hive内置函数
聚合函数
将多行聚合为一行,与常用的关系型数据库相似,不再过多介绍。
count()
count(col)或者count(distinct col)返回检索行的总数,使用count(*)和count(1)的区别不大,count(1) 稍微比 count(*) 快点,其实关系型数据库好多也优化过了,使用*都是一样的。
与关系型数据库不同的是,count(*)和count(列名)是不同的,如果是null值,那么count(列名)不会进行统计,如下面的案例。
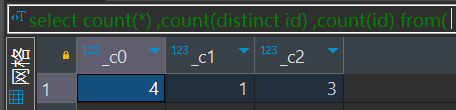
select count(*)
,count(distinct id)
,count(id)
from(select '1' id
union all
select null
union all
select '1'
union all
select '1') v结果集:
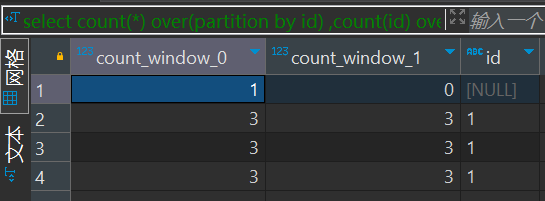
因为在开发sql的过程中经常使用开窗函数,所以试了一下,count(id)确实不会统计null
select count(*) over(partition by id)
,count(id) over(partition by id)
, id
from(select '1' id
union all
select null
union all
select '1'
union all
select '1') v结果集:
sum()
sum(col)或者sum(distinct col),返回该组或该组中的列的不同值的分组和所有元素的总和。
avg()
avg(col)或者avg(distinct col),返回上述组或该组中的列的不同值的元素的平均值。
min()
返回该组中的列的最小值。
max()
返回该组中的列的最大值。
高级聚合函数
collect_list()
收集并形成list集合,结果不去重。
select y,
collect_list(sales)
from sale_table
group by y
-- 2017 [1000,1000,3000,3000,5000,5000,1000,1000,3000,3000,5000,5000]
-- 2018 [1000,2000,3000,4000,5000,6000]collect_set()
收集并形成set集合,结果去重
select y,
collect_set(sales)
from sale_table
group by y
-- 2017 [1000,3000,5000]
-- 2018 [1000,2000,3000,4000,5000,6000]单行函数
数值函数
round()
四舍五入
select round(23.453, 2)
-- 23.45ceil()
向上取整,不能指定小数,直接取整。
select ceil(23.453)
-- 24floor()
向下取整。
select floor(23.453)
-- 23字符串函数
substring()/substr()
截取字符串,截取字符有两种写法,也有两种用法,根据变量个数区分。
- substr(string A, int start)
- 返回值:string
- 说明:返回字符串A从start位置开始,长度为len的字符串
- substring(string A, int start, int len)
- 返回值:string
- 说明:返回字符串A从start位置开始,长度为len的字符串
案例如下:
获取第二个字符以后的所有字符
select substr('abcdef', 2),
substring('abcdef', 2)
-- bcdef bcdef获取倒数第三个字符以后的所有字符
select substr('abcdef', -3)
-- def从第3个字符开始,向后获取2个字符
select substr('abcdef', 3, 2)
-- cdreplace()
替换,语法:replace(string A, string B, string C)
select replace('abcdef', 'abc', 'lll')
-- llldefregexp_replace()
正则替换,语法:regexp_replace(string A, string B, string C)。
说明:将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符。
-- 这里是\需要加转义字符的
select regexp_replace('abcdef', '\\w', '1')
111111regexp
正则匹配,语法:字符串 regexp 正则表达式。
说明:若字符串符合正则表达式,则返回true,否则返回false。
select 'abcdef' regexp '\\w+'
-- truerepeat()
重复字符串,语法:repeat(string A, int n)
说明:将字符串A重复n遍。
select repeat('abcdef', 3)
-- abcdefabcdefabcdefsplit()
字符串切割,语法:split(string str, string pat)。返回值:array
select split('a b c d e', ' ')
-- ["a","b","c","d","e"]nvl()
替换null值,语法:nvl(A,B)
说明:若A的值不为null,则返回A,否则返回B。
select nvl(null, 3)
-- 3concat() 或者 ||
拼接字符串,语法:concat(string A, string B, string C, ……)
说明:将A,B,C……等字符拼接为一个字符串。
select concat('ab', 'cd', 'ef')
select 'ab'||'cd'||'ef'
-- abcdefconcat_ws()
以指定分隔符拼接字符串或者字符串数组,语法:concat_ws(string A, string…| array(string))
说明:使用分隔符A拼接多个字符串,或者一个数组的所有元素。
select concat_ws('-', 'ab', 'cd', 'ef')
-- ab-cd-ef
select concat_ws('-',split('a b c d e', ' '))
-- a-b-c-d-e日期函数
当前日期
获取timestamp格式
select current_timestamp()
select current_timestamp
-- 2025-03-11 08:53:50.062获取date格式
select current_date()
select current_date
-- 2025-03-11当前 Unix 时间戳(秒级)
返回当前或指定时间的时间戳。
SELECT unix_timestamp();
-- 1741683706
select unix_timestamp('2025/03/08 00-02-01','yyyy/MM/dd HH-mm-ss');
-- 1741392121from_unixtime()
转化UNIX时间戳(从 1970-01-01 00:00:00 UTC 到指定时间的秒数)到当前时区的时间格式。
语法:from_unixtime(bigint unixtime[, string format])
select from_unixtime(1741392121);
-- 2025-03-08 00:02:01日期加减
select current_timestamp() - interval 3 day
-- 2025-03-08 09:00:40.052获取当前年、月、日、小时、分钟、秒、周几
year()
year(current_date)month()
month(current_date)day()
day(current_date)hour()
hour(current_timestamp())minute()
