
spark streaming介绍
背景
随着大数据技术的不断发展,人们对于大数据的实时性处理要求也在不断提高,传统的 MapReduce 等批处理框架在某些特定领域,例如实时用户推荐、用户行为分析这些应用场景上逐渐不能满足人们对实时性的需求,因此诞生了一批如 S3、Storm 这样的流式分析、实时计算框架。Spark 由于其内部优秀的调度机制、快速的分布式计算能力,所以能够以极快的速度进行迭代计算。正是由于具有这样的优势,Spark 能够在某些程度上进行实时处理,Spark Streaming 正是构建在此之上的流式框架。
Spark Streaming 设计
Spark Streaming 是 Spark 的核心组件之一,它可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafka、ZeroMQ等消息队列以及TCP sockets或者目录文件从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库或显示在仪表盘里。

Spark Streaming 的基本原理是将实时输入数据流以时间片(通常在0.5~2秒之间)为单位进行拆分,然后采用 Spark 引擎以类似批处理的方式处理每个时间片数据,执行流程如下图所示:
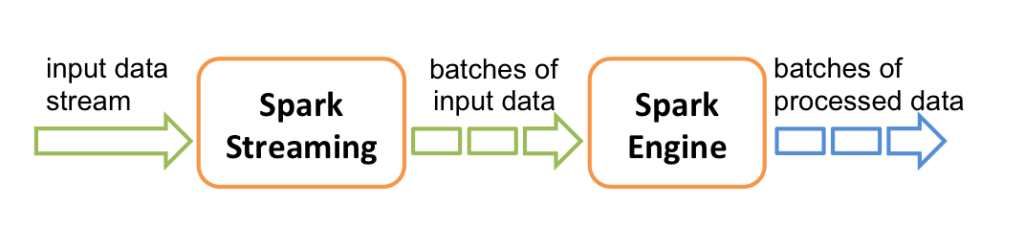
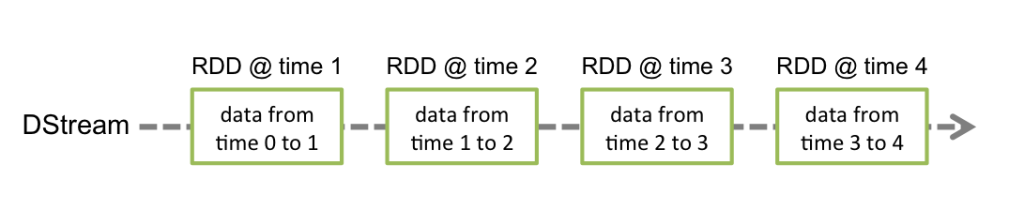
Discretized Stream 或 DStream 是Spark Streaming提供的基本抽象。它表示一个连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不变的分布式数据集的抽象。DStream中的每个RDD都包含来自特定间隔的数据,如下图所示。
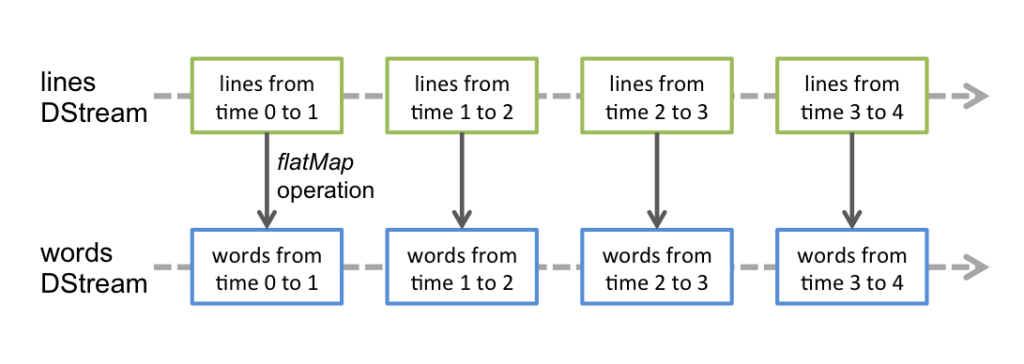
在DStream上执行的任何操作都转换为对基础RDD的操作。例如,最简单的将一行句子转换为单词的例子中,flatMap操作应用于行DStream中的每个RDD,以生成单词DStream的RDD。如下图所示:
Spark Streaming 与 flink的对比
| 对比点 | Flink | Spark Streaming |
|---|---|---|
| 实时计算模型 | 纯实时,来一条数据,处理一条数据 | 准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 |
| 实时计算延迟度 | 毫秒级 | 秒级 |
| 吞吐量 | 高 | 高(移动计算不移动数据) |
- 处理模型以及延迟
- SparkStreaming 无法实现毫秒级的流计算。Spark Streaming可以在一个短暂的时间窗口里面处理多条(batches)Event,并且 SparkStreaming 将流数据分解为一系列批处理作业,在这个过程中会产生多个spark 作业,每段数据的处理都会经过DAG图分解、任务调度等过程,需要一定的额开销。
- 容错和数据保证
- 然而两者的都有容错时候的数据保证,Spark Streaming的容错为有状态的计算提供了更好的支持。在Storm中,每条记录在系统的移动过程中都需要被标记跟踪,所以Storm只能保证每条记录最少被处理一次,但是允许从错误状态恢复时被处理多次。这就意味着可变更的状态可能被更新两次从而导致结果不正确。
- 另一方面,Spark Streaming仅仅需要在批处理级别对记录进行追踪,所以他能保证每个批处理记录仅仅被处理一次,即使是node节点挂掉。
- 批处理框架集成
- Spark Streaming的一个很棒的特性就是它是在Spark框架上运行的。这样你就可以使用spark的批处理代码一样来写Spark Streaming程序,或者是在Spark中交互查询比如spark-sql。这就减少了单独编写流处理程序和历史数据处理程序。
- 生产支持
- 两者都可以在各自的集群框架中运行,但是Storm可以在Mesos上运行, 而Spark Streaming可以在YARN和Mesos上运行。
- Storm已经出现好多年了,而且自从2011年开始就在Twitter内部生产环境中使用,还有其他一些公司。
架构及运行流程
架构
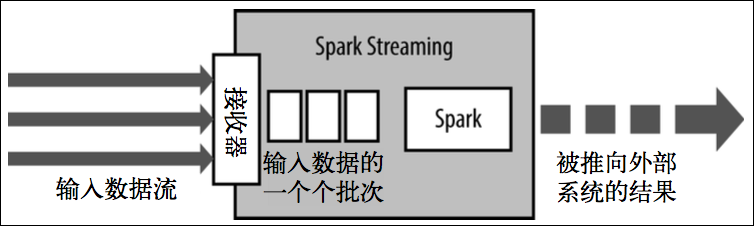
Spark Streaming使用“微批次”的架构,把流试计算当成一系列连接的小规模批处理来对待,Spark Streaming从各种输入源中读取数据,并把数据分成小组的批次,新的批次按均匀的时间间隔创建出来,在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中,在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的,批次间隔一般设在500毫秒到几秒之间,由应用开发者配置,每个输出批次都会形成一个RDD,以Spark作业的方式处理并生成其他的RDD。并能将处理结果按批次的方式传给外部系统。
在本地运行Spark Streaming程序时,请勿使用“ local”或“ local [1]”作为主URL。这两种方式均意味着仅一个线程将用于本地运行任务。如果您使用的是基于接收器的输入DStream(例如套接字,Kafka,Flume等),则将使用单个线程来运行接收器,而不会留下任何线程来处理接收到的数据。因此,在本地运行时,请始终使用“ local [ n ]”作为主URL,其中n >要运行的接收器数量。
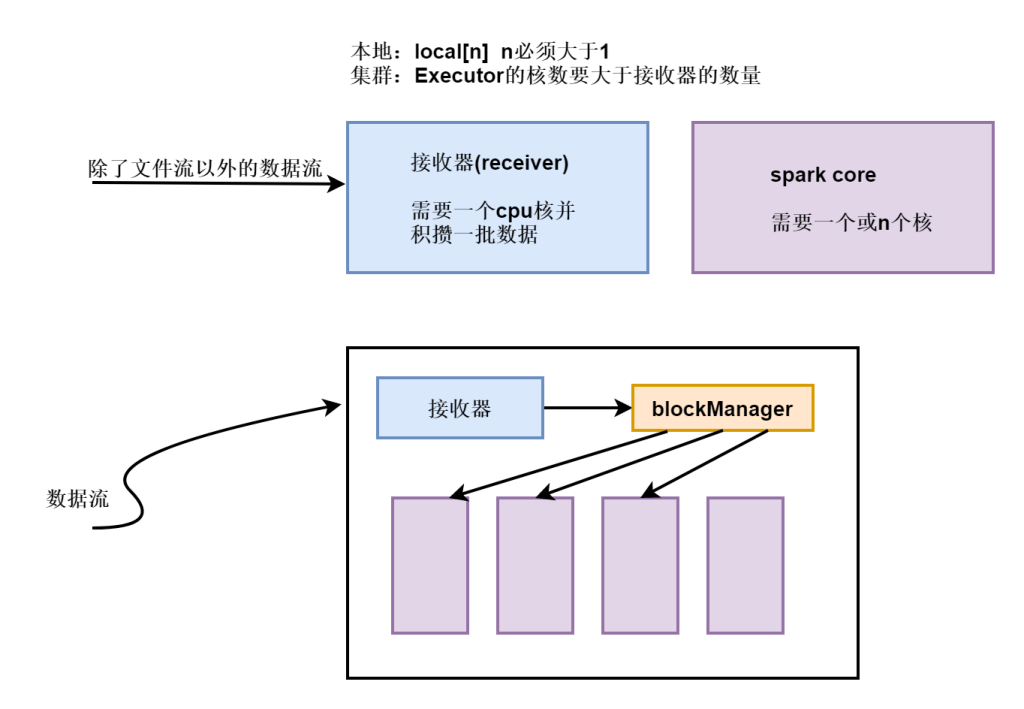
运行流程
SparkStreaming 分为Driver端 和 Client端。
Driver端为StreamingContext实例,包括JobScheduler 、DStreamGraph 等;
Client端为 ReceiverSupervisor 和 Receiver。
SparkStreaming 进行流数据处理的大概步骤:
- 启动流处理引擎;
- 接收及存储流数据;
- 处理流数据;
- 输出处理结果;
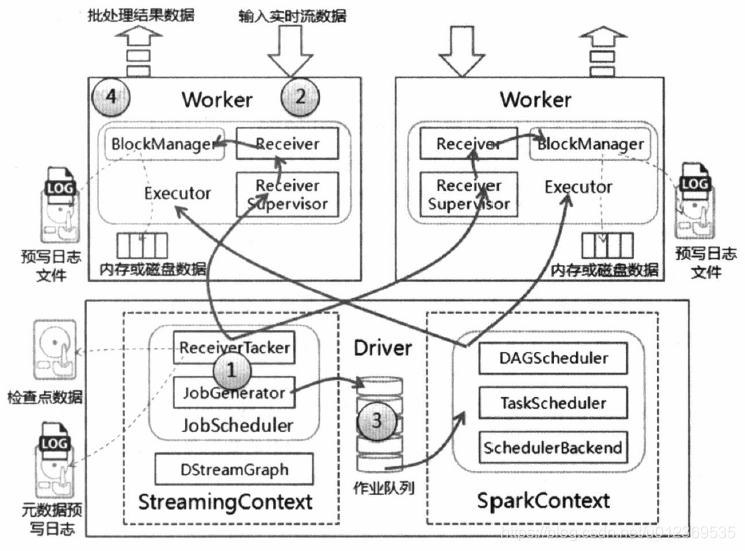
StreamingContext 初始化时,会初始化JobScheduler 、DStreamGraph 实例。其中:
DStreamGraph:存放DStream 间的依赖关系,就像RDD的依赖关系一样;
JobScheduler:JobScheduler 是SparkStreaming 的 Job 总调度者。它 包括 ReceiverTracker 和 JobGenerator。
ReceiverTacker:它负责启动、管理各个executor的 流数据接收器(Receiver)及管理各个Receiver 接收到的数据。当ReceiverTacker启动过程中,会初始化executor 的 流数据接收管理器(ReceiverSupervisor),再由它启动流数据接收器(Receiver)。
JobGenerator:它是批处理作业生成器,内部维护一个定时器,定时处理批次的数据生成作业。
step2:接收及存储流数据
当Receiver 启动后,连续不断的接收实时流数据,根据传过来的数据大小进行判断,如果数据小,就攒多条数据成一块,进行块存储;如果数据大,则一条数据成一块,进行块存储。
块存储时会根据是否设置预写日志文件分成两种方式:
- 不设置预写日志文件,就直接写入对应Worker的内存或磁盘。
- 设置预写日志文件,会同时写入对应Worker的内存或磁盘 和 容错文件系统(比如hdfs),设置预写日志文件主要是为了容错,在当前节点出故障后,还可以恢复。
数据存储完毕后,ReceiverSupervisor 会将数据存储的元信息(streamId、数据位置、数据条数、数据 size 等信息)上报给 Driver端的 ReceiverTacker。ReceiverTacker 维护收到的元数据信息。
step3:处理流数据
在 StreamingContext 的 JobGenerator 中维护一个定时器,该定时器在批处理时间到来时会进行生成作业的操作。在操作中进行如下操作:
- 通知 ReceiverTacker 将接收到到的数据进行提交,在提交时采用 synchronize 关键字进行处理,保证每条数据被划入一个且只被划入一个批次中。
- 要求 DStreamGraph 根据 DStream 依赖关系生成作业序列 Seq[Job]。
- 从 ReceiverTacker 中获取本批次数据的元数据。
- 把批处理时间、作业序列 Seq[Job] 和本批次数据的元数据包装为 JobSet。调用JobScheduler.submitJobSet(JobSet) 提交给 JobScheduler,JobScheduler 将把这些作业放到 作业队列,Spark 核心 在从作业队列中取出执行作业任务。由于中间有 队列,所以速度非常快。
- 当提交本批次作业结束,根据 是否设置checkpoint,如果设置checkpoint,SparkStreaming 对整个系统做checkpoint。
step4:输出处理结果
由于数据的处理有Spark核心来完成,因此处理的结果会从Spark核心中直接输出至外部系统,如数据库或者文件系统等,同时输出的数据也可以直接被外部系统所使用。由于实时流数据的数据源源不断的流入,Spark会周而复始的进行数据的计算,相应也会持续输出处理结果。
DStream
DStream 输入源
基本输入源:文件系统 和 Socket。
高级输入源:
| Source | Artifact |
| Kafka | spark-streaming-kafka_2.11 |
| Flume | spark-streaming-flume_2.11 |
| Kinesis | spark-streaming-kinesis-asl_2.11 |
| spark-streaming-twitter_2.11 | |
| ZeroMQ | spark-streaming-zeromq_2.11 |
