> res15.countByValue()
res16: scala.collection.Map[Int,Long] = Map(5 -> 2, 1 -> 1, 2 -> 2, 3 -> 2, 4 -> 2)
scala> sc.textFile("/test/a.txt")
res18: org.apache.spark.rdd.RDD[String] = /test/a.txt MapPartitionsRDD[9] at textFile at <console>:24
// 使用这个实现wordcount就很简单了,只不过返回值变成了map,不是转换类的rdd了
scala> res18.flatMap(x => x.split(" ")).countByValue()
res20: scala.collection.Map[String,Long] = Map(tom -> 10, hello -> 20, wrold -> 10)take(n)
返回一个由RDD的前n个元素组成的数组。
scala> val arr1 = Array(1,2,3,4,5,2,3,4,5)
arr1: Array[Int] = Array(1, 2, 3, 4, 5, 2, 3, 4, 5)
scala> sc.parallelize(arr1)
res15: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:25
scala> res15.take(3)
res21: Array[Int] = Array(1, 2, 3)first()
从RDD中返回第一个元素
scala> res15.first
res22: Int = 1top(num)
返回最大的num个元素,有排序的,倒序。
scala> res15.top(4)
res23: Array[Int] = Array(5, 5, 4, 4)takeOrdered(num)(ordering)
按照指定顺序返回前面num个元素,有排序,正序。
scala> val arr2 = Array(6,5,4,3,2,1)
arr2: Array[Int] = Array(6, 5, 4, 3, 2, 1)
scala> sc.parallelize(arr2)
res24: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[16] at parallelize at <console>:25
scala> res24.top(3)
res25: Array[Int] = Array(6, 5, 4)
scala> res24.take(3)
res26: Array[Int] = Array(6, 5, 4)
scala> res24.takeOrdered(3)
res27: Array[Int] = Array(1, 2, 3)有排序就意味着数据必须能排序,因为没有排序规则,需要自己指定排序。比如下面的案例:
// 如果想要排序需要在类上加排序规则ordered。或者new 一个比较器ordering
scala> class Student(val name:String, val age:Int)
defined class Student
scala> val s1 = new Student("zs", 14)
s1: Student = Student@60869c90
scala> val s2 = new Student("ls", 24)
s2: Student = Student@25bdc068
scala> val s3 = new Student("ww", 27)
s3: Student = Student@57bfeb0f
scala> val arr = Array(s1, s2, s3)
arr: Array[Student] = Array(Student@60869c90, Student@25bdc068, Student@57bfeb0f)
scala> sc.parallelize(arr)
res28: org.apache.spark.rdd.RDD[Student] = ParallelCollectionRDD[19] at parallelize at <console>:25
scala> res28.top(2)
<console>:24: error: No implicit Ordering defined for Student.
res28.top(2)reduce(func)
通过函数func(输入两个参数并返回一个值)聚合数据集中的元素,比如求和。
scala> val arr = Array(1,2,3,4,5,6,7,8,9)
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> sc.parallelize(arr,3)
res1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:25
scala> res1.reduce((a, b) => a + b)
res3: Int = 45
scala> res1.reduce((a, b) => a + b * b)
res4: Int = 4573
scala> res1.reduce(_+_)
res5: Int = 45fold(zero)(func)
和reduce一样,给定初值,每个分区计算时都会使用此初值。与groupByKey不同的是,除了每个分区有初始化值,整体也会有一个初始化值。
scala> res1.fold(0)(_+_)
res6: Int = 45
// 三个分区,每个分区增加10,最后整体聚合又多了10,所以多了40
scala> res1.fold(10)(_+_)
res7: Int = 85aggregate(zeroValue)(seqOp,combOp)
和reduce类似,但可以返回类型不同的结果,后面先是分区合并公式,后是整体合并公式。
scala> res1.aggregate(0)(_+_,_+_)
res12: Int = 45
scala> res1.aggregate(0)(_+_,_*_)
res13: Int = 0
scala> res1.aggregate(0)(_+_,_-_)
res14: Int = -45
scala> res1.aggregate(10)(_+_,_+_)
res15: Int = 85foreach(func)
对每个元素使用func函数。
scala> res1.foreach(println)
// 这个操作每个分区打印自己的数据,在driver端是看不到的。标准输出通过webUI查看


foreachPartition
每个分区遍历一次,就像之前需要每个元素查询数据库的操作一样。连接代码不能完全提出来,因为提出来就是放到drive段,不到各个节点。需要放在rdd中去操作,所以使用这个方法就能减少连接的次数。
foreachPartition 一般都是没有后续操作的时候使用,因为触发运算,比如插入数据。
mapPartitions 一般都是后续继续使用的时候,比如查询操作。
scala> res1.foreachPartition(println)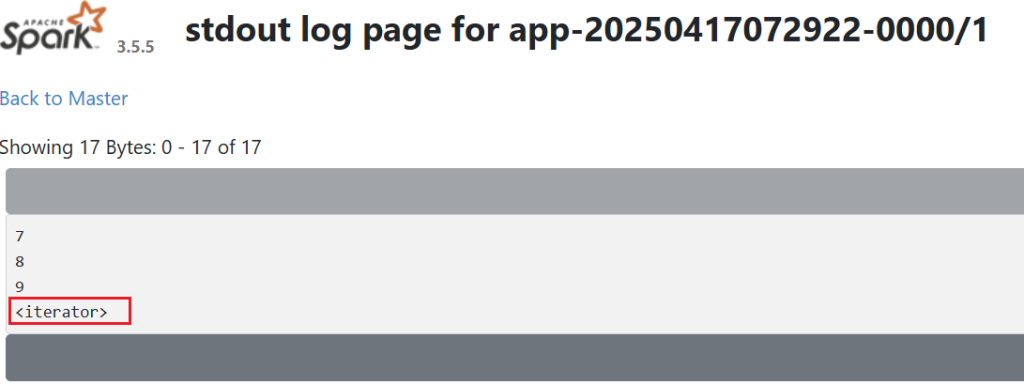
返回数据到redis案例:
package com.lmk.spark
import org.apache.spark.{SparkConf, SparkContext}
import redis.clients.jedis.Jedis
/**
* redis 是一个分布式的key-value数据库
* set 插入或修改数据
* get 查询数据
*/
object ForeachPartition2Redis {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ForeachPartition2Redis")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.textFile("data/a.txt")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_+_)
.foreachPartition(x => {
// 每个分区
val redis = new Jedis("192.168.149.50", 6379)
redis.auth("****")
x.foreach(tp => {
// redis 只支持String类型
redis.set(tp._1, tp._2.toString)
})
redis.close()
})
}
}
查询redis返回结果
root@nn1:/home/hadoop# redis-cli -h nn1 -p 6379 -a ***
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
nn1:6379> keys *
1) "word"
2) "tom"
3) "hello"
nn1:6379> get word
"5"
nn1:6379> get tom
"5"
nn1:6379> get hello
"10"