
Hive介绍和原理
Hive是一个基于Hadoop的开源数据仓库工具之一,用于存储和处理海量结构化数据。它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语法的HQL(hiveSQL)语句作为数据访问接口。

hive的优缺点
优点:
- Hive 使用类SQL 查询语法, 最大限度的实现了和SQL标准的兼容,大大降低了传统数据分析人员处理大数据的难度
- 使用JDBC 接口,开发人员更易开发应用;
- 以MR 作为计算引擎(不是只能用MR)、HDFS 作为存储系统,为超大数据集设计的计算/ 扩展能力;
- 统一的元数据管理(Derby、MySql等),并可与Pig 、spark等共享;
元数据:hive表所对应的字段、属性还有表所对应存储的HDFS目录。
缺点:
- Hive 的HQL 表达的能力有限,比如不支持UPDATE、非等值连接(无法解析成MR)、DELETE、INSERT单条(不建议,会在hdfs对应表下的新文件中存放)等;insert单条代表的是 创建一个文件。
- 由于Hive自动生成MapReduce 作业, HQL 调优困难;
- 粒度较粗,可控性差,是因为数据是读的时候进行类型的转换,mysql关系型数据是在写入的时候就检查了数据的类型。
- hive生成MapReduce作业,高延迟,不适合实时查询。
与关系数据库的区别
- hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
- hive使用mapreduce做运算,与传统数据库相比运算数据规模要大得多;
- 关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据统计分析的,实时性很差;实时性差导致hive的应用场景和关系数据库有很大的区别;
- Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比Hive差很多。
| 对比 | HIVE | 关系型数据库 |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 执行 | MapReduce spark | 数据库引擎 |
| 数据存储校验 | 读时模式,存储不校验,读取校验 | 写时模式,存储校验,读不校验。 |
| 可扩展性 | 强 | 有限 |
| 执行延迟 | 高 | 低 |
| 数据处理规模 | 大 | 小 |
这其实也是数据仓库和数据库的一些区别,数据仓库可以存储结构化数据、非结构化数据,甚至是半结构化的数据(json,xml)。数仓存储的数据类型也比较多样。
hive架构
服务端组件和客户端组件。
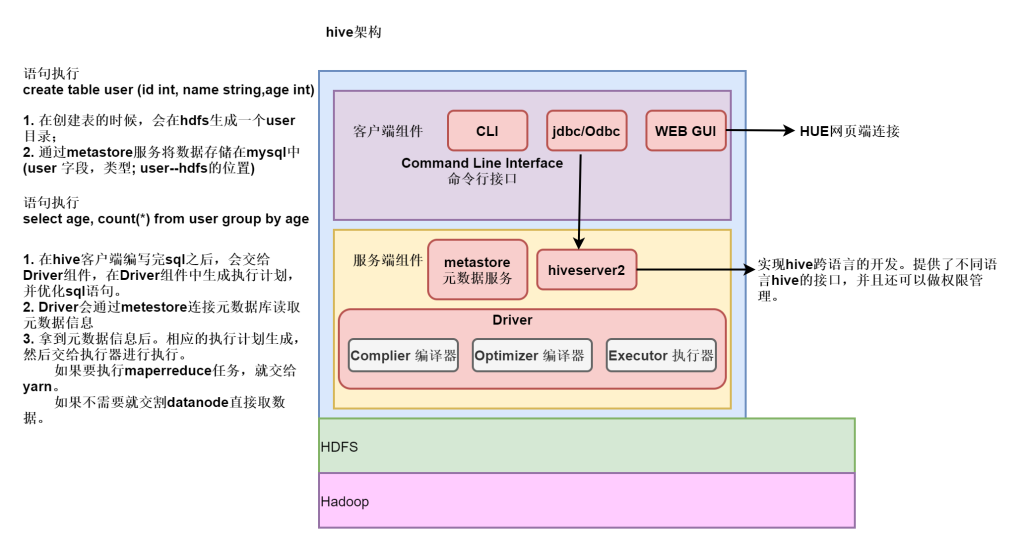
服务端组件
Driver组件:该组件包括Complier(编译)、Optimizer(优化)和Executor(执行),它的作用是将HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架。
Metastore组件:元数据服务组件,这个组件存取Hive的元数据,Hive的元数据存储在关系数据库里,Hive支持的关系数据库有Derby和Mysql。作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。
HiveServer2服务:HiveServer2是Facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,Hive集成了该服务,能让不同的编程语言调用Hive的接口。还可以做权限管理。
客户端组件
CLI:Command Line Interface,命令行接口。
JDBC/ODBC:Hive架构的JDBC和ODBC接口是建立在HiveServer2客户端之上。
WEBGUI:Hive客户端提供了一种通过网页的方式访问Hive所提供的服务。这个接口对应Hive的HWI组件(Hive Web Interface),使用前要启动HWI服务。
Hive查询的执行过程