| MQTT | spark-streaming-mqtt_2.11 |
DStream 转换操作
DStream 无状态转换操作
对于DStream 无状态转换操作而言,不会记录历史状态信息,每次对新的批次数据进行处理时,只会记录当前批次数据的状态。OLDDStream -> NEWDStream
| 转换 | 描述 |
| map(func) | 源 DStream的每个元素通过函数func返回一个新的DStream |
| flatMap(func) | 类似与map操作,不同的是每个输入元素可以被映射出0或者更多的输出元素 |
| filter(func) | 在源DStream上选择func函数返回仅为true的元素,最终返回一个新的DStream |
| repartition(numPartitions) | 通过输入的参数numPartitions的值来改变DStream的分区大小 |
| union(otherStream) | 返回一个包含源DStream与其他 DStream的元素合并后的新DStream |
| count() | 对源DStream内部的所含有的RDD的元素数量进行计数,返回一个内部的RDD只包含一个元素的DStreaam |
| reduce(func) | 使用函数func(有两个参数并返回一个结果)将源DStream 中每个RDD的元素进行聚合操作,返回一个内部所包含的RDD只有一个元素的新DStream。 |
| countByValue() | 计算DStream中每个RDD内的元素出现的频次并返回新的DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素出现的频次。 |
| reduceByKey(func, [numTasks]) | 当一个类型为(K,V)键值对的DStream被调用的时候,返回类型为类型为(K,V)键值对的新 DStream,其中每个键的值V都是使用聚合函数func汇总。注意:默认情况下,使用 Spark的默认并行度提交任务(本地模式下并行度为2,集群模式下位8),可以通过配置numTasks设置不同的并行任务数。 |
| join(otherStream, [numTasks]) | 当被调用类型分别为(K,V)和(K,W)键值对的2个DStream时,返回类型为(K,(V,W))键值对的一个新 DSTREAM。 |
| cogroup(otherStream, [numTasks]) | 当被调用的两个DStream分别含有(K, V) 和(K, W)键值对时,返回一个(K, Seq[V], Seq[W])类型的新的DStream。 |
| foreachRDD | 获取每个RDD |
| transform(func) | 通过对源DStream的每RDD应用RDD-to-RDD函数返回一个新的DStream,这可以用来在DStream做任意RDD操作。 |

val dstream2 = dstream1.flatMap(.split(" ")).map((,1)).reduceByKey(_ + _)
// 通过 transform 将 dstream 转成 rdd, 然后 通过rdd 的 转换进行单词统计,然后把最终的rdd 在转换成 dstream.
val dstream2 = dstream1.transform(rdd =>{
val name = “hehe” // driver端运行
println(s“name:${name}”) // driver端运行
rddnew = rdd.flatMap(.split(" ")).map((,1)).reduceByKey(_ + _)
rddnew
})在无状态转换算子里面:
transform(func) 是个特殊的算子,它函数内部是 RDD;而其他的算子内部是对应的元素类型,跟RDD算子里面的类型是一样的。
DStream 有状态转换操作
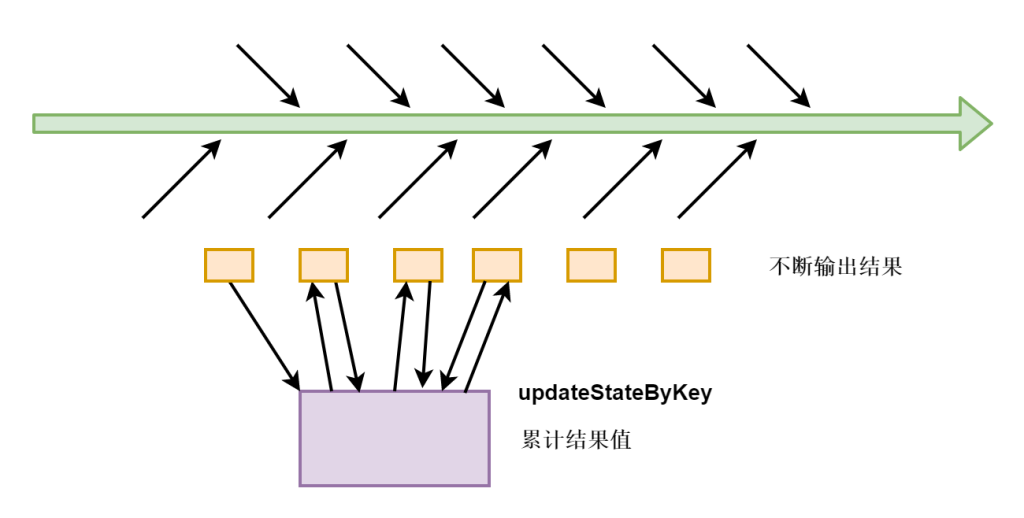
DStream 有状态转换操作包括 滑动窗口转换操作 和 updateStateByKey 操作。
滑动窗口转换操作
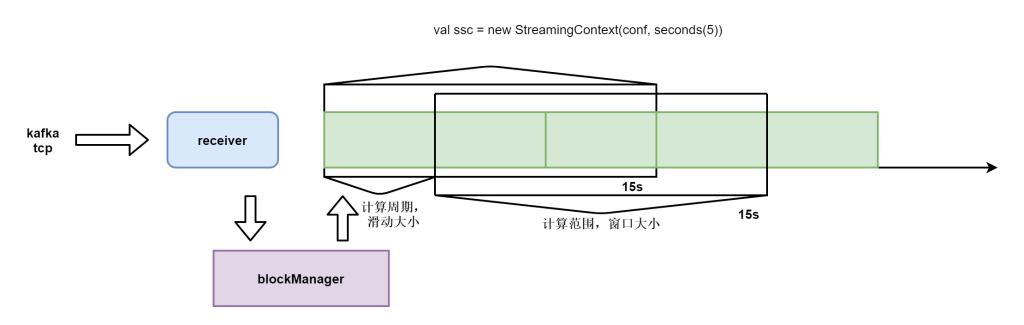
对于窗口操作,批处理间隔、窗口间隔和滑动间隔是非常重要的三个时间概念,是理解窗口操作的关键所在。
批处理间隔:
在Spark Streaming中,数据处理是按批进行的,而数据采集是逐条进行的,因此在Spark Streaming中会先设置好批处理间隔(batch duration),当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给系统去处理。
窗口间隔:
对于窗口操作而言,在其窗口内部会有N个批处理数据,批处理数据的大小由窗口间隔(window duration)决定,而窗口间隔指的就是窗口的持续时间,在窗口操作中,只有窗口的长度满足了才会触发批数据的处理。
滑动间隔(slide duration):
它指的是经过多长时间窗口滑动一次形成新的窗口,滑动窗口默认情况下和批次间隔的相同,而窗口间隔一般设置的要比它们两个大。在这里必须注意的一点是滑动间隔和窗口间隔的大小一定得设置为批处理间隔的整数倍。
滑动间隔 == 窗口间隔,正好不重复,也不漏数据。
滑动间隔 > 窗口间隔,会漏数据。
滑动间隔、窗口间隔 一定是批处理间隔的整数倍。
Spark Streaming 还提供了窗口的计算,它允许你通过滑动窗口对数据进行转换,窗口转换操作如下:
| 转换 | 描述 |
|---|---|
| window(windowLength, slideInterval) | 返回一个基于源DStream的窗口批次计算后得到新的DStream。 |
| countByWindow(windowLength,slideInterval) | 返回基于滑动窗口的DStream中的元素的数量。 |
| reduceByWindow(func,windowLength,slideInterval) | 基于滑动窗口对源DStream中的元素进行聚合操作,得到一个新的DStream。 |
| reduceByKeyAndWindow(func,windowLength,slideInterval,[numTasks]) | 基于滑动窗口对(K,V)键值对类型的DStream中的值按K使用聚合函数func进行聚合操作,得到一个新的DStream。可以进行repartition操作。 |
| reduceByKeyAndWindow(func,invFunc,windowLength, slideInterval, [numTasks]) | 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作(func),并对离开窗口的老数据进行“逆向reduce” 操作(invFunc)。但是,只能用于“可逆的reduce函数”必须启用“检查点”才能使用此操作 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 基于滑动窗口计算源DStream中每个RDD内每个元素出现的频次并返回DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素频次。与countByValue一样,reduce任务的数量可以通过一个可选参数进行配置。 |
UpdateStateByKey 原语用于记录历史记录,Word Count 示例中就用到了该特性。若不用 UpdateStateByKey 来更新状态,那么每次数据进来后分析完成,结果输出后将不再保存。如输入:hello world,结果则为:(hello,1)(world,1),然后输入 hello spark,结果则为 (hello,1)(spark,1)。也就是不会保留上一次数据处理的结果。
使用 UpdateStateByKey 原语用于需要记录的 State,可以为任意类型,如上例中即为 Optional类型。
返回一个新状态的DStream,其中每个键的状态是根据键的前一个状态和键的新值应用给定函数func后的更新。这个方法可以被用来维持每个键的任何状态数据。
DStream 输出操作
Spark Streaming允许DStream的数据被输出到外部系统,如数据库或文件系统。由于输出操作实际上使transformation操作后的数据可以通过外部系统被使用,同时输出操作触发所有DStream的transformation操作的实际执行(类似于RDD操作)。以下表列出了目前主要的输出操作:
| 转换 | 描述 |
|---|---|
| print() | 在Driver中打印出DStream中数据的前10个元素。 |
| saveAsTextFiles(prefix, [suffix]) | 将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| saveAsObjectFiles(prefix, [suffix]) | 将DStream中的内容按对象序列化并且以SequenceFile的格式保存。其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| saveAsHadoopFiles(prefix, [suffix]) | 将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| foreachRDD(func) | 最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或者网络数据库等。需要注意的是func函数是在运行该streaming应用的Driver进程里执行的。 |
SparkStreaming程序
SparkStreaming基础
socket 创建DStream
需要 使用nc 命令来启动Socket,作为server端;而sparkStreaming程序作为 client 端。