minute(current_timestamp)second()
second(current_timestamp)dayofweek()
注意,周日是1,周六是7
select DAYOFWEEK(current_timestamp()) from_unixtime()
格式化日期
SELECT from_unixtime(unix_timestamp(), 'yyyy-MM-dd HH:mm:ss');
-- 2025-03-11 09:00:15datediff()
两个日期相差的天数(结束日期减去开始日期的天数),返回值类型:int。
语法:
datediff(string enddate, string startdate)
select datediff('2024-08-08','2025-10-09');
-- 427date_add()
日期加天数,语法:date_add(string startdate, int days)
说明:返回开始日期 startdate 增加 days 天后的日期
select date_add(current_timestamp, 3)
-- 2025-03-20date_sub()
日期减天数,返回值类型:string
语法:
date_sub (string startdate, int days)
select date_sub('2024-08-08',2);
-- 2024-08-06date_format()
将标准日期解析成指定格式字符串。
与熟悉的pg数据库不同,Hive 使用 Java 的 SimpleDateFormat 规则,严格区分大小写。
SELECT date_format('2023-10-01 15:30:45', 'yyyyMMdd HH:mm:ss');
-- 输出: 20231001 15:30:45流程控制函数
case when
条件判断函数。
语法一:case when a then b [when c then d]* [else e] end
语法二: case a when b then c [when d then e]* [else f] end
if()
类似的三目运算符 if(条件, true的结果, false 的结果)。与oracle中decode相似。
语法:if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1 = 1, 1, 0)
-- 1集合函数
size()
集合中元素的个数。
select size(split('a b c d e', ' '))
-- 5map函数
map()
创建map集合,语法:map (key1, value1, key2, value2, …)
说明:根据输入的key和value对构建map类型
select map('a', 2, 'b', 3)
-- {"a":2,"b":3}map_keys()
返回map中的key
select map_keys(map('a', 2, 'b', 3))
-- ["a","b"]map_values()
返回map中的value
select map_values(map('a', 2, 'b', 3))
-- [2,3]array函数
array()
声明array集合,语法:array(val1, val2, …)
说明:根据输入的参数构建数组array类
select array('a', 'b', 'c', 'd', 'e')
-- ["a","b","c","d","e"]array_contains()
判断array中是否包含某个元素
select array_contains(array('a', 'b', 'c', 'd', 'e'), 'c')
-- truesort_array()
将array中的元素排序
select sort_array(array('e', 'd', 'c', 'b', 'a'))
-- ["a","b","c","d","e"]struct函数
struct()
声明struct中的各属性。语法:struct(val1, val2, val3, …)
说明:根据输入的参数构建结构体struct类
select struct('a', 'b', 'c', 'd')
-- [{"col1":"a","col2":"b","col3":"c","col4":"d"}]named_struct()
声明struct的属性和值。语法:struct(name1, val1, name2, val2, name3, val3, …)
select named_struct('nn1', 'a', 'nn2','b', 'val1', 2)
-- [{"nn1":"a","nn2":"b","val1":2}]hive查询操作
hive 执行计划
select 语句语法如下:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ]
[LIMIT number]在学习sql的时候,sql语句有自己的执行顺序,在hive当中也有先后顺序,这非常重要。
基于MapReduce引擎
Map阶段:
- 执行from加载,进行表的查找与加载;
- 执行where过滤,进行条件过滤与筛选;
- 执行select查询:进行输出项的筛选;
- 执行group by分组:描述了分组后需要计算的函数;
- map端文件合并:map端本地溢出写文件的合并操作,每个map最终形成一个临时文件。
然后按列映射到对应的Reduce阶段:
- group by:对map端发送过来的数据进行分组并进行计算;
- select:最后过滤列用于输出结果;
- limit排序后进行结果输出到HDFS文件。
注意,以上顺序不是绝对的,会根据语句的不同,有所调整。
可以使用可以通过执行计划查看大概顺序,explain语句,与我们关系型数据库的用法一致。
常见的属性如下:
map端第一个操作肯定是加载表,所以就是 TableScan 表扫描操作,常见的属性:
- alias: 表名称 (这个显示的是表的别名,没起别名就是原名)
- Statistics: 表统计信息,包含表中数据条数,数据大小等(不一定准)
Select Operator: 选取操作,常见的属性 :
- expressions:需要的字段名称及字段类型
- outputColumnNames:输出的列名称
- Statistics:表统计信息,包含表中数据条数,数据大小等
Group By Operator:分组聚合操作,常见的属性:
- aggregations:显示聚合函数信息
- mode:聚合模式,值有 hash:随机聚合,就是hash partition;partial:局部聚合;final:最终聚合
- keys:分组的字段,如果没有分组,则没有此字段
- outputColumnNames:聚合之后输出列名
- Statistics: 表统计信息,包含分组聚合之后的数据条数,数据大小等
Reduce Output Operator:输出到reduce操作,常见属性:
- sort order:值为空 不排序;值为 + 正序排序,值为 – 倒序排序;值为 +- 排序的列为两列,第一列为正序,第二列为倒序
- Filter Operator:过滤操作,常见的属性:
- predicate:过滤条件,如sql语句中的where id>=2,则此处显示(id >= 2)
Map Join Operator:join 操作,常见的属性:
- condition map:join方式 ,如Inner Join 0 to 1w
- keys: join 的条件字段
- outputColumnNames: join 完成之后输出的字段
- Statistics: join 完成之后生成的数据条数,大小等
File Output Operator:文件输出操作,常见的属性
- compressed:是否压缩
- table:表的信息,包含输入输出文件格式化方式,序列化方式等
Fetch Operator 客户端获取数据操作,常见的属性:
- limit,值为 -1 表示不限制条数,其他值为限制的条数
复杂类型查询
STRUCT查询
想要查询STRUCT中的某个值,使用列名.属性名查询。
select struct_col.name from lmktest.testARRAY查询
想要查询ARRAY中的某个值,使用列名[下标]查询。
select array_col[0] from lmktest.testMAP查询
想要查询MAP中的某个值,使用列名[‘key_name’]查询。
select map_col['english'] from lmktest.test复合查询
想要查询复合结构中的某个值,也是使用嵌套的方式查询。
select union_col['english'][1] from lmktest.testJoin
内连接(inner join )
join 的语法与关系型数据库相同,这里不多介绍了。这里join是要走mapreduce的,使用的是map阶段进行join。mapjoin之前介绍过,是将小表的数据提前拿到放到执行的节点的内存中。
语法如下:
select *
from join_a a
join join_b b on a.id = b.id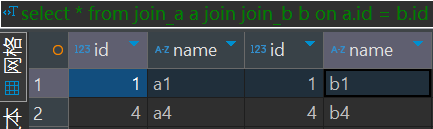
mapjoin也可以关闭,执行后就不适用mapjoin,还是走reduce。配置语句如下:
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;外连接
左外连接(left join)
普通左外也非常熟悉,不过多介绍。
语法如下:
select *
from join_a a
left join join_b b on a.id = b.id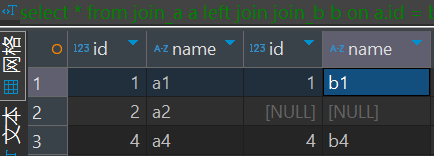
右外连接(right join)
普通右外也非常熟悉,不过多介绍。
语法如下:
select *
from join_a a
right join join_b b on a.id = b.id全外连接(full join)
全外连接也不多介绍了,与关系数据库都一致。
不等值连接
我们在使用join的时候,不一定非要用等值连接,连接条件也可以再加其他条件。这个与关系型数据库里是一样的,也是非常熟悉。
在关联条件中写条件和在where里面写条件是不同的,在关联条件中写,就是先过滤,后关联。where中是关联后筛选。
我个人的看法,关联条件使用也很灵活,有时候其实可以看做先做笛卡尔积,再对笛卡尔积中的数据进行筛选。(也不完全是,比如外连接是需要有某个表显示全部数据的,没有满足条件的数据,也要显示主表数据,匹配不到显示null)
比如:
select a.id aid, b.id bid, a.name aname, b.name bname
from join_a a
left join join_b b on a.id > b.id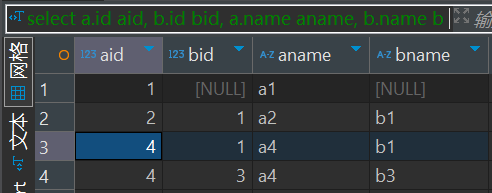
多表join
在多个表进行join操作的时候,需要注意的是,如果join的字段类型相同,只生成一个任务。join字段类型不同,就不一定生成一个任务了。
map端的join
mapjoin更适合有一个大表一个小表的情况,直接将小表的数据缓存到各个节点,省去reduce过程中对磁盘数据的读写操作。
一般join的时候左大右小
案例
这里我们还是使用之前的t_truckenter表作为大表,使用plantname表作为小表,使用code关联,获取小表中的plantname。
-- 将小表刷入内存中,默认是true
set hive.auto.convert.join=true;
set hive.ignore.mapjoin.hint=true;
-- 刷入内存表的大小(字节),根据自己的数据集加大
set hive.mapjoin.smalltable.filesize=2500000;
--设置太大也不会校验,所以要根据实际情况来设置
set hive.mapjoin.smalltable.filesize=2500000000000000;
--大表join 小表
select *
from t_truckenter tt
left join plantname pt on tt.code = pt.plant_code
limit 10join 注意事项
不要出现笛卡尔积,这是很熟悉的问题了,当然如果数据量小可以灵活使用进行交叉连接。
为了方式笛卡尔积出现,可以设置严格模式。
set hive.mapred.mode=strict;
-- 取消限制
set hive.mapred.mode=nonstrict;设置这个参数,可以限制以下情况:
- 限制执行可能形成笛卡尔积的SQL;
- partition表使用时不加分区;
- order by全局排序的时候不加limit的情况;
group by
group by的普通使用方式与关系数据库相同,不多介绍了。
grouping sets
可以在group by后面添加grouping sets。(a, b)就等于group by a, b ,()就等于不写group by直接聚合。
--GROUP BY a, b GROUPING SETS ((a,b))
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b GROUPING SETS ((a,b))
等于
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b
--GROUP BY a, b GROUPING SETS ((a,b), a)
--相当于又获取了按照a进行分组的统计数据,因为不包括b,所以b使用null补全
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b GROUPING SETS ((a,b), a)
等于
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b
UNION ALL
SELECT a, null, SUM(c) FROM tab1 GROUP BY a
--GROUP BY a, b GROUPING SETS (a,b)
SELECT a,b, SUM(c) FROM tab1 GROUP BY a, b GROUPING SETS (a,b)
等于
SELECT a, null, SUM(c) FROM tab1 GROUP BY a
UNION ALL
SELECT null, b, SUM(c) FROM tab1 GROUP BY b
--GROUP BY a, b GROUPING SETS ((a, b), a, b, ())
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b GROUPING SETS ((a, b), a, b, ())
等于
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b
UNION ALL
SELECT a, null, SUM(c) FROM tab1 GROUP BY a
UNION ALL
SELECT null, b, SUM(c) FROM tab1 GROUP BY b
UNION ALL
SELECT null, null, SUM(c) FROM tab1with cube
这个greouping sets可以适用于多个维度都需要统计,比如abcd四个维度排列组合统计,那么使用这种方式在grouping sets中写上所有的情况,就可以得到对应的结果集。
那么当我们需要所有情况的时候,如下
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b GROUPING SETS ((a, b), a, b, ())
等于
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b with cubewith rollup
grouping sets还有一种情况,比如按照顺序abcd,需要统计abcd、abc、ab、a、()这些情况的时候,从左到右每次都去掉最后一个。
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b GROUPING SETS ((a, b), a, ())
等于
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b with rollup排序
order by
会对输入做全局排序,因此只有一个reducer。
设置reduce个数没用。
order by 在hive.mapred.mode = strict 模式下 必须指定 limit 否则执行会报错。
select * from join_a order by id desc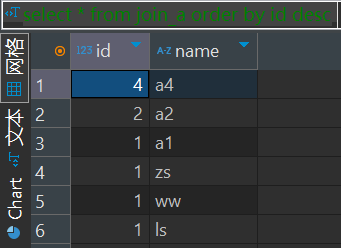
sort by
不是全局排序,其在数据进入reducer前完成排序。 因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1, 则sort by只保证每个reducer的输出有序,不保证全局有序。
insert overwrite local directory '/home/hadoop/test/output/sortby' select * from join_a sort by id desc可以看到分别生成两个文件,而且分别排序。如果直接显示查询的结果,那么排序是一段一段的,并不是全局降序。
多个reduce的情况返回结果如下:
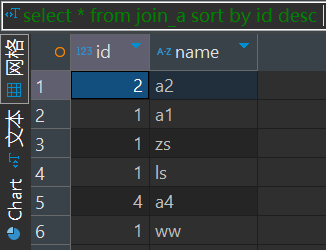
distribute by
distribute by可以让相同的字段去往同一个文件,sort by可以让每一个文件中的数据按照指定的字段进行排序,并且可以指定升序或者降序。
select * from join_a distribute by name多个reduce的情况返回结果如下:
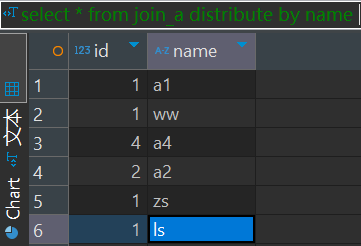
select * from join_a distribute by name sort by name多个reduce的情况返回结果如下:
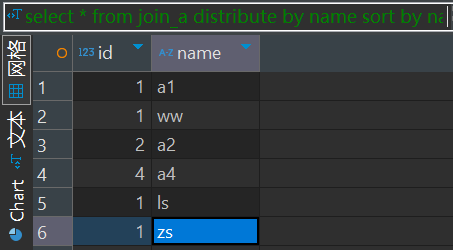
从结果可以看出,每个桶内是顺序排的,总体结果并不是。
DISTRIBUTE BY 仅保证相同值的数据落到同一 Reducer,但分桶的边界不保证顺序(例如分桶1可能包含 [100, 200],分桶2包含 [50, 99])。因此,即使分桶内部有序,分桶间的数据仍可能不连续。
cluster by
等价于distribute by sort by 但是只能升序。
select * from join_a cluster by name开窗函数
聚合函数(如sum()、avg()、max()等等)是针对定义的行集(组)执行聚集,每组只返回一个值。
窗口函数也是针对定义的行集(组)执行聚集,可为每组返回多个值。如既要显示聚集前的数据,又要显示聚集后的数据。
开窗函数在工作过程中使用很频繁,非常熟悉了,除非一些这涉及到边界、范围之类的用法比较少见。普通的开窗就不多记录了。
语法为:over( PARTITION BY (根据某条件分组,形成一个小组)….ORDER BY(再组内进行排序) …. )
案例1
计算任务数据出现次数占比
--方式1
select distinct count(1) over(partition by taskname) / count(1) over() * 100 || '%', taskname from ext_par_task1
--方式2
select * from
(select count(1) over(partition by taskname) / count(1) over() * 100 || '%' p,
taskname,
row_number() over(partition by taskname) rm
from ext_par_task1) v
where rm = 1
--方式3
SELECT
taskname,
COUNT(1) * 100.0 / SUM(COUNT(1)) OVER () || '%' AS p
FROM ext_par_task1
GROUP BY taskname;再计算占比的时候,我第一时间写的是第一个sql,因为老数据库使用这种方式多一点,写的比较少。对应的因为需要去重,所以肯定需要优化,这里我写了第二个sql,确实能快不少。
写完之后我去问ai还有没有更好的写法,他给我第三种写法,这个我确实没写过,因为在传统数据库是无法使用聚合函数嵌套的。
over
语法:
over (order by col1) --按照 col1 排序
over (partition by col1) --按照 col1 分区
over (partition by col1 order by col2) -- 按照 col1 分区,按照 col2 排序
--带有窗口范围
over (partition by col1 order by col2 ROWS 窗口范围) -- 在窗口范围内,按照 col1 分区,按照 col2 排序案例1
select *,count(1) over(order by age) from wt1 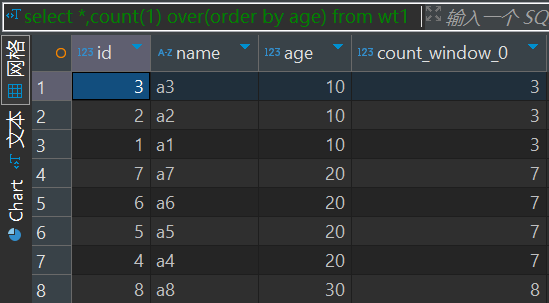
select *,count(1) over(partition by age order by id) from wt1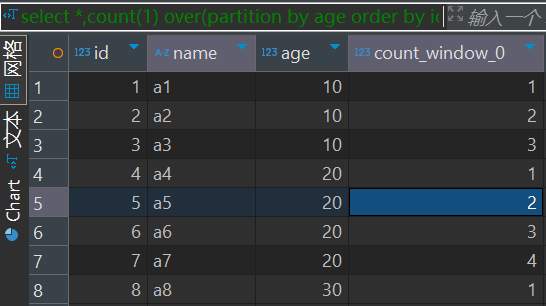
序列函数
row_number
会对所有数值,输出不同的序号,序号唯一且连续,如:1、2、3、4、5。
rank
会对相同数值,输出相同的序号,而且下一个序号间断,如:1、1、3、3、5。
dense_rank
会对相同数值,输出相同的序号,但下一个序号不间断,如:1、1、2、2、3。
案例1
-- 显示表头信息
set hive.cli.print.header=true;
select id,
name,
age,
sex,
row_number() over(partition by age order by sex desc),
rank() over(partition by age order by sex desc),
dense_rank() over(partition by age order by sex desc)
from wt1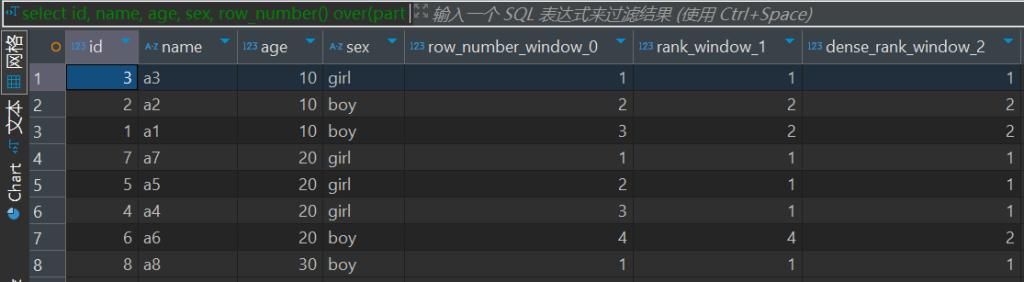
over中partition by和distribute by区别
partition by [key..] order by [key..]只能在窗口函数中使用,而distribute by [key…] sort by [key…]在窗口函数和select中都可以使用。
窗口函数中两者是没有区别的。
Window 函数
ROWS窗口函数中的行选择器,是基于物理行数来定义窗口范围的,通常按行位置计算。
--带有窗口范围
over (partition by col1 order by col2 ROWS 窗口范围) -- 在窗口范围内,按照 col1 分区,按照 col2 排序
rows between
[n|unbounded preceding]|[n|unbounded following]|[current row]
and
[n|unbounded preceding]|[n|unbounded following]|[current row]参数的解释如下:
- n行数
- unbounded不限行数
- preceding在前N行
- following在后N行
- current row当前行
使用的组合如下:
-- 前无限行到当前行
rows between unbounded preceding and current row
-- 前无限行到前1行
rows between unbounded preceding and 1 preceding
-- 前2 行到当前行,意味着计算三行,当前行加上前两行的范围
rows between 2 preceding and current row
-- 当前行到后2行
rows between current row and 2 following
-- 前无限行到后无限行
rows between unbounded preceding and unbounded following案例1:
查询sale_table表中当月销售额和近三个月的销售额。
select y, m, sales, sum(sales) over(order by y,m rows between 2 preceding and current row) from sale_table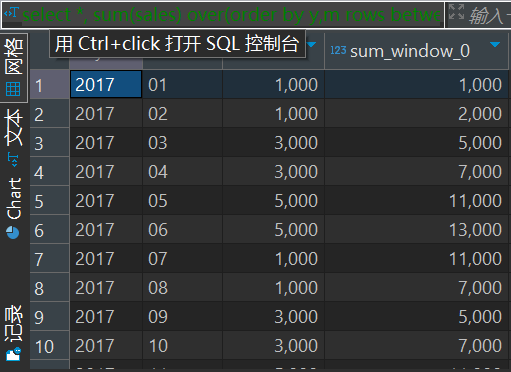
案例2:
查询sale_table表中当月销售额和今年年初到当月的销售额。
select y, m, sales, sum(sales) over(partition by y order by y,m) from sale_table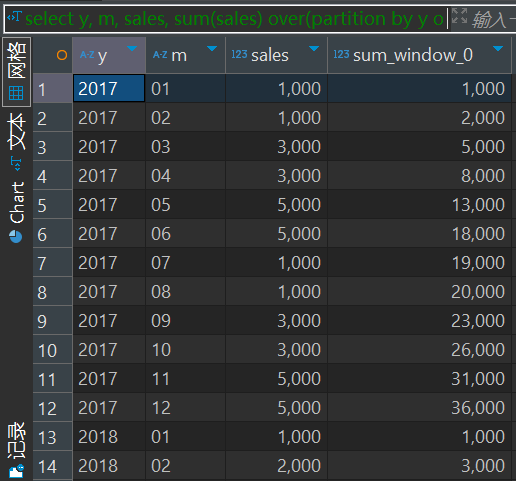
range
是基于排序列的值来定义窗口范围的,适用于需要按值范围进行窗口计算的场景。
rows适用于行的相对位置,而range适用于根据排序列的值范围来选择窗口数据。
range用于基于排序列的值范围来定义窗口,窗口的大小取决于排序列的值差异,而不是实际的行数。这意味着你可以根据数据中的数值差异来扩展窗口,而不是仅仅依赖于行数。
也就是说,如果相同的数值,那么他们的边界是相同的。
over(order by ) 默认的情况就是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
案例1
两种方式对比
select id,
value,
sum(value) over(order by value),
sum(value) over(order by value rows between unbounded preceding and current row)
from range_test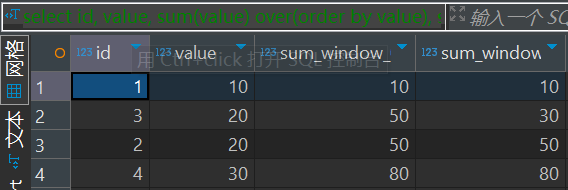
跨行取值函数
lag()/lead()
获取当前行的上一行/后一行,某个字段的值。
语法:LAG(column, offset, default)
lead(column, offset, default)
- column:要获取的列。
- offset:向前偏移的行数(默认为1)。
- default:当没有前一行时返回的默认值(默认为NULL)。
select *,
lag(login_ts, 2, '2021-10-10') over(partition by user_id order by login_ts)
from user_login_detail
user_id ip_address login_ts logout_ts lag_window_0
101 180.149.130 2021-09-21 08:00:00 2021-09-27 08:30:00 2021-10-10
101 180.149.130 2021-09-27 08:00:00 2021-09-27 08:30:00 2021-10-10
101 180.149.130 2021-09-28 09:00:00 2021-09-28 09:10:00 2021-09-21 08:00:00first_value()/last_value()
返回窗口范围内第一行/最后一行的指定列值。
语法:FIRST_VALUE(column, boolean)
LAST_VALUE(column, boolean)
- column:要获取的列。
- boolean:是否跳过null值,true就跳过,默认false。
select *,
FIRST_VALUE(login_ts, false) over(partition by user_id order by login_ts)
from user_login_detail
user_id ip_address login_ts logout_ts FIRST_VALUE
101 180.149.130.161 2021-09-21 08:00:00 2021-09-27 08:30:00 2021-09-21 08:00:00
101 180.149.130.161 2021-09-27 08:00:00 2021-09-27 08:30:00 2021-09-21 08:00:00
101 180.149.130.161 2021-09-28 09:00:00 2021-09-28 09:10:00 2021-09-21 08:00:00
101 180.149.130.161 2021-09-29 13:30:00 2021-09-29 13:50:00 2021-09-21 08:00:00结果集操作
union
并操作,合并两个结果集,并去重。
union all
并操作,合并两个结果集,不去重。
UDF函数
UDF的全称为user-defined function,用户定义函数。
如果要写的查询无法轻松地使用Hive提供的内置函数来表示,通过写UDF,Hive就可以方便地插入用户写的处理代码并在查询中使用它们,相当于在HQL(Hive SQL)中自定义一些函数。
UDF、UDAF、UDTF区别
- UDF (user defined function) 用户自定义函数:对单行记录进行处理得到单行的结果,一对一;
- UDAF (user defined aggregation function) 用户自定义聚合函数,多行记录汇总成一行,常用于聚合函数,多对一;
- UDTF:单行记录转换成多行记录,多对多;
UDF
创建使用函数流程
- 自定义一个Java类
- 继承类 GenericUDF
- 重写继承的方法,将程序build为jar包
- 在hive执行创建模板函数
- hql中使用
案例
能将国家编码转成中文国家名的UDF函数
首先上传code对应名称的数据
首先再idea里创建项目,在pom文件中添加以下内容并导包。
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-cli</artifactId>
<version>3.1.3</version>
</dependency>编写代码
创建自定义UDF类并继承hive的GenericUDF 类
首先把数据读到缓存里,然后选择性实现 5个 方法。
//可选,该方法中可以通过context.getJobConf()获取job执行时候的Configuration;
//可以通过Configuration传递参数值
public void configure(MapredContext context) {}
//必选,该方法用于函数初始化操作,并定义函数的返回值类型,判断传入参数的类型;
public ObjectInspector initialize(ObjectInspector[] arguments)
//必选,函数处理的核心方法,用途和UDF中的evaluate一样,每一行都调用一次;
public Object evaluate(DeferredObject[] args){}
//必选,显示函数的帮助信息
public String getDisplayString(String[] children)
//可选,map完成后,执行关闭操作
public void close(){}实现代码如下:
package com.lmk;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.lazy.LazyString;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
public class CountryCode2CountryNameUDF extends GenericUDF {
// 准备一个map来存放国家编码和中文名
static Map<String, String> map = new HashMap<String, String>();
static {
try {
// 读取resources目录下的国家编码文件
InputStream in = CountryCode2CountryNameUDF.class.getResourceAsStream("/country.dict");
// 封装成字符流,方便按行读取数据
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
// 变量,用来存放读取的数据
String line = null;
while((line = reader.readLine()) != null ){
String[] split = line.split("\t");
String code = split[0];
String name = split[1];
map.put(code, name);
}
}catch (Exception e){
e.printStackTrace();
}
}
@Override
// 初始化方法,用来定义输入的参数类型和输出的参数类型
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
// 校验参数个数
if(objectInspectors.length != 1){
throw new UDFArgumentException("输入的参数必须是一个");
}
ObjectInspector inspector = objectInspectors[0];
// 校验参数类型
// 校验大类, getCategory获取分类, Category就是获取我们的基本类型
if(! inspector.getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentException("输入的参数必须是PRIMITIVE类型");
}
// 校验小类
if(! inspector.getTypeName().equalsIgnoreCase(PrimitiveObjectInspector.PrimitiveCategory.STRING.name())){
throw new UDFArgumentException("输入的参数必须是PRIMITIVE类型下的STRING类型");
}
// 确定输出类型
return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
Text output = new Text();
@Override
// 核心方法,将来输入一行数据就会调用一次这个方法,用来编写核心业务逻辑
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
// 获取输入进来的参数
Object obj = deferredObjects[0].get();
// 在hive中string类型有三种,分别是 LazyString Text String
String code = null;
if (obj instanceof LazyString){
LazyString lz = (LazyString) obj;
Text t = lz.getWritableObject();
code = t.toString();
}else if (obj instanceof Text){
Text t = (Text) obj;
code = t.toString();
}else{
code = (String)obj;
}
// 翻译国家编码
String countryname = map.get(code);
output.set(countryname);
return output;
}
@Override
// 打印帮助信息的方法
public String getDisplayString(String[] strings) {
return Arrays.toString(strings);
}
}
集群运行自定义udf函数
- 首先给项目打成jar包;
- 进入hive控制台,然后使用add jar把刚才打的jar包添加进去;
格式
add jar [local_jar_path];
-- 例如
add jar /home/hadoop/test/Hive_Pro.jar如果上传的jar包运行时报错,当你修改完再次上传时,要重启hive客户端,再重新添加jar,运行。
-- 创建自定义函数,temporary 代表临时,退出客户端失效
create temporary function fanyi as 'com.lmk.CountryCode2CountryNameUDF'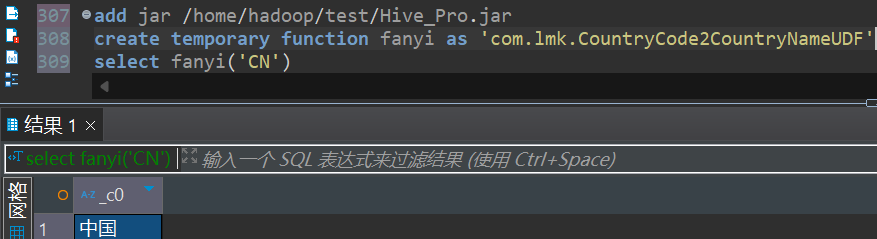
UDTF
UDTF(User-Defined Table-Generating Functions) :接受零个或者多个输入,然后产生多列或者多行输出。
案例
需求如下
id name_nickname
1 name1#n1;name2#n2
2 name3#n3;name4#n4;name5#n5
将以上文件数据多行多列输出
id name nickname
1 name1 n1
1 name2 n2
2 name3 n3
2 name4 n4
2 name5 n5UDTF编写流程如下:
- 继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现initialize, process, close三个方法。
- UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
- 初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每调用一次forward()产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
- 最后close()方法调用,对需要清理的方法进行清理。
代码如下:
package com.lmk;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.lazy.LazyString;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
import java.util.ArrayList;
import java.util.List;
public class SplitUDTF extends GenericUDTF {
@Override
public StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {
// 校验函数输入参数和 设置函数返回值类型
// 校验入参个数
if(argOIs.length != 1){
throw new UDFArgumentException("输入的参数必须是一个");
}
ObjectInspector inspector = argOIs[0];
// 校验参数的大类
// 大类有: PRIMITIVE(基本类型), LIST, MAP, STRUCT, UNION
if(! inspector.getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentException("输入的参数必须是PRIMITIVE类型");
}
// 校验参数的小类
// VOID, BOOLEAN, BYTE, SHORT, INT, LONG, FLOAT, DOUBLE, STRING,
// DATE, TIMESTAMP, BINARY, DECIMAL, VARCHAR, CHAR, INTERVAL_YEAR_MONTH, INTERVAL_DAY_TIME,
// UNKNOWN
if(! inspector.getTypeName().equalsIgnoreCase(PrimitiveObjectInspector.PrimitiveCategory.STRING.name())){
throw new UDFArgumentException("输入的参数必须是PRIMITIVE类型下的STRING类型");
}
// 设置函数返回值类型(struct<name:string, nickname:string>)
// struct内部字段的名称
List<String> names = new ArrayList<String>();
names.add("name");
names.add("nickname");
// struct内部字段的名称对应的类型
List<ObjectInspector> inspectors = new ArrayList<ObjectInspector>();
inspectors.add(PrimitiveObjectInspectorFactory.writableStringObjectInspector);
inspectors.add(PrimitiveObjectInspectorFactory.writableStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(names, inspectors);
}
Object[] outputs = new Object[]{new Text(), new Text()};
@Override
public void process(Object[] objects) throws HiveException {
Object obj = objects[0];
// 在hive中string类型有三种,分别是 LazyString Text String
String data = null;
if (obj instanceof LazyString){
LazyString lz = (LazyString) obj;
Text t = lz.getWritableObject();
data = t.toString();
}else if (obj instanceof Text){
Text t = (Text) obj;
data = t.toString();
}else{
data = (String)obj;
}
String[] arr1 = data.split(";");
for (String s : arr1) {
String[] arr2 = s.split("#");
String name = arr2[0];
String nickname = arr2[1];
((Text)outputs[0]).set(name);
((Text)outputs[1]).set(nickname);
forward(outputs);
}
}
@Override
public void close() throws HiveException {
}
}
测试结果如下:
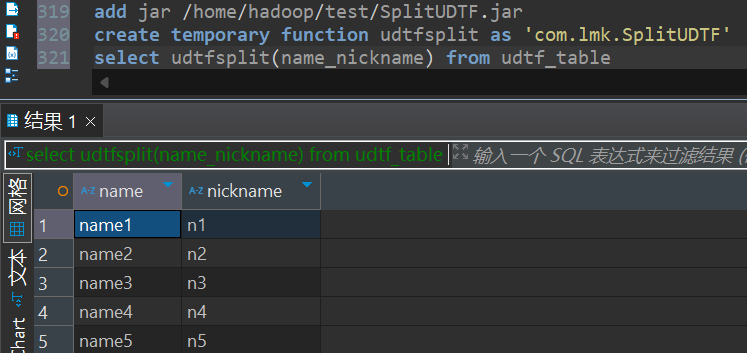
当然也可以给字段起别名
-- 注意as不能省略
select udtfsplit(name_nickname) as (n1, n2) from udtf_tableUDTF的两种使用方法
两种使用方式分别为:
- 直接放到select后面
- 搭配lateral view一起使用
直接select中使用
上面的案例就是使用这种方式使用的,语法格式:
-- 可以自定义表头字段名称
select udtf_func(properties) as (col1,col2) from tablename;
-- 用UDTF代码里写的字段名称
select udtf_func(properties) from tablename;注意:
UDTF函数不可以使用的场景如下:
1. 不可以添加其他字段使用
-- 错误案例
select id, udtf_split(name_nickname) from udtf_table;2. 不可以嵌套调用
-- 错误案例
select udtf_split(udtf_split(strsplit)) from udtftest;3. 不可以和group by/cluster by/distribute by/sort by一起使用
-- 错误案例
select udtf_split(strsplit) as (col1,col2) from udtftest group by col1, col2;lateral view
通过Lateral view可以方便的将UDTF得到的行转列的结果集,合在一起提供服务。
lateral view用于和UDTF一起使用,为了解决UDTF不允许再select字段的问题。
语法如下:
select u1.id, nn.n1, nn.n2
from udtf_table u1
lateral view udtfsplit(name_nickname) nn as n1, n2- 首先udtf_table表每行调用udtfsplit,会把一行拆分成一或者多行
- 再把结果组合,产生一个支持别名表nn的虚拟表
详情可以查看sparksql中也有个案例
LATERAL VIEW 就像一个虚拟的 JOIN,它能将一个包含数组或 Map 的行“展开”(explode)成多行,然后将这些展开后的新行与原始行的数据“连接”起来。
| id | title | actor_list | + | (新列 actor) |
|---|---|---|---|---|
| 1 | wjd | ldh|lcw|zzw | ldh | |
| 1 | wjd | ldh|lcw|zzw | lcw | |
| 1 | wjd | ldh|lcw|zzw | zzw |
UDAF
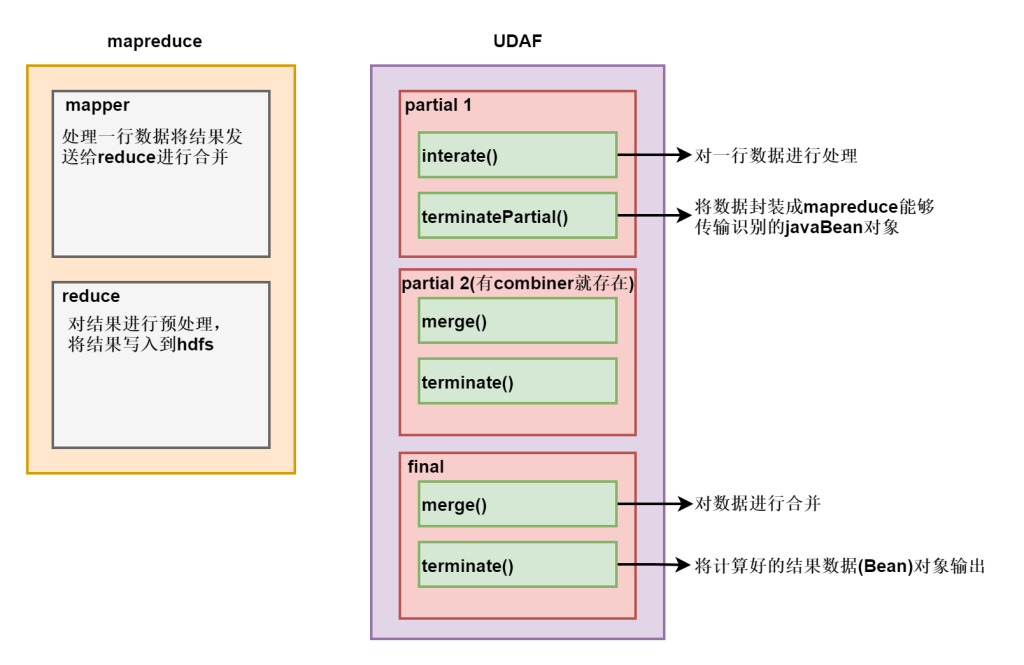
一般情况下,完整的UDAF逻辑是一个mapreduce过程:
如果有mapper和reducer,就会经历PARTIAL1(mapper),FINAL(reducer);
关键函数及作用
PARTIAL1
PARTIAL1: 这个是mapreduce的map阶段:从原始数据到部分数据聚合,将会调用iterate()和terminatePartial()
iterate():把mapper中每行的数据汇总到一起,放到一个bean里面,这个bean在mapper和reducer的内部。
amt bean对象
0528 100 100
0529 150 250
0530 50 300
0531 200 500
0601 100 600 ---》 bean(600)
0520 100 100
0521 100 200
0522 200 400 ---》 bean(400)terminatePartial() : 把带有中间结果的bean转换成能实现序列化在mapper 和 reducer 端传输的对象。
bean(600) --> IntWritable(600)
bean(400) --> IntWritable(400)FINAL
FINAL: mapreduce的reduce阶段:从部分数据的聚合到完全聚合,将会调用merge()和terminate()
merge(): reduce端把mapper端输出的数据进行全局合并,把合并的结果放到bean里
bean
IntWritable(600) bean(600)
IntWritable(400) bean(1000) ---> bean(1000)terminate() :把bean里的全局聚合结果,转换成能实现序列化的输出对象
bean(1000) ---》 IntWritable(1000)案例
流程
- 自定义UDAF类,需要继承AbstractGenericUDAFResolver;
- 自定义Evaluator类,需要继承GenericUDAFEvaluator,真正实现UDAF的逻辑;
- 自定义bean类,需要继承 AbstractAggregationBuffer,用于在mapper或reducer内部传递数据;
代码如下:
package com.lmk;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.lazy.LazyInteger;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.io.IntWritable;
public class SumUDAF extends AbstractGenericUDAFResolver {
@Override
// 对输入参数的类型进行校验的方法
public GenericUDAFEvaluator getEvaluator(TypeInfo[] info) throws SemanticException {
if (info.length != 1) {
throw new UDFArgumentException("输入的参数必须是一个");
}
TypeInfo typeInfo = info[0];
if (!typeInfo.getCategory().equals(ObjectInspector.Category.PRIMITIVE)) {
throw new UDFArgumentException("输入的参数必须是PRIMITIVE类型");
}
if (!typeInfo.getTypeName().equalsIgnoreCase(PrimitiveObjectInspector.PrimitiveCategory.INT.name())) {
throw new UDFArgumentException("输入的参数必须是PRIMITIVE类型下的INT类型");
}
// 返回能实现sum的核心算法类对象实例
return new SumEvaluator();
}
// 实现sum的核心算法类
public static class SumEvaluator extends GenericUDAFEvaluator {
// 定义一个javabean对象,用于存储中间结果
public static class SumAgg extends AbstractAggregationBuffer {
// 统计的中间结果
private int sum;
public int getSum() {
return sum;
}
public void setSum(int sum) {
this.sum = sum;
}
}
// 由于sum函数mapper端和reduce端输出都是IntWritable,所以定义一个输出对象即可
IntWritable outputs = new IntWritable();
@Override
// 用来保存中间结果的javabean对象
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
return new SumAgg();
}
@Override
// 用来对中间结果进行重置
public void reset(AggregationBuffer aggregationBuffer) throws HiveException {
SumAgg SumAgg = (SumAgg)aggregationBuffer;
SumAgg.setSum(0);
}
@Override
// 来一行数据就会调用一次这个方法,在此方法中对数据进行累加,并保存到javabean对象中
public void iterate(AggregationBuffer aggregationBuffer, Object[] objects) throws HiveException {
Object obj = objects[0];
int amt = 0;
if (obj instanceof LazyInteger){
LazyInteger lz = (LazyInteger) obj;
IntWritable writableObject = lz.getWritableObject();
amt = writableObject.get();
}else if (obj instanceof IntWritable){
IntWritable writableObject = (IntWritable) obj;
amt = writableObject.get();
}else{
amt = (Integer)obj;
}
SumAgg sumAgg = (SumAgg) aggregationBuffer;
sumAgg.setSum(sumAgg.getSum() + amt);
}
@Override
public Object terminatePartial(AggregationBuffer aggregationBuffer) throws HiveException {
SumAgg SumAgg = (SumAgg) aggregationBuffer;
outputs.set(SumAgg.getSum());
return outputs;
}
// reduce阶段
@Override
// 输入 Intw 600 Intw 400
public void merge(AggregationBuffer aggregationBuffer, Object o) throws HiveException {
int amt = 0;
if (o instanceof LazyInteger){
LazyInteger lz = (LazyInteger) o;
IntWritable writableObject = lz.getWritableObject();
amt = writableObject.get();
}else if (o instanceof IntWritable){
IntWritable writableObject = (IntWritable) o;
amt = writableObject.get();
}else{
amt = (Integer)o;
}
SumAgg sumAgg = (SumAgg) aggregationBuffer;
sumAgg.setSum(sumAgg.getSum() + amt);
}
@Override
public Object terminate(AggregationBuffer aggregationBuffer) throws HiveException {
SumAgg sumAgg = (SumAgg) aggregationBuffer;
outputs.set(sumAgg.getSum());
return outputs;
}
@Override
// 确定返回类型
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
super.init(m, parameters);
// Mode m 原本需要判断每个阶段返回对应的类型,因为我们这里mapper和reduce返回类型都是一样的,所以不需要判断了
return PrimitiveObjectInspectorFactory.writableIntObjectInspector;
}
}
}
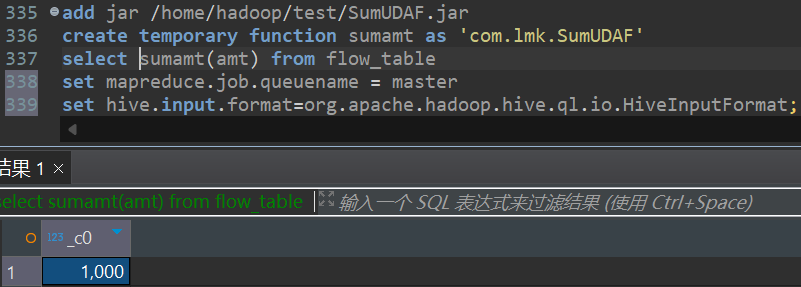
测试及结果:
hive默认会将输入小文件合并,如果不想合并的话可以执行下面参数
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;