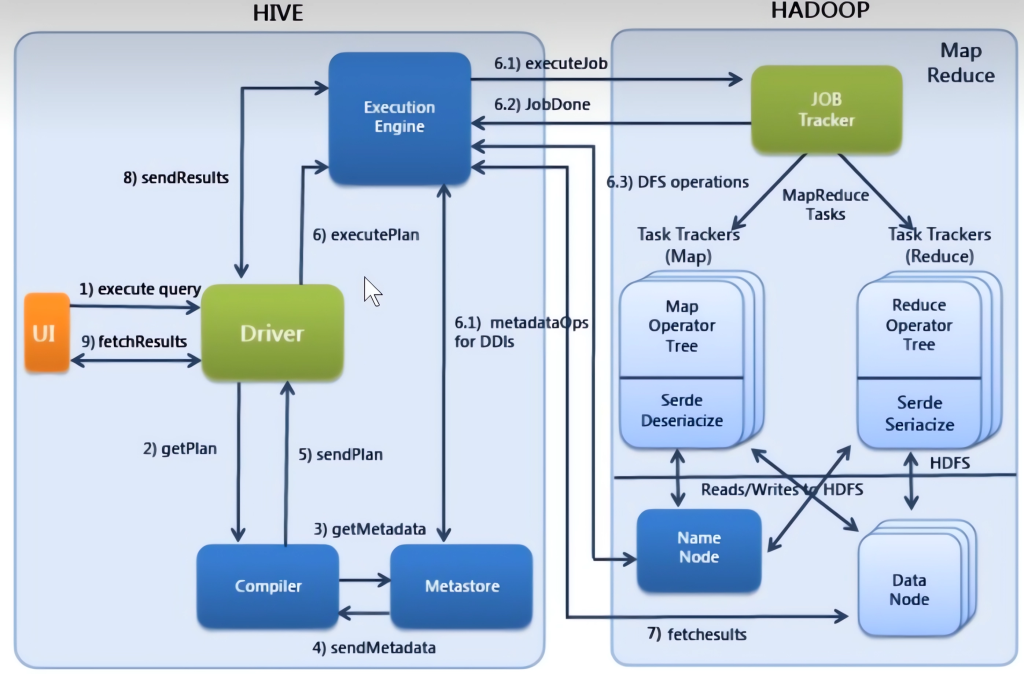
- Execute Query:hive界面如命令行或Web UI将查询发送到Driver(任何数据库驱动程序如JDBC、ODBC,等等)来执行。
- Get Plan:Driver根据查询编译器解析query语句,验证query语句的语法,查询计划或者查询条件。
- Get Metadata:编译器将元数据请求发送给Metastore(数据库)。
- Send Metadata:Metastore将元数据作为响应发送给编译器。
- Send Plan:编译器检查要求和重新发送Driver的计划。到这里,查询的解析和编译完成。
- Execute Plan:Driver将执行计划发送到执行引擎。
- Execute Job:hadoop内部执行的是mapreduce工作过程,任务执行引擎发送一个任务到资源管理节点(resourcemanager),资源管理器分配该任务到任务节点,由任务节点上开始执行mapreduce任务。
- Metadata Ops:在执行引擎发送任务的同时,对hive的元数据进行相应操作。
- Fetch Result:执行引擎接收数据节点(data node)的结果。
- Send Results:执行引擎发送这些合成值到Driver。
- Send Results:Driver将结果发送到hive接口。
hive 安装
安装mysql
首先准备安装mysql,进入官网下载mysql5.7对应版本。https://downloads.mysql.com/archives/community
这里我是ubuntu20.04,使用mysql5.7.31
- 下载mysql-server_5.7.31-1ubuntu18.04_amd64.deb-bundle.tar。并解压
- 进入解压后的文件夹,里面都是deb文件。执行以下命令
- apt-get update
- apt-get install libmecab2
- dpkg -i mysql-*.deb
- 安装完成后,mysql -u root -p 进入mysql,配置密码set password=password(‘your_password’);
- 给root用户授权
- GRANT ALL PRIVILEGES ON . TO ‘root’@’%’ IDENTIFIED BY ‘your_password’ WITH GRANT OPTION;
- FLUSH PRIVILEGES;
- 修改允许所有用户远程登录和数据库默认编码字符集。打开/etc/mysql/mysql.conf.d/mysqld.cnf,配置以下内容。
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
log-error = /var/log/mysql/error.log
# By default we only accept connections from localhost
bind-address = 0.0.0.0
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
[mysqld]
# 设置服务器的默认字符集为 UTF-8
character-set-server = utf8
# collation-server = utf8_general_ci
[client]
# 设置客户端默认字符集为 UTF-8
default-character-set = utf8
[mysql]
# 设置 MySQL 命令行工具默认字符集为 UTF-8
default-character-set = utf8
安装hive
准备环境
首先准备安装包,这里我使用的是apache-hive-3.1.3-bin.tar.gz
解压安装包,并配置环境变量/etc/profile
export HIVE_HOME=/usr/local/hive
export HIVE_CONF_DIR=/usr/local/hive/conf
export PATH=$PATH:$HIVE_HOME/binsource /etc/profile一下,让环境变量生效