- 安装nc:yum -y install nc
- 执行命令启动Socket服务端: nc -l -k -p 6666
- 其中:-l:listen 代表启动监听模式,也就是作为socket服务端; -p:post 监听的端口; -k:keep 多次监听
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TestStreaming {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestStreaming")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
val ds = ssc.socketTextStream("nn1", 6666)
ds.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
ssc.start()
ssc.awaitTermination()
}
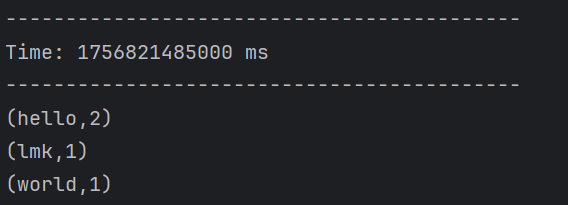
}输入内容:

返回结果:
打开WEB UI localhost:4040查看
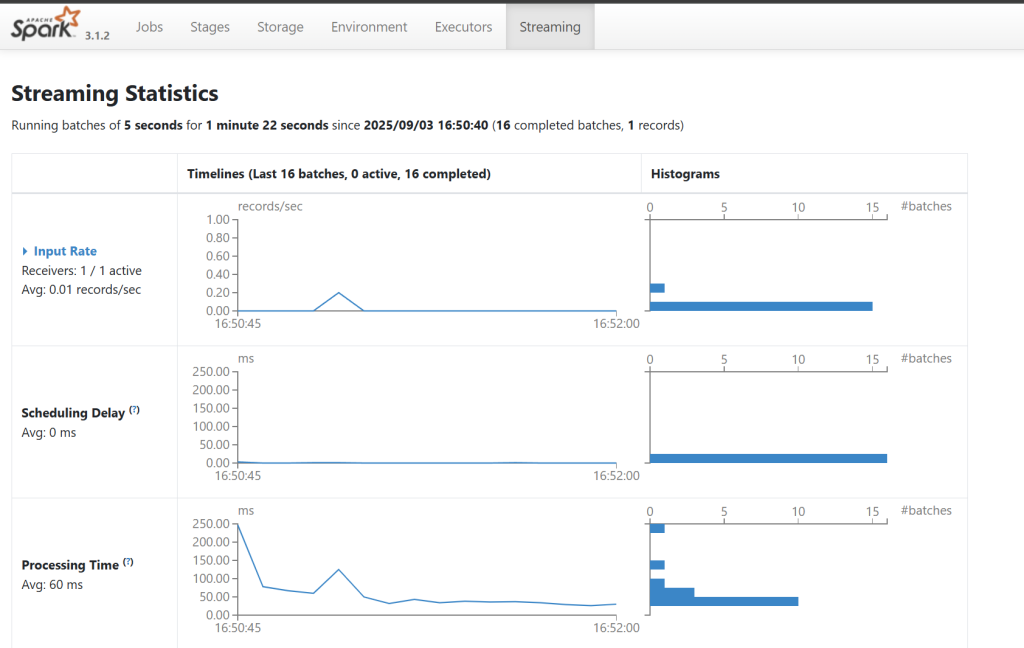

如果运行的整体的时长大于调度时间那么就会出现反压,sparkStreaming中反压的原理就是接受的效率会自动下调。
使用foreachRDD 改写
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TestStreamingWithForeachRDD {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestStreaming")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
val ds = ssc.socketTextStream("nn1", 6666)
ds.foreachRDD((rdd, time) => {
println("runtime: " + time)
rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).foreach(println)
})
//ds.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
ssc.start()
ssc.awaitTermination()
}
}用 transform 改写
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TestStreamingWithForeachRDD {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestStreaming")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
val ds = ssc.socketTextStream("nn1", 6666)
// 将流中的rdd数据一次性处理,无后续
// ds.foreachRDD((rdd, time) => {
// println("runtime: " + time)
// rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).foreach(println)
// })
//ds.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
// 将流中的rdd数据处理后放回rdd,有后续。一般不用
ds.transform((rdd, time) => {
rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
}).print()
ssc.start()
ssc.awaitTermination()
}
}DStream 的 transform 和 foreachRDD 的异同点
相同点
- 都可以进行RDD转换,可让写spark-streaming程序像写spark-core一样。比如RDD转成DataSet或DatFrame进行spark-sql的操作,操作方便。
- 只有 transform和foreachRDD 算子里的函数执行分driver端运行和executor端运行;DStream 的其他算子的函数都是在executor端运行。
区别:
- transform 是转换算子,foreachRDD是输出算子。
- transform 可以将旧RDD转成新RDD,然后返回DStream,执行DStream的行动操作。而 foreachRDD 本身是DStream的行动操作,它需要将所有的DStream 操作的代码转成RDD操作,直到最后。
updateStateByKey
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*
计算带有状态
保留所有的结果数据
*/
object TestUpdateStateByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("TestUpdateStateByKey")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("file:///D:\\ProgramFile\\spark\\data\\ckpt")
ssc.socketTextStream("nn1", 6666)
.flatMap(_.split(" "))
.map((_, 1))
//.reduceByKey(_ + _).print()
.updateStateByKey((curr:Seq[Int], last:Option[Int]) => {
Option(curr.sum + last.getOrElse(0))
})
.print()
ssc.start()
ssc.awaitTermination()
}
}第一次执行代码停掉后,第二次执行代码后,发现上次的数据并没有加载进来,说明只接收了socket流,并没有加载checkpoint的数据。
streaming用checkpoint恢复历史数据
通过StreamingContext.getOrCreate()。该方法优先使用checkpoint 检查点的数据创建StreamingContext;如果checkpoint没有数据,则将通过调用提供的“ creatingFunc”来创建StreamingContext。
只有使用updateStateByKey的时候才需要使用,因为其他的任务不需要全局数据累计结果值,就不需要读取之前的内容。
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*
计算带有状态
保留所有的结果数据
*/
object TestUpdateStateByKeyWithRecovery {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("TestUpdateStateByKey")
val ssc = StreamingContext.getOrCreate("file:///D:\\ProgramFile\\spark\\data\\ckpt", () => {
// 如果文件夹中有数据,就直接获取,没有就创建
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("file:///D:\\ProgramFile\\spark\\data\\ckpt")
ssc.socketTextStream("nn1", 6666)
.flatMap(_.split(" "))
.map((_, 1))
//.reduceByKey(_ + _).print()
.updateStateByKey((curr:Seq[Int], last:Option[Int]) => {
Option(curr.sum + last.getOrElse(0))
})
.print()
ssc
})
ssc.start()
ssc.awaitTermination()
}
}updateStateByKey只使用最近更新的值
用 updateStateByKey,会保留之前批次的数据,更新时,如果每次都要把所有数据做更新,效率太低。
判断每一步的值在输入的基础上是否有变化,没有变化就不更新,只更新变化的数据就可以了。
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*
计算带有状态
保留所有的结果数据
*/
object TestUpdateStateByKeyWithRecoveryAndCheck {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("TestUpdateStateByKey")
val ssc = StreamingContext.getOrCreate("file:///D:\\ProgramFile\\spark\\data\\ckpt", () => {
// 如果文件夹中有数据,就直接获取,没有就创建
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("file:///D:\\ProgramFile\\spark\\data\\ckpt")
ssc.socketTextStream("nn1", 6666)
.flatMap(_.split(" "))
.map((_, IsUpdateVo(1, false)))
//.reduceByKey(_ + _).print()
.updateStateByKey((curr:Seq[IsUpdateVo], last:Option[IsUpdateVo]) => {
// 增加判断,如果curr中有数据,存在更新,只输出更新的数据
val currnumber = curr.map(_.number).sum
val lastnumber = if(last.isDefined) last.get.number else 0
val result = if(currnumber > 0) IsUpdateVo(currnumber + lastnumber, true) else IsUpdateVo(currnumber + lastnumber, false)
Option(result)
})
.print()
ssc
})
ssc.start()
ssc.awaitTermination()
}
}
case class IsUpdateVo(var number:Int, var update:Boolean)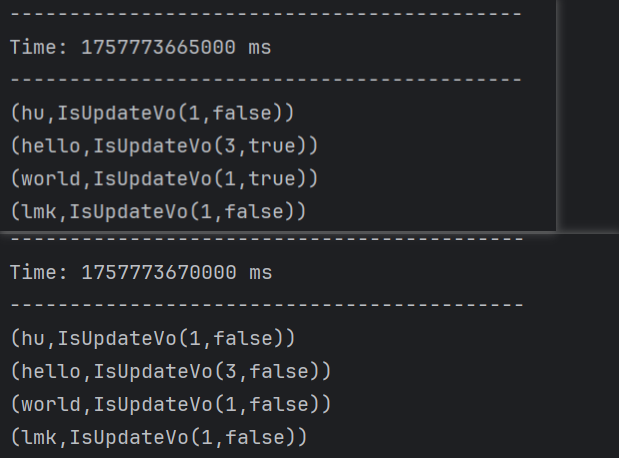
这里需要注意,ckpt文件夹如果存在之前执行过,因为有checkpoint,还是继续执行之前的任务,不会允许当前修改的,要先删除。
IsUpdateVo类输出可以根据布尔类型判断是否需要更新。
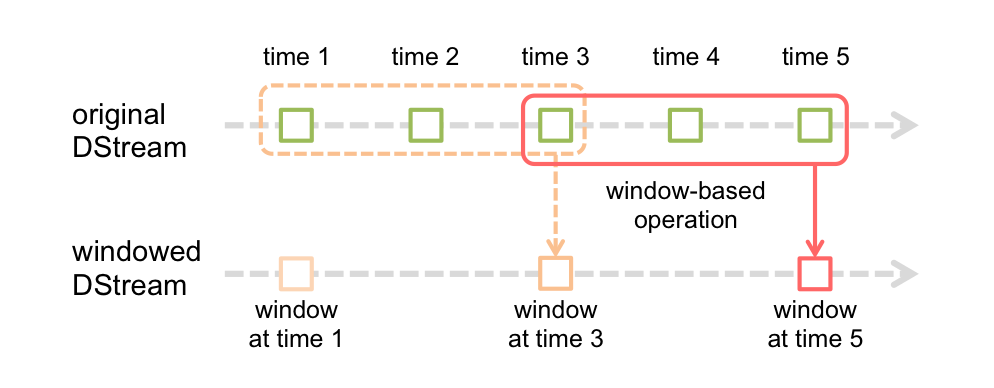
window 操作
sparkStreaming 支持 window 操作,当你需要跨批次去处理时就可以用,比如:统计过去10分钟的数据做均值、top(热词、热搜等)。
我们想要统计过去十分钟的数据,但是计算的频率不想缩短,这时候就使用window操作。
| 转换 | 描述 |
|---|---|
window(windowLength, slideInterval) | 返回一个基于源DStream的窗口批次计算后得到新的DStream。 |
countByWindow(windowLength,slideInterval) | 返回基于滑动窗口的DStream中的元素的数量。 |
reduceByWindow(func, windowLength,slideInterval) | 基于滑动窗口对源DStream中的元素进行聚合操作,得到一个新的DStream。 |
reduceByKeyAndWindow(func,windowLength,slideInterval, [numTasks]) | 基于滑动窗口对(K,V)键值对类型的DStream中的值按K使用聚合函数func进行聚合操作,得到一个新的DStream。可以进行repartition操作。 |
reduceByKeyAndWindow(func,invFunc,windowLength, slideInterval, [numTasks]) | 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作(func),并对离开窗口的老数据进行“逆向reduce” 操作(invFunc)。但是,只能用于“可逆的reduce函数”必须启用“检查点”才能使用此操作 |
countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 基于滑动窗口计算源DStream中每个RDD内每个元素出现的频次并返回DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素频次。与countByValue一样,reduce任务的数量可以通过一个可选参数进行配置。 |
window函数的使用
它是将多个批次的数据结果进行封装,变成一个整体进行执行,其实就是扩大了计算范围。
window中的参数,如果设定了窗口大小,默认窗口滑动大小就是批次大小
window(窗口大小,滑动大小)
window函数中可以设置窗口大小和滑动大小,但是窗口的大小或者是滑动大小必须是批次间隔的整数倍。
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Durations.seconds
import org.apache.spark.streaming.StreamingContext
object TestWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestWindow")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf, seconds(5))
ssc.socketTextStream("nn1", 6666)
// 如果不设定计算周期,那么就是默认上面配置的5秒
.window(seconds(15),seconds(10))
.flatMap(_.split(" "))
.map((_, 1))
//window先后的顺序都一样,不过就是前面的先执行后累加
//.window(seconds(15),seconds(10))
.reduceByKey(_ + _)
.print()
ssc.start()
ssc.awaitTermination()
}
}reduceByKeyAndWindow函数的使用
window函数就是将数据进行累加,然后计算其中的结果数据。
window进行累加+ reduceByKey进行聚合
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Durations.seconds
import org.apache.spark.streaming.StreamingContext
object TestWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestWindow")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf, seconds(5))
ssc.checkpoint("file:///D:\\ProgramFile\\spark\\data\\windowckpt")
ssc.socketTextStream("nn1", 6666)
// 如果不设定计算周期,那么就是默认上面配置的5秒
// .window(seconds(15),seconds(10))
.flatMap(_.split(" "))
.map((_, 1))
// 上面两个可以简写,使用之前的_+_会报错,缺失参数的类型
// .reduceByKeyAndWindow((x:Int, y:Int) => x + y, seconds(15), seconds(10))
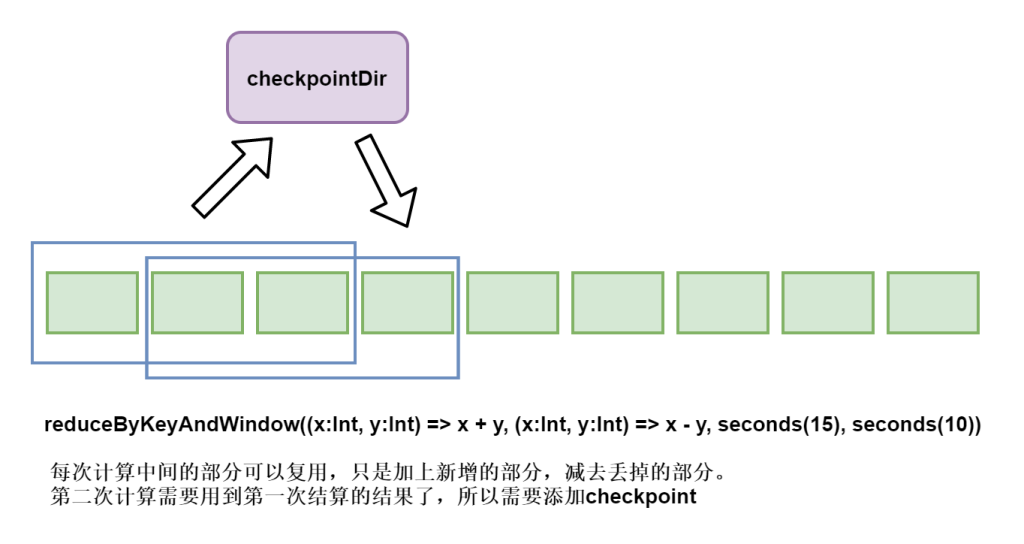
// 这样写效率更高,每次计算中间的部分可以复用,只是加上新加的部分,减掉丢掉的部分。第二次计算需要用到第一次结算的结果了,所以需要添加checkpoint
.reduceByKeyAndWindow((x:Int, y:Int) => x + y, (x:Int, y:Int) => x - y, seconds(15), seconds(10))
//.reduceByKey(_ + _)
.print()
ssc.start()
ssc.awaitTermination()
}
}
结果如下
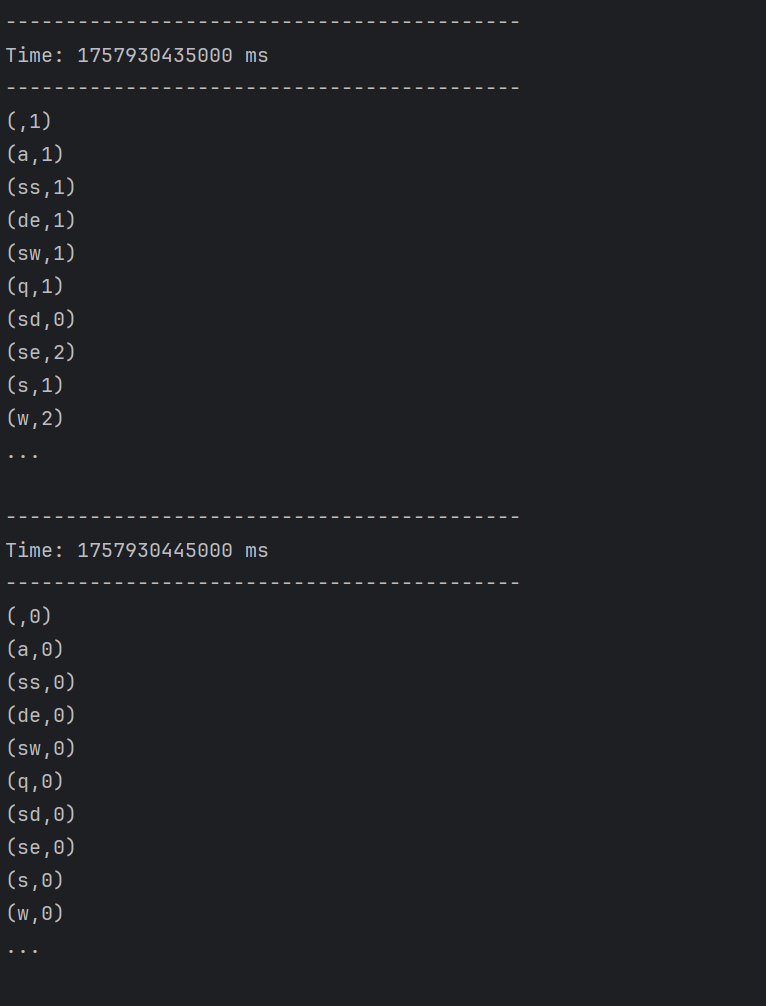
与之前不同的是,写了ckpt后就算是0,每次执行都会有结果输出。
在调试的过程中发现写了window算子后,还可以在后面加,但是需要注意,后面的执行间隔,只能是上一次执行间隔的倍数了。
其他的window算子
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Durations.seconds
import org.apache.spark.streaming.StreamingContext
object TestWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestWindow")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf, seconds(5))
ssc.checkpoint("file:///D:\\ProgramFile\\spark\\data\\windowckpt")
val ds = ssc.socketTextStream("nn1", 6666)
.flatMap(_.split(" "))
//ds.window(seconds(10)).count()
// 必须写后面的滑动大小
ds.countByWindow(seconds(10),seconds(5)).print()
//ds.window(seconds(10)).countByValue()
ds.countByValueAndWindow(seconds(10),seconds(5)).print()
//ds.window(seconds(10)).reduce((x, y)=> x + "-" + y)
ds.reduceByWindow((x, y)=> x + "-" + y,seconds(10),seconds(5)).print()
ssc.start()
ssc.awaitTermination()
}
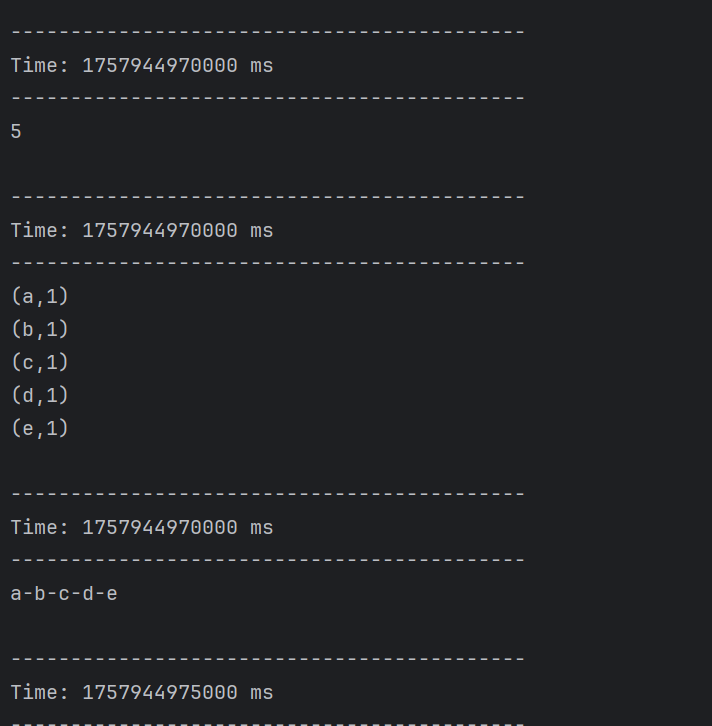
}结果如下:
SparkStreaming 何时使用缓存,何时开启检查点?
sparkStreaming 什么时候使用缓存
- DStream 和 RDD相似,如果DStream中的数据将被多次计算(例如,对同一数据进行多次操作),这将很有用。可以调用 cache()或 persist() 方法缓存。
- 对于基于窗口的操作reduceByWindow和 reduceByKeyAndWindow和基于状态的操作updateStateByKey,由于窗口的操作生成的DStream会自动保存在内存中,而无需开发人员调用persist()。
sparkStreaming 什么时候开启检查点checkpoint?
- 有状态转换的用法 -如果在应用程序中使用updateStateByKey或reduceByKeyAndWindow(带有反函数,优化操作),则必须提供checkpoint目录以允许定期进行RDD的checkpoint。
- 从运行应用程序的驱动程序故障中恢复,checkpoint用于恢复进度信息。
多receiver源union的方式
当数据源多时,有多个数据源就有多个DStream,每个DStream生成自己的任务,为了提高运行效率,可以将多个数据源的流数据union在一起,进而达到减少task的目的。
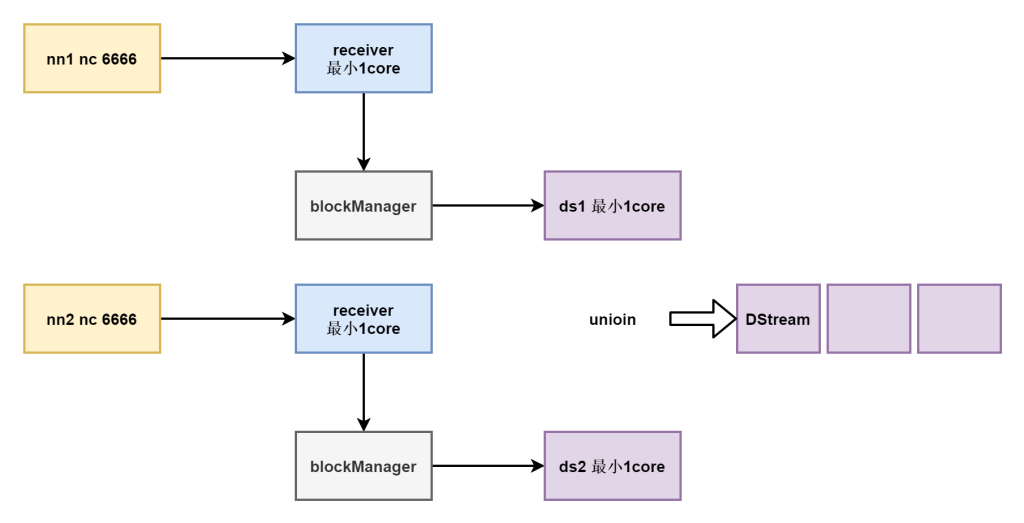
先union后处理
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Durations.seconds
import org.apache.spark.streaming.StreamingContext
object TestReceiverUnion {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestReceiverUnion")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,seconds(5))
val ds1 = ssc.socketTextStream("nn1", 6666)
val ds2 = ssc.socketTextStream("nn2", 6666)
val ds3 = ds1.union(ds2)
ds3.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
ssc.start()
ssc.awaitTermination()
}
}结果如下
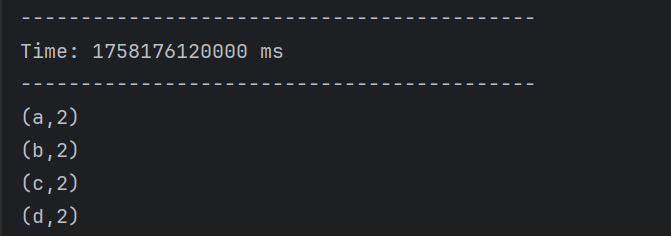
先处理后union
package com.lmk.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Durations.seconds
import org.apache.spark.streaming.StreamingContext
object TestReceiverUnion {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestReceiverUnion")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,seconds(5))
val ds1 = ssc.socketTextStream("nn1", 6666)
val ds2 = ssc.socketTextStream("nn2", 6666)
val ds3 = ds1.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
val ds4 = ds2.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
ds3.union(ds4).print()
ssc.start()
ssc.awaitTermination()
}
}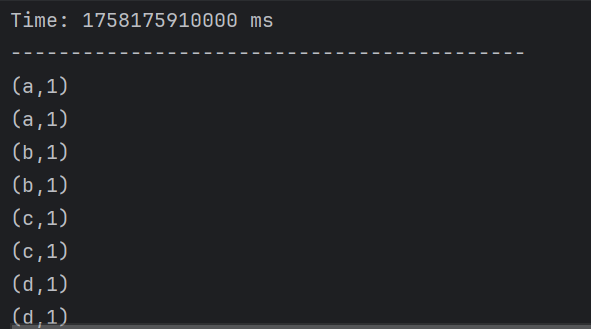
先处理后union就是将计算后的结果合并了,并不会将结果再合并计算,所以与先union是不同的。
SparkStreaming输出到HDFS
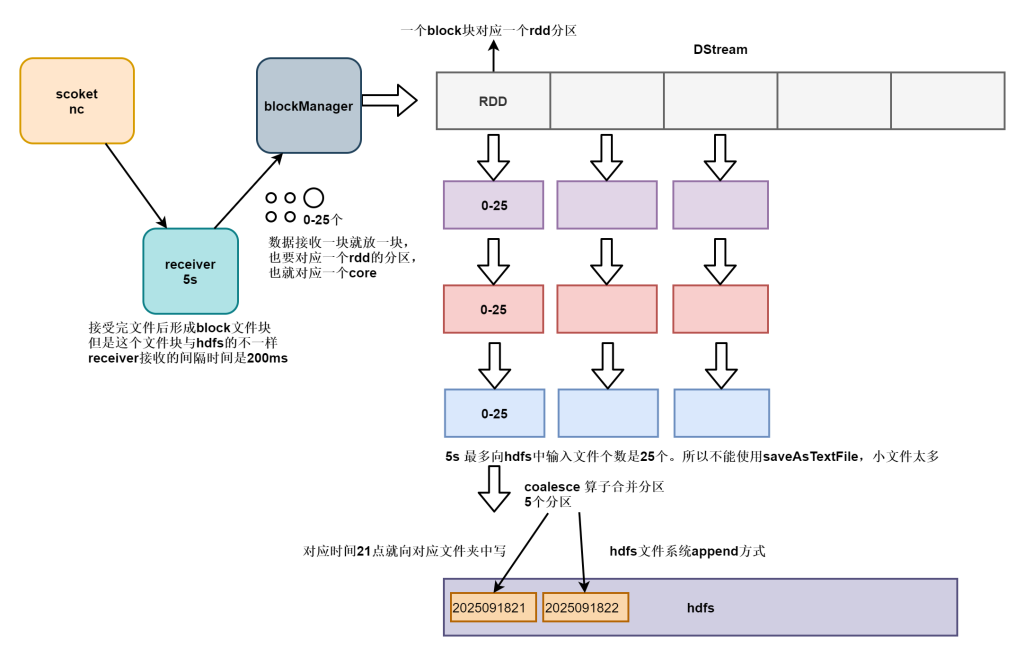
socket 源如何分区?
当从socket 源接收数据时,receiver 会创建数据块。每blockInterval毫秒生成一个新的数据块。在batchInterval期间创建了N个数据块,其中N = batchInterval / blockInterval。
blockInterval 默认是200ms,如果 batchInterval 设置为 2s,理论这个批次会产生 2000/200 =10个分区。如果某个blockInterval 时间内没有数据,则这个blockInterval 时间 就没有产生数据块。也就是说,开启socket源的sparkStreaming程序,如果socket端不喂数据,那这个批次就不会产生数据块,进而分区数是0。
小文件就会带来一系列的问题,小文件多会占用很大的namenode的元数据空间,下游使用小文件的JOB会产生很多个partition,如果是mr任务就会有很多个map,如果是spark任务就会有很多个task。
解决方式:
- 增加批次间隔的大小。(不建议使用)失去了流式计算的意义。
- 使用批处理任务进行小文件的合并。(不建议使用)需要新开个任务将多个小文件合并成大文件。
- 使用coalesce 减少分区数,进而减少输出小文件的个数。
- 使用HDFS的append方式,追加写入文件中。
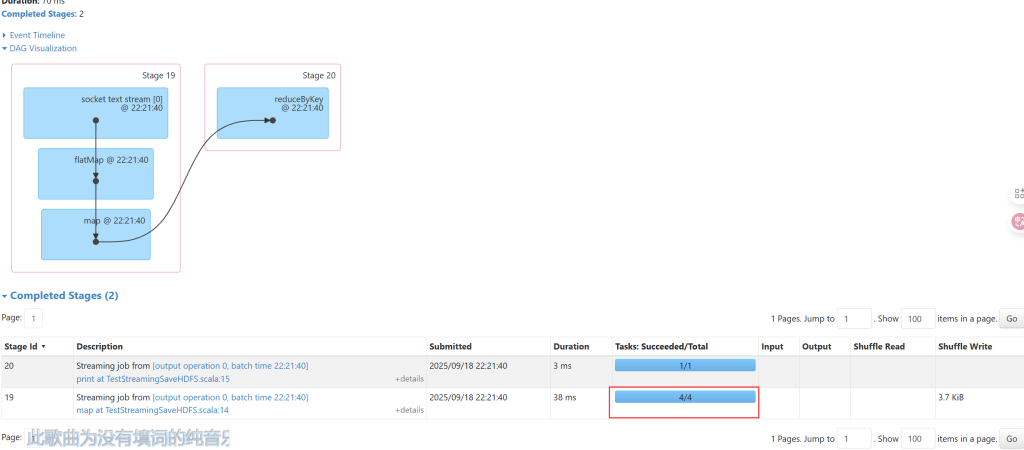
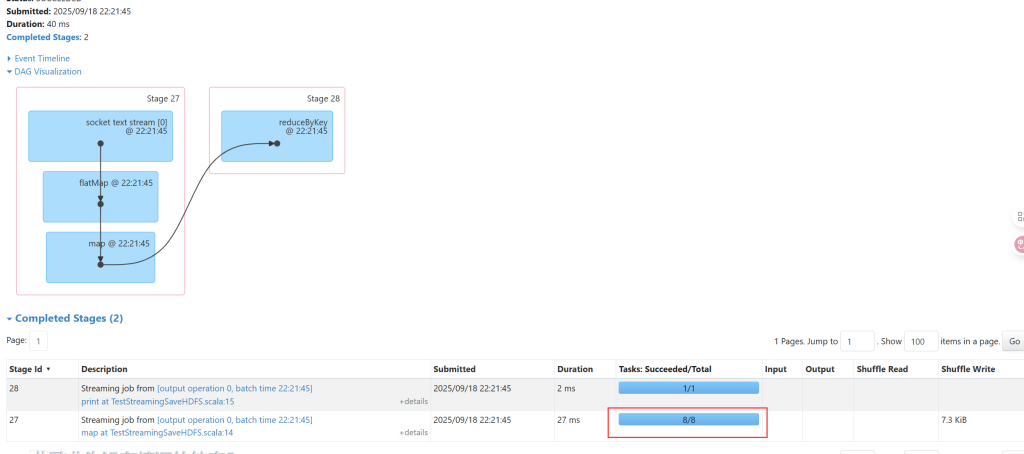
输入数据的时候,随着输入效率的提高,分区个数也会变多,最多一般在25个左右。
package com.lmk.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FSDataOutputStream, FileSystem, Path}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import java.io.PrintWriter
import java.text.SimpleDateFormat
import java.util.Date
object TestStreamingSaveHDFS {
def main(args: Array[String]): Unit = {
val parent_path = "/spark_sink/"
val file_name = "t.txt"
val conf = new SparkConf()
conf.setAppName("TestStreamingSaveHDFS")
conf.setMaster("local[*]")
// 出现反压,所以调长每个批次的时间
val ssc = new StreamingContext(conf,Seconds(20))
val ds1 = ssc.socketTextStream("nn1", 6666)
ds1.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.foreachRDD(rdd => {
// 一个分区创建一个连接,避免多次创建,也可以选择foreachPartitions
// 出现反压情况,连接过慢,减少分区个数,从而减少连接创建
rdd.coalesce(2).mapPartitionsWithIndex((index, it) => {
// 每个分区创建一个连接对象
val fs = FileSystem.get(new Configuration())
// 直接创建文件,如果存在就写,没有就创建。现在是按照小时创建
val df = new SimpleDateFormat("yyyy/MM/dd/HH")
val date_str = df.format(new Date())
val all_path = parent_path + date_str + '/' + index + '_' + file_name
var stream: FSDataOutputStream = null
// 判断如果文件存在就是追加流,不存在就是创建流
if(fs.exists(new Path(all_path)))
stream = fs.append(new Path(all_path))
else {
stream = fs.create(new Path(all_path))
}
// 追加写入字符流,自动刷新
val pw = new PrintWriter(stream,true)
it.foreach(t=>{
val line = t._1+"->"+t._2
pw.println(line)
})
pw.close()
fs.close()
// mapPartitionsWithIndex 是转换类算子,所以需要返回一个rdd
Iterator.empty
// 触发运算
}).foreach((t:String)=>{})
})
ssc.start()
ssc.awaitTermination()
}
}注意:执行可能存在因为连接数量过大的反压情况,spark的自动反压解决不了,需要调整分区个数,增加批次间隔时间
代码注意点:
- mapParittionsWithIndex算子实现分区创建链接并且获取分区下标作为文件名
- 使用日期进行格式化替代路径一个小时写入一个文件夹中
- 如果存在就追加不存在就创建
- 使用转换类算子需要返回数据
- 转换类算子需要触发运算执行
最根本的思想就是取出DStream中的RDD然后使用最原始的方式存储数据到外部。
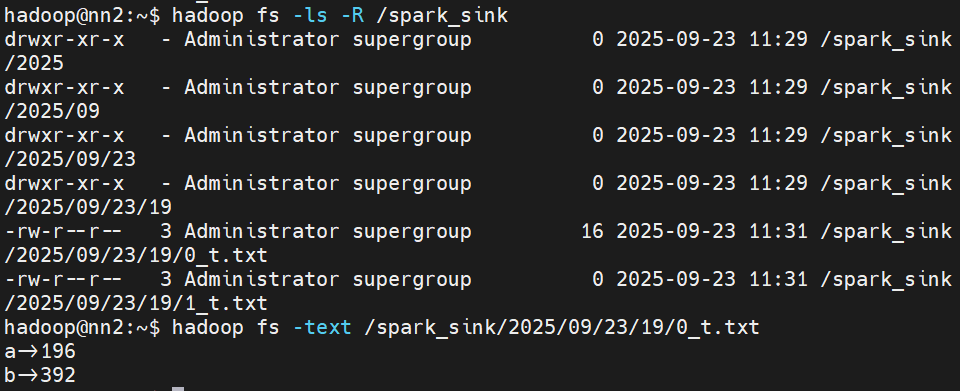
输出结果如下:
sparkStreaming接入kafka
spark-streaming-kafka
kafka读取数据的配置

sparkStreaming 读kafka,有两种方式,一种读zookeeper(现有版本已抛弃),一种读broker,也就是kafka直连流方式。
位置策略
park Streaming 中提供了如下三种位置策略,用于指定 Kafka 主题分区与 Spark 执行程序 Executors 之间的分配关系:
- PreferConsistent : 优先实例(spark推荐),它将在所有的 Executors 上均匀分配分区;
- PreferBrokers : 当 Spark 的 Executor 与 Kafka Broker 在同一机器上时可以选择该选项,它优先将该 Broker 上的首领分区分配给该机器上的 Executor;
- PreferFixed : 可以指定主题分区与特定主机的映射关系,显示地将分区分配到特定的主机,其构造器如下:
@Experimental
def PreferFixed(hostMap: collection.Map[TopicPartition, String]): LocationStrategy =
new PreferFixed(new ju.HashMap[TopicPartition, String](hostMap.asJava))
@Experimental
def PreferFixed(hostMap: ju.Map[TopicPartition, String]): LocationStrategy =
new PreferFixed(hostMap)消费策略
订阅和分配。
- 订阅:可订阅一个主题所有分区或多个主题所有分区。
- 分配:可消费指定主题分区数据。
Spark Streaming 提供了两种主题订阅方式,分别为 Subscribe 和 SubscribePattern。后者可以使用正则匹配订阅主题的名称。其构造器分别如下:
/**
\* @param topics 需要订阅的主题的集合
\* @param Kafka 消费者参数
\* @param offsets(可选): 在初始启动时开始的偏移量。如果没有,则将使用保存的偏移量或 auto.offset.reset 属性的值
*/
def Subscribe[K, V](
topics: ju.Collection[jl.String],
kafkaParams: ju.Map[String, Object],
offsets: ju.Map[TopicPartition, jl.Long]): ConsumerStrategy[K, V] = { ... }
/**
\* @param pattern需要订阅的正则
\* @param Kafka 消费者参数
\* @param offsets(可选): 在初始启动时开始的偏移量。如果没有,则将使用保存的偏移量或 auto.offset.reset 属性的值
*/
def SubscribePattern[K, V](
pattern: ju.regex.Pattern,
kafkaParams: collection.Map[String, Object],
offsets: collection.Map[TopicPartition, Long]): ConsumerStrategy[K, V] = { ... }简单案例代码
package com.lmk.spark
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 1. kafka的params参数
* 2. 设定topic
* 3. subscribe订阅
* 4. calculate进行计算
*/
object TestKafka {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestKafka")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(3))
val kafkaParams = Map(
"bootstrap.servers" -> "nn1:9092,nn2:9092,nn3:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "sparkStreaming",
//earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
//latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
//none topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topic_lmk")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
// stream 中有key和value
stream.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
}测试输入数据
kafka-console-producer.sh --bootstrap-server nn1:9092 --topic topic_lmkSparkStreaming动态更新广播变量
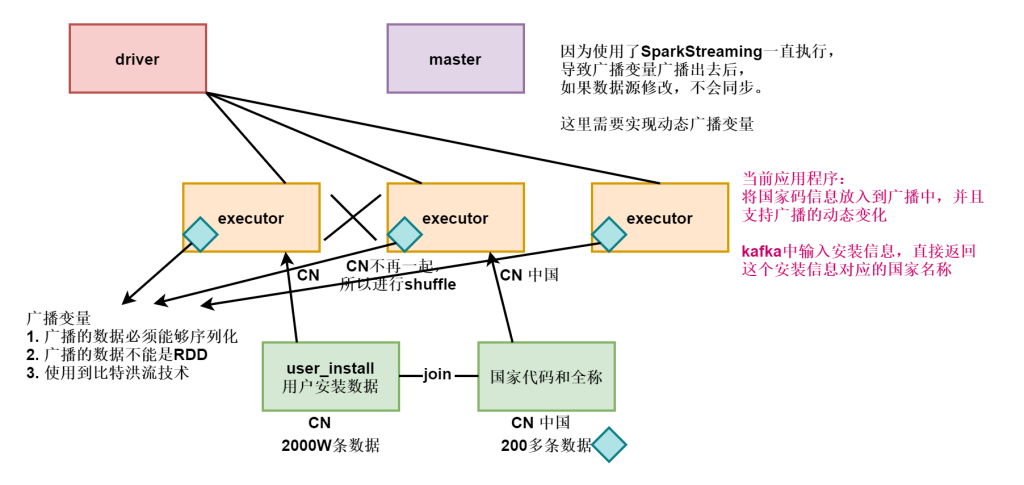
所以我们需要实现动态广播技术
准备数据country.txt到idea中,并且拆分一个国家信息文件为两个,将这个文件夹中的数据作为广播。
无动态广播案例代码
package com.lmk.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
import java.util.Scanner
import scala.collection.mutable
/**
* 1. kafka的params参数
* 2. 设定topic
* 3. subscribe订阅
* 4. calculate进行计算
*/
object TestkafkaWithDynamicBroadcast {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestKafka")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(3))
val kafkaParams = Map(
"bootstrap.servers" -> "nn1:9092,nn2:9092,nn3:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "sparkStreaming",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topic_lmk")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
// stream 中有key和value
// 这里如果这样写就是读取配置文件中的hdfs文件
//val fs = FileSystem.get(new Configuration())
val fs = FileSystem.getLocal(new Configuration())
// listStatus 列出文件夹下的文件
val statuses = fs.listStatus(new Path("data/country"))
val map = mutable.Map[String, String]()
// 遍历
for(status <- statuses) {
val path = status.getPath
val in = fs.open(path)
val scan = new Scanner(in)
// 当scan有值的时候
while (scan.hasNext) {
val line = scan.nextLine()
val strs = line.split("\t")
map.put(strs(0), strs(1))
}
in.close()
}
val bs = ssc.sparkContext.broadcast(map)
stream.map(_.value())
.foreachRDD(rdd => {
// driver 端代码,2秒执行一次
val countryMap = bs.value
rdd.map(code=>{
countryMap.getOrElse(code, "unknow")
}).foreach(println)
})
ssc.start()
ssc.awaitTermination()
}
}动态广播案例代码
package com.lmk.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
import java.util.Scanner
import scala.collection.mutable
/**
* 1. kafka的params参数
* 2. 设定topic
* 3. subscribe订阅
* 4. calculate进行计算
*/
object TestkafkaWithDynamicBroadcast {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestKafka")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(3))
val kafkaParams = Map(
"bootstrap.servers" -> "nn1:9092,nn2:9092,nn3:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "sparkStreaming",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topic_lmk")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
// stream 中有key和value
// 这里如果这样写就是读取配置文件中的hdfs文件
//val fs = FileSystem.get(new Configuration())
val fs = FileSystem.getLocal(new Configuration())
val map = mutable.Map[String, String]()
var bs = ssc.sparkContext.broadcast(map)
val interval = 10000
var lastUpdateTime = 0L
stream.map(_.value())
.foreachRDD(rdd => {
// driver 端代码,2秒执行一次
if(bs.value.isEmpty || System.currentTimeMillis() - lastUpdateTime > interval) {
val statuses = fs.listStatus(new Path("data/country"))
statuses.foreach(x => {
val in = fs.open(x.getPath)
val scan = new Scanner(in)
while (scan.hasNext) {
val line = scan.nextLine()
val strs = line.split("\t")
map.put(strs(0), strs(1))
}
in.close()
})
// 去除旧的广播变量
bs.unpersist()
// 重新广播
bs = ssc.sparkContext.broadcast(map)
lastUpdateTime = System.currentTimeMillis()
}
rdd.map(code => {
bs.value.getOrElse(code, "unknow")
}).foreach(println)
})
ssc.start()
ssc.awaitTermination()
}
}sparkStreaming-kafka的offset管理
receiver方式 vs 直连方式
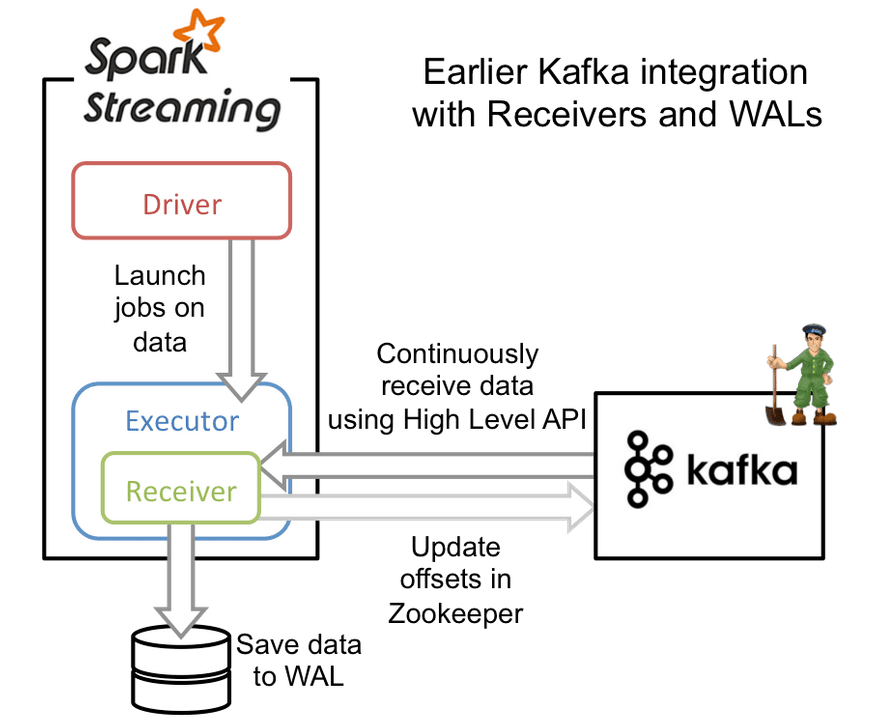
sparkStreaming-kafka 的 receiver 方式
spark2.x前期版本
当前版本问题:
- 效率不对等,容易出现反压
- 容易出现数据丢失,为保证稳定,需要单独存储数据到hdfs中,效率底
- 出现并行度不一致问题
优点:帮助存储偏移量信息,存到了zookeeper中
sparkStreaming-kafka 的 Direct 方式
spark3.x已经不支持接收器版本
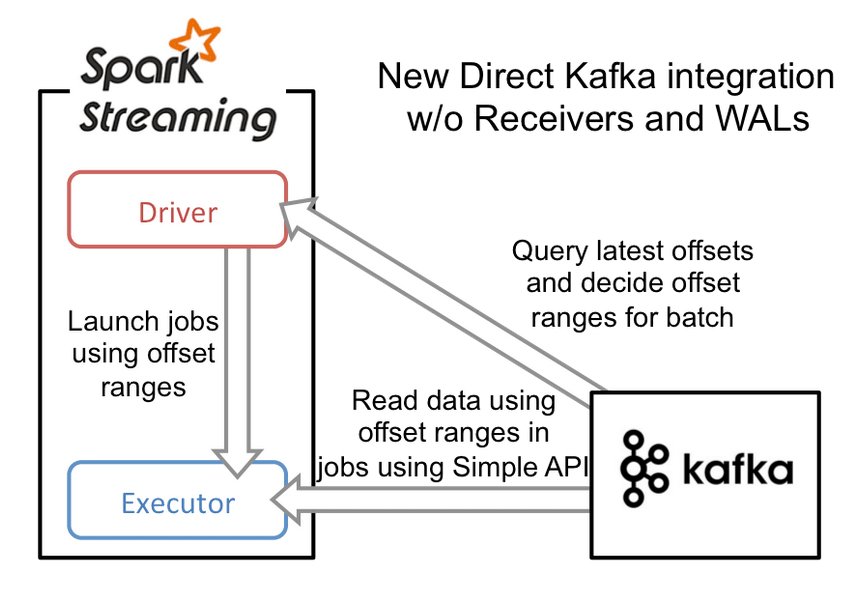
kafka直连,需要多少就拉取多少,好处如下:
- 效率对等
- 稳定性高
- 分区映射
缺点:没办法自动管理偏移量
receiver 和 direct 方式区别:
receiver 方式:
receiver把固定间隔的数据放在内存中,使用kafka高级的API,自动维护偏移量,达到固定的时间一起处理每个批次的offset数据,效率低且容易丢数据,因为数据在内存中,为了容错,还得加入预写日志。
Direct 直连方式:
会周期性地查询Kafka,获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
此种方式相当于直接连接到kafka的分区上(无需receiver,也不需要预写日志),一个RDD的分区对应一个Kafka的分区,使用Kafka底层的API去读取数据,效率高。
流式计算有三种容错语义,分别是:
- at-most-once(最多一次):每条记录将被处理一次或根本不处理。不管理偏移量,如果停掉,上次计算到哪了,不知道。
- at-least-once(至少一次):每条记录将被处理一次或多次。这比最多一次强,因为它确保不会丢失任何数据。但可能有重复。管理-自动管理,当程序挂掉,重新开始,中断的计算又重新计算。
- Exactly once(只处理一次):每条记录只会被处理一次 – 不会丢失任何数据,也不会多次处理数据。这显然是三者中最强的保证。管理-手动管理。
SparkStreaming直连kafka可以保证时效最强语义,但需要我们自己去维护偏移量(现在比较流行的方式是手动把offset维护到第三方存储,比如zookeeper、MySQL等。)。
如果想实现最强语义,需要做到以下几点:
- kafka源支持重复读取。
- SparkStreaming的输出要支持幂等性或事务。
- 幂等性:输出多次的操作内容是一样的。
- 事务:将输出和维护offset放在一个事务中,要么都成功,要么都失败。
- 需要我们自己手动去维护消费的offset。
直连kafka,kafka的offset 由 开发者自己维护,获取要消费的offset,进行消费处理,处理完成后,自行维护offset,输出要支持幂等性或事务。
整体代码如下:
receiver方式管理offset
目前被直连方式替代
direct方式管理offset
手动提交offset到kafka
package com.lmk.spark
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges, KafkaUtils}
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 1. kafka的params参数
* 2. 设定topic
* 3. subscribe订阅
* 4. calculate进行计算
*/
object TestKafka {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestKafka")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(3))
val kafkaParams = Map(
"bootstrap.servers" -> "nn1:9092,nn2:9092,nn3:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "sparkStreaming2",
"auto.offset.reset" -> "earliest", //如果没有偏移量,从最早的开始
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topic_lmk")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
// stream 中有key和value
//stream.map(_.value()).print()
stream.foreachRDD({rdd=>
// 获取偏移量
val ranges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreach(println)
// 提交, 代码放在前面,如果代码执行失败了,那么也不会提交,成功才会提交
stream.asInstanceOf[CanCommitOffsets].commitAsync(ranges)
})
ssc.start()
ssc.awaitTermination()
}
}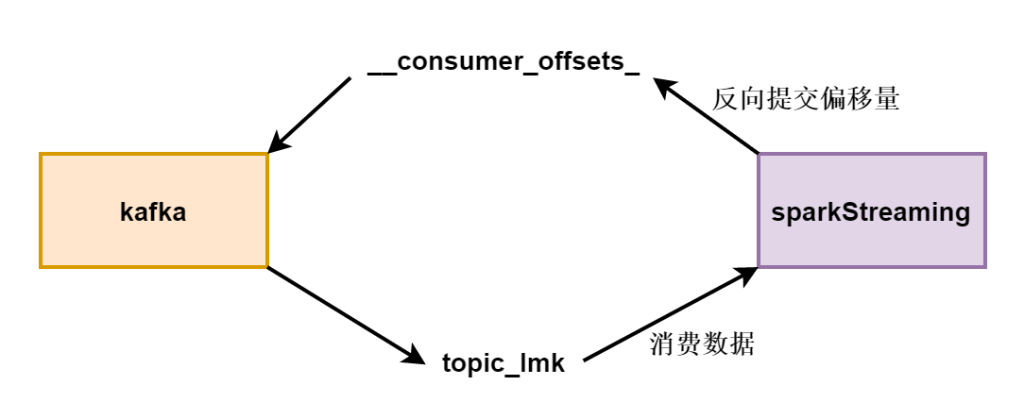
_consumer_offsets是topic,topic里的数据只能看不能改,这个甚至无法看。所以可以存储到外部存储系统。
手动提交offset到zookeeper
package com.hainiu.spark.offset
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Durations, StreamingContext}
import scala.collection.mutable.HashMap
/**
* 偏移量保存到zk中
* 不使用DStream的transform等其它算子
* 将DStream数据处理方式转成纯正的spark-core的数据处理方式
*/
object SparkStreamingKafkaOffsetZKForeachRDD {
def main(args: Array[String]): Unit = {
//指定组名
val group = "groupxxx"
//创建SparkConf
val conf = new SparkConf().setAppName("SparkStreamingKafkaOffsetZK").setMaster("local[*]")
//创建SparkStreaming,设置间隔时间
val ssc = new StreamingContext(conf, Durations.seconds(5))
//指定 topic 名字
val topic = "topic_41"
//指定kafka的broker地址,SparkStream的Task直连到kafka的分区上,用底层的API消费,效率更高
// val brokerList = "s1.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092"
val brokerList = "s1.hadoop:9092"
//指定zk的地址,更新消费的偏移量时使用,当然也可以使用Redis和MySQL来记录偏移量
val zkQuorum = "nn1.hadoop:2181"
//SparkStreaming时使用的topic集合,可同时消费多个topic
val topics: Set[String] = Set(topic)
//topic在zk里的数据路径,用于保存偏移量
val topicDirs = new ZKGroupTopicDirs(group, topic)
//得到zk中的数据路径 例如:"/consumers/${group}/offsets/${topic}"
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
//kafka参数
val kafkaParams = Map(
"bootstrap.servers" -> brokerList,
"group.id" -> group,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"enable.auto.commit" -> (false: java.lang.Boolean),
//earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
//latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
//none topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
"auto.offset.reset" -> "latest"
)
//定义一个空的kafkaStream,之后根据是否有历史的偏移量进行选择
var kafkaStream: InputDStream[ConsumerRecord[String, String]] = null
//如果存在历史的偏移量,那使用fromOffsets来存放存储在zk中的每个TopicPartition对应的offset
var fromOffsets = new HashMap[TopicPartition, Long]
//创建zk客户端,可以从zk中读取偏移量数据,并更新偏移量
val zkClient = new ZkClient(zkQuorum)
//从zk中查询该数据路径下是否有每个partition的offset,这个offset是我们自己根据每个topic的不同partition生成的
//数据路径例子:/consumers/${group}/offsets/${topic}/${partitionId}/${offset}"
//zkTopicPath = /consumers/group1311/offsets/hainiu_test/
// /consumers/groupid/offsets/topic
//路径 /consumers/g3/topic_42/0 --> 100
//路径 /consumers/g3/topic_42/1 --> 100
//路径 /consumers/g3/topic_42/2 --> 100
val children = zkClient.countChildren(zkTopicPath)//3
//判断zk中是否保存过历史的offset
if (children > 0) {
for (i <- 0 until children) {
// /consumers/group100/offsets/hainiu_html/0
// get /consumers/lishuai38/offsets/hainiu_html/44
val partitionOffset = zkClient.readData[String](s"$zkTopicPath/${i}")
// hainiu_html/0
val tp = new TopicPartition(topic, i)
//将每个partition对应的offset保存到fromOffsets中
// hainiu_html/0 -> 888
fromOffsets += tp -> partitionOffset.toLong
}
// println(fromOffsets)
//通过KafkaUtils创建直连的DStream,并使用fromOffsets中存储的历史偏离量来继续消费数据
kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams, fromOffsets))
} else {
//如果zk中没有该topic的历史offset,那就根据kafkaParam的配置使用最新(latest)或者最旧的(earliest)的offset
kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams))
}
//通过rdd转换得到偏移量的范围
var offsetRanges = Array[OffsetRange]()
//迭代DStream中的RDD,将每一个时间间隔对应的RDD拿出来,这个方法是在driver端执行
//在foreachRDD方法中就跟开发spark-core是同样的流程了,当然也可以使用spark-sql
kafkaStream.foreachRDD((kafkaRDD, time) => {
if (!kafkaRDD.isEmpty()) {
//得到该RDD对应kafka消息的offset,该RDD是一个KafkaRDD,所以可以获得偏移量的范围
//不使用transform可以直接在foreachRDD中得到这个RDD的偏移量,这种方法适用于DStream不经过任何的转换,
//直接进行foreachRDD,因为如果transformation了那就不是KafkaRDD了,就不能强转成HasOffsetRanges了,从而就得不到kafka的偏移量了
offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
val dataRDD: RDD[String] = kafkaRDD.map(_.value())
//执行这个rdd的aciton,这里rdd的算子是在集群上执行的
dataRDD.foreachPartition(partition =>
partition.foreach(x => {
println(x)
})
)
// 将最新的offset更新到zookeeper外部存储
for (o <- offsetRanges) {
// /consumers/group100/offsets/hainiu_html/0
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
//将该 partition 的 offset 保存到 zookeeper
// /consumers/group100/offsets/hainiu_html/12
println(s"time:${time}==>维护到zk的offset是:${zkPath}__${o.untilOffset.toString}")
ZkUtils(zkClient, false).updatePersistentPath(zkPath, o.untilOffset.toString)
}
}
})
ssc.start()
ssc.awaitTermination()
}
}修改组id ,zookeeper的地址使用的是spark的集群的zk,kafka集群的地址。执行代码输入kafka中的数据
解决数据丢失的时候,程序启动问题
Kafka的数据默认保存7天,如果zookeeper里维护的是7天前数据的消费offset,当启动程序时会报错,如何解决?
代码需要改版
- 首先读取zk中的偏移量信息
- 读取kafka中最小的偏移量信息
- zk的偏移量与kafka偏移量对比
- 取两者中大的值
package com.hainiu.spark.offset
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.kafka.clients.consumer.{ConsumerRecord, KafkaConsumer}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.kafka.common.{PartitionInfo, TopicPartition}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Durations, StreamingContext}
import java.{lang, util}
import scala.collection.mutable.{HashMap, ListBuffer}
/**
* 偏移量保存到zk中
* 不使用DStream的transform等其它算子
* 将DStream数据处理方式转成纯正的spark-core的数据处理方式
* 由于SparkStreaming程序长时间中断,再次消费时kafka中数据已过时,
* 上次记录消费的offset已丢失的问题处理
*/
object SparkStreamingKafkaOffsetZKRecovery {
def main(args: Array[String]): Unit = {
//指定组名
val group = "group40"
//创建SparkConf
val conf = new SparkConf().setAppName("SparkStreamingKafkaOffsetZKRecovery").setMaster("local[*]")
//创建SparkStreaming,设置间隔时间
val ssc = new StreamingContext(conf, Durations.seconds(5))
//指定 topic 名字
val topic = "topic_41"
//指定kafka的broker地址,SparkStream的Task直连到kafka的分区上,用底层的API消费,效率更高
// val brokerList = "s1.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092"
val brokerList = "s1.hadoop:9092"
//指定zk的地址,更新消费的偏移量时使用,当然也可以使用Redis和MySQL来记录偏移量
val zkQuorum = "nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181"
//SparkStreaming时使用的topic集合,可同时消费多个topic
val topics: Set[String] = Set(topic)
//topic在zk里的数据路径,用于保存偏移量
val topicDirs = new ZKGroupTopicDirs(group, topic)
//得到zk中的数据路径 例如:"/consumers/${group}/offsets/${topic}"
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
//kafka参数
val kafkaParams = Map(
"bootstrap.servers" -> brokerList,
"group.id" -> group,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"enable.auto.commit" -> (false: java.lang.Boolean),
//earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
//latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
//none topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
"auto.offset.reset" -> "earliest"
)
//定义一个空的kafkaStream,之后根据是否有历史的偏移量进行选择
var kafkaStream: InputDStream[ConsumerRecord[String, String]] = null
//如果存在历史的偏移量,那使用fromOffsets来存放存储在zk中的每个TopicPartition对应的offset
// 是外部存储zookeeper存的offset
val zkOffsetMap = new HashMap[TopicPartition, Long]
//创建zk客户端,可以从zk中读取偏移量数据,并更新偏移量
val zkClient = new ZkClient(zkQuorum)
//从zk中查询该数据路径下是否有每个partition的offset,这个offset是我们自己根据每个topic的不同partition生成的
//数据路径例子:/consumers/${group}/offsets/${topic}/${partitionId}/${offset}"
//zkTopicPath = /consumers/group100/offsets/hainiu_html/
val children = zkClient.countChildren(zkTopicPath)
//判断zk中是否保存过历史的offset
if (children > 0) {
for (i <- 0 until children) {
// /consumers/group100/offsets/hainiu_html/0
val partitionOffset = zkClient.readData[String](s"$zkTopicPath/${i}")
// hainiu_html/0
val tp = new TopicPartition(topic, i)
//将每个partition对应的offset保存到fromOffsets中
// hainiu_html/0 -> 888
zkOffsetMap += tp -> partitionOffset.toLong
}
println("-------consumer zookeeper offset---------------")
println(zkOffsetMap)
/*
通过kafkaConsumer对象,获取对应topic所有分区的kafka 数据最早的offset
*/
// 创建kafkaConsumer对象
import scala.collection.convert.ImplicitConversionsToJava.`map AsJavaMap`
val kafkaConsumer = new KafkaConsumer(kafkaParams)
// 获取topic的所有分区信息,主要拿到每个分区的编号
val kafkaPartitionInfoList: util.List[PartitionInfo] = kafkaConsumer.partitionsFor(topic)
import scala.collection.convert.ImplicitConversions.`collection AsScalaIterable`
val kafkaTopicPartitions = new ListBuffer[TopicPartition]
for(f <- kafkaPartitionInfoList){
val topicName: String = f.topic()
val partitionId: Int = f.partition()
kafkaTopicPartitions += new TopicPartition(topicName, partitionId)
}
// 根据每个分区编号获取每个分区中,kafka数据最早的offset
import scala.collection.convert.ImplicitConversionsToJava.`collection asJava`
val kafkaDataEarliestOffsetMap: util.Map[TopicPartition, lang.Long] = kafkaConsumer.beginningOffsets(kafkaTopicPartitions)
println("-----kafka data Earliest offset----------------")
println(kafkaDataEarliestOffsetMap)
/*
通过 zkOffset 与 kafkaDataEarliestOffset 做对比来修正 zkOffset
用于解决SparkStreaming程序长时间中断,再次消费时已记录的offset丢失导致程序启动报错问题
*/
import scala.collection.convert.ImplicitConversions.`map AsScala`
// 外循环是kafkaDataOffset,内循环是zkOffset
for((tp, value) <- kafkaDataEarliestOffsetMap){
val partitionId: Int = tp.partition()
val dataOffset: lang.Long = value
val option: Option[Long] = zkOffsetMap.get(tp)
// kafka 有的分区,但zk 没有, 给zk新增分区
if (option == None) {
zkOffsetMap += (tp -> dataOffset)
} else {
var zkOffset: Long = option.get
if (zkOffset < dataOffset) {
zkOffset = dataOffset
zkOffsetMap += (tp -> zkOffset)
}
}
}
println("----修正后的 zkOffset--------------")
println(zkOffsetMap)
//通过KafkaUtils创建直连的DStream,并使用fromOffsets中存储的历史偏离量来继续消费数据
kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams, zkOffsetMap))
} else {
//如果zk中没有该topic的历史offset,那就根据kafkaParam的配置使用最新(latest)或者最旧的(earliest)的offset
kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams))
}
//通过rdd转换得到偏移量的范围
var offsetRanges = Array[OffsetRange]()
//迭代DStream中的RDD,将每一个时间间隔对应的RDD拿出来,这个方法是在driver端执行
//在foreachRDD方法中就跟开发spark-core是同样的流程了,当然也可以使用spark-sql
kafkaStream.foreachRDD(kafkaRDD => {
if (!kafkaRDD.isEmpty()) {
//得到该RDD对应kafka消息的offset,该RDD是一个KafkaRDD,所以可以获得偏移量的范围
//不使用transform可以直接在foreachRDD中得到这个RDD的偏移量,这种方法适用于DStream不经过任何的转换,
//直接进行foreachRDD,因为如果transformation了那就不是KafkaRDD了,就不能强转成HasOffsetRanges了,从而就得不到kafka的偏移量了
offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
val dataRDD: RDD[String] = kafkaRDD.map(_.value())
// 加载广播变量
// 初始化累加器
//执行这个rdd的aciton,这里rdd的算子是在集群上执行的
dataRDD.foreachPartition(partition =>
// executor 运行的业务在这里写
partition.foreach(x => {
println(x)
})
)
//累加器统计结果写入MySQL
for (o <- offsetRanges) {
// /consumers/group100/offsets/hainiu_html/0
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
//将该 partition 的 offset 保存到 zookeeper
// /consumers/group100/offsets/hainiu_html/888
println(s"${zkPath}__${o.untilOffset.toString}")
ZkUtils(zkClient, false).updatePersistentPath(zkPath, o.untilOffset.toString)
}
}
})
ssc.start()
ssc.awaitTermination()
}
}