修改配置文件
进入安装的/usr/local/hive/conf目录下
将hive-env.sh.template改名
mv hive-env.sh.template hive-env.sh将hive-log4j2.properties.template改名
mv hive-log4j2.properties.template hive-log4j2.properties将hive-default.xml.template改名为hive-site.xml
并将<configuration>内的内容删除,替换为一下内容
<configuration>
<!-- 数据库 start -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://nn1:3306/hive_meta?useSSL=false</value>
<description>mysql连接</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>mysql驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>数据库使用用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>your_password</value>
<description>数据库密码</description>
</property>
<!-- 数据库 end -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive使用的HDFS目录</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 其它 end -->
</configuration>在mysql中创建hive用的数据库和hive用户
--登录mysql
mysql -uroot -p'your_password'
--创建hive用户
CREATE USER 'hive'@'%' IDENTIFIED BY 'your_password';
--在mysql中创建hive_meta数据库
create database hive_meta default charset utf8 collate utf8_general_ci;
--给hive用户增加hive_meta数据库权限
grant all privileges on hive_meta.* to 'hive'@'%' identified by '12345678';
--更新
flush privileges; jar包准备
拷贝mysql驱动jar到/usr/local/hive/lib/
删除冲突的日志jar包,log4j
mv log4j-slf4j-impl-2.17.1.jar log4j-slf4j-impl-2.17.1.jar.bakhive初始化mysql
首先将hadoop目录/usr/local/hadoop/share/hadoop/common/lib中的guava-27.0-jre.jar 拷贝到hive的/usr/local/hive/lib目录中。
将原本在/usr/local/hive/lib目录中的guava-19.0.jar删除。
最后初始化mysql
schematool -dbType mysql -initSchema进入hive
命令行输入hive
可以进行show databases;创建数据库创建表等操作。
如果需要执行mapreduce任务,因为我之前配置了策略,必须指定队列,所以在执行语句之前需要配置一下使用哪个队列提交任务。
set mapreduce.job.queuename=master;在执行insert语句的时候发现执行很慢,启动了三个mr job,他会先建立一张临时表,把数据先放到临时表中,然后最后再写入对应的表里。
新创建的数据库、表和数据,都统一放到了之前配置的hdfs 上/hive/warehouse目录下了。
配置hiveserver2服务
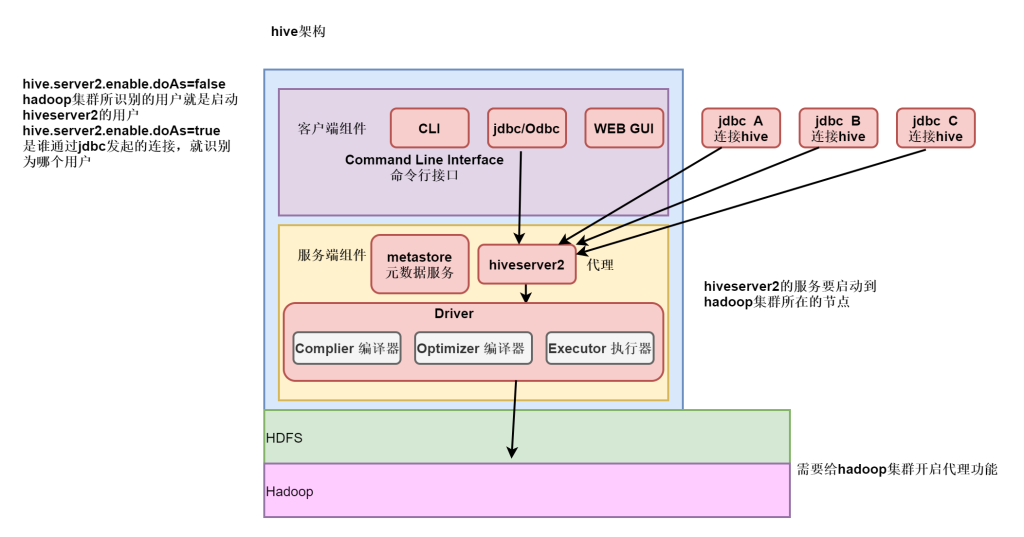
开启hadoop代理
配置/usr/local/hadoop/etc/hadoop/core-site.xml 开启hadoop代理功能
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
<description>配置hadoop(超级用户)允许通过代理用户所属组</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>nn1</value>
<description>配置hadoop(超级用户)允许通过代理访问的主机节点</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.users</name>
<value>*</value>
</property>配置完成后分发到其他节点上。
添加hiveserver2服务
修改hive中hive-site.xml文件。
<property>
<name>hive.server2.thrift.bind.host</name>
<value>nn1</value>
<description>hive开启的thriftServer地址</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>hive开启的thriftServer端口</description>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>启动hiveserver2
配置完成后,可以后台启动hiveserver2。
nohup hiveserver2 >/dev/null 2>&1 &这里2>&1的意思是将标准错误(stderr,文件描述符 2)重定向到标准输出(stdout,文件描述符 1)的位置。由于之前标准输出已经被重定向到 /dev/null,所以标准错误也会被丢弃,最终都被发送到 /dev/null。
最后的 & 是将命令放入后台运行。这样,你可以在执行这个命令后继续在当前终端执行其他命令,而不会等待 HiveServer2 启动过程的完成。
通过beeline方式连接hive
-n 代表用什么用户连接
beeline -u jdbc:hive2://nn1:10000 -n hadoop配置metastore服务
默认hive cli和hiveserver2服务内嵌了metastore服务,可以直接连接mysql数据库,但是如果连接过多会造成mysql数据库压力过大,(一般练习时可以使用)。
而且因为每个节点hive-site.xml配置文件中,都配置了metastore服务端的配置,对于metastore服务来说信息不安全,所有的配置信息在配置文件中都能看到。
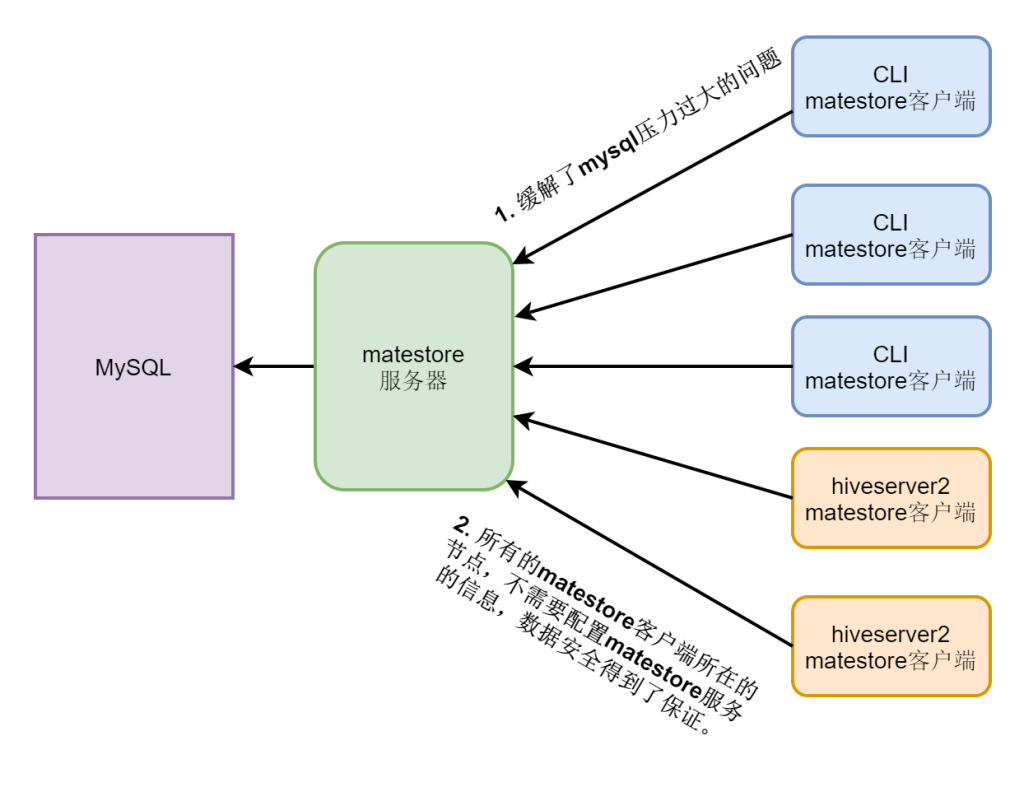
所以,我们改成了配置一个metastore服务端,所有的连接都作为一个客户端来统一访问,解决这些问题。
metastore客户端配置
在客户端配置hive-site.xml文件
<property>
<name>hive.metastore.uris</name>
<value>thrift://nn1:9083</value>
</property>metastore服务启动
nohup hive --service metastore > /dev/null 2>&1 &hive启动
hive的三种模式
使用内置的derby数据库做元数据的存储
使用内置的derby数据库做元数据的存储,操作derby数据库做元数据的管理,使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。
这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,目录不同时元数据也无法共享,不适合生产环境只适合练习。
本地模式
用mysql做元数据的存储,操作mysql数据库做元数据的管理,可以多个hive client一起使用,并且可以共享元数据。
但mysql的连接信息明文存储在客户端配置,不便于数据库连接信息保密和以后对元数据库进行更改,如果客户端太多也会对mysql造成较大的压力,因为每个客户端都自己发起连接。
安全角度:metastore存储mysql连接的数据库信息,driver和 metastore在一台机器上,数据库信息不安全。
当多台机器的Driver 、 metastore都指向一个mysql 时,mysql的压力会增大。
远程模式
使用mysql做元数据的存储,使用metastore服务做元数据的管理,优点便于元数据库信息的保密,因为只需要在运行metastore的机器上配置元数据库连接信息,客户端只需要配置metastore连接信息即可,缺点会引发单点问题,例如metastore服务挂了,其它hive终端就获取不到元数据信息了。企业环境推荐使用此种模式。
安全角度:meta从hive的driver上分离出来,在单独的机器上, 这样数据库的连接信息会安全。
启动时,需要分别启动driver和metastore
本地模式和远程模式的区别是:
- 本地模式不安全,远程模式安全。
- 本地模式不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。
远程模式需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。
服务端指的是Metastore服务所在的机器,即安装metastore的机器
启动hive
配置完成之后,先启动metasotre服务,再启动hive client。
Hive 基础操作
查看hfds文件
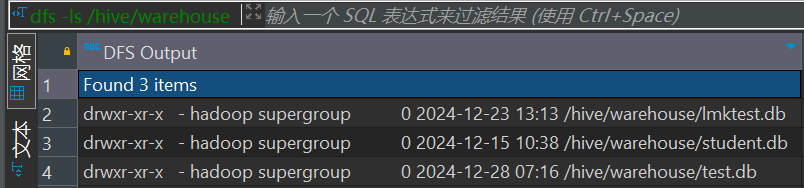
在hive中可以使用dfs命令查看hdfs的目录
dfs -ls /hive/warehouse返回内容:
创建数据库
# 创建数据库
create database lmktest;显示建库语句
show create database lmktest;进入数据库
use lmktest;创建表
如果想在某个数据库下创建表,首先进入数据库(use 数据库名)
如果没有进入数据库,那默认是default。
create table user_info(id int,name string);查看表结构
desc user_info;查看建表语句
show create table user_info;插入数据
Insert
插入数据的时候默认会走mapreduce程序
insert into user_info values(1,'lmk');插入报错,需要需要指定队列
set mapreduce.job.queuename=master;文件添加数据
我们插入数据后,可以在hdfs对应的目录下找到数据存储的文件。
我现在创建的数据就在/hive/warehouse/lmktest.db/user_info目录下000000_0。
如果想要直接在文件中添加数据或者在目录中加入新文件,文件名可以任意,就需要与他默认的存储格式相同,先把文件下载下来查看一下是什么格式。
-- 将文件get到本地
hadoop fs -get /hive/warehouse/lmktest.db/user_info/000000_0 ./test/
-- vim 打开查看文件内容
vim 000000_0可以看到文件的内容为1^Almk。可以看到他的分隔符是^A,这个其实是”\001″。linux中输入方式是Ctrl+v Ctrl+a,相应的”\002″输入方式是Ctrl+v Ctrl+b。
直接写入文件的方式要比insert的速度快很多,因为不需要经过mapreduce的过程。
插入数据自定义分隔符
如果我们不想使用默认的”\001″分割,那么可以使用语句自定义分隔符。
create table dept (id int, deptno string, deptname string) row format delimited fields terminated by ' ';mysql中元数据表
数据库相关
DBS
存储Hive中所有数据库的基本信息
| 元数据表字段 | 说明 | 示例数据 |
| DB_ID | 数据库ID | 6 |
| DESC | 数据库描述 | NULL |
| DB_LOCATION_URI | 数据库HDFS路径 | hdfs://ns1/hive/warehouse/lmktest.db |
| NAME | 数据库名 | lmktest |
| OWNER_NAME | 数据库所有者用户名 | hadoop |
| OWNER_TYPE | 所有者角色 | USER |
DATABASE_PARAMS
存储数据库的相关参数,在CREATE DATABASE时候用
| 元数据表字段 | 说明 | 示例数据 |
| DB_ID | 数据库ID | 1 |
| PARAM_KEY | 参数名 | createdby |
| PARAM_VALUE | 参数值 | hadoop |
表、视图相关
TBLS
存储Hive表、视图、索引表的基本信息。
| 元数据表字段 | 说明 | 示例数据 |
| TBL_ID | 表ID | 7 |
| CREATE_TIME | 创建时间 | 1734329989 |
| DB_ID | 数据库ID | 6,对应DBS中的DB_ID |
| LAST_ACCESS_TIME | 上次访问时间 | 0 |
| OWNER | 所有者 | hadoop |
| OWNER_TYPE | 所有者类型 | USER |
| RETENTION | 保留字段 | 0 |
| SD_ID | 序列化配置信息 | 7,对应SDS表中的SD_ID |
| TBL_NAME | 表名 | dept |
| TBL_TYPE | 表类型 | MANAGED_TABLE(内部表) (EXTERNAL_TABLE(外部表)、INDEX_TABLE(索引表)、VIRTUAL_VIEW(视图)) |
| VIEW_EXPANDED_TEXT | 视图的详细HQL语句 | NULL |
| VIEW_ORIGINAL_TEXT | 视图的原始HQL语句 | NULL |
| IS_REWRITE_ENABLED | 0 |
在Hive上有两种类型的表,一种是Managed Table(内部表),另一种是External Table(外部表)。它俩的主要区别在于:当我们drop表时,Managed Table会同时删去data和meta data,而External Table只会删meta data。
TABLE_PARAMS
存储表/视图的属性信息。
| 元数据表字段 | 说明 | 示例数据 |
| TBL_ID | 表ID | 1 |
| PARAM_KEY | 属性名 | COLUMN_STATS_ACCURATE |
| PARAM_VALUE | 属性值 | {“BASIC_STATS”:”true”,”COLUMN_STATS”:{“id”:”true”,”name”:”true”}} |
TBL_PRIVS
存储表/视图的授权信息。
| 元数据表字段 | 说明 | 示例数据 |
| TBL_GRANT_ID | 授权ID | 1 |
| CREATE_TIME | 授权时间 | 1734259084 |
| GRANT_OPTION | 1 | |
| GRANTOR | 授权执行用户 | hadoop |
| GRANTOR_TYPE | 授权者类型 | USER |
| PRINCIPAL_NAME | 被授权用户 | hadoop |
| PRINCIPAL_TYPE | 被授权用户类型 | USER |
| TBL_PRIV | 权限 | INSERT |
| TBL_ID | 表ID | 1,对应TBLS表中的TBL_ID |
| AUTHORIZER | 授权人 | SQL |
文件存储信息相关
由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中。
SDS
保存文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。
| 元数据表字段 | 说明 | 示例数据 |
| SD_ID | 存储信息ID | 7 |
| CD_ID | 字段信息ID | 7,对应CDS表 |
| INPUT_FORMAT | 文件输入格式 | org.apache.hadoop.mapred.TextInputFormat |
| IS_COMPRESSED | 是否压缩 | 0 |
| IS_STOREDASSUBDIRECTORIES | 是否以子目录存储 | 0 |
| LOCATION | HDFS路径 | hdfs://ns1/hive/warehouse/lmktest.db/dept |
| NUM_BUCKETS | 分桶数量 | -1 |
| OUTPUT_FORMAT | 文件输出格式 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat |
| SERDE_ID | 序列化类ID | 7,对应SERDES表 |
SD_PARAMS
存储Hive存储的属性信息,在创建表时候使用。
STORED BY ‘storage.handler.class.name’ [WITH SERDEPROPERTIES (…)指定。
| 元数据表字段 | 说明 | 示例数据 |
| SD_ID | 存储配置ID | 1 |
| PARAM_KEY | 存储属性名 | |
| PARAM_VALUE | 存储属性值 |
SERDES
存储序列化使用的类信息。
| 元数据表字段 | 说明 | 示例数据 |
| SERDE_ID | 序列化类配置ID | 7 |
| NAME | 序列化类别名 | NULL |
| SLIB | 序列化类 | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
| DESCRIPTION | NULL | |
| SERIALIZER_CLASS | NULL | |
| DESERIALIZER_CLASS | NULL | |
| SERDE_TYPE | 0 |
SERDE_PARAMS
存储序列化的一些属性、格式信息,比如:行、列分隔符。
| 元数据表字段 | 说明 | 示例数据 |
| SERDE_ID | 序列化类配置ID | 1 |
| PARAM_KEY | 属性名 | serialization.format |
| PARAM_VALUE | 属性值 | 1 |
字段相关
COLUMNS_V2
存储表对应的字段信息。
| 元数据表字段 | 说明 | 示例数据 |
| CD_ID | 字段信息ID | 7 |
| COMMENT | 字段注释 | NULL |
| COLUMN_NAME | 字段名 | deptname |
| TYPE_NAME | 字段类型 | string |
| INTEGER_IDX | 字段顺序 | 2 |
表分区相关
PARTITIONS
存储表分区的基本信息。
| 元数据表字段 | 说明 | 示例数据 |
| PART_ID | 分区ID | 1 |
| CREATE_TIME | 分区创建时间 | |
| LAST_ACCESS_TIME | 最后一次访问时间 | |
| PART_NAME | 分区名 | pt=2024-12-16 |
| SD_ID | 分区存储ID | 7 |
| TBL_ID | 表ID | 7 |
PARTITION_KEYS
存储分区的字段信息。
| 元数据表字段 | 说明 | 示例数据 |
| TBL_ID | 表ID | 7 |
| PKEY_COMMENT | 分区字段说明 | |
| PKEY_NAME | 分区字段名 | pt |
| PKEY_TYPE | 分区字段类型 | string |
| INTEGER_IDX | 分区字段顺序 | 1 |
PARTITION_KEY_VALS
存储分区字段值。
| 元数据表字段 | 说明 | 示例数据 |
| PART_ID | 分区ID | 1 |
| PART_KEY_VAL | 分区字段值 | 2024-12-16 |
| INTEGER_IDX | 分区字段值顺序 | 0 |
PARTITION_PARAMS
存储分区的属性信息。
| 元数据表字段 | 说明 | 示例数据 |
| PART_ID | 分区ID | 1 |
| PARAM_KEY | 分区属性名 | numFiles、numRows |
| PARAM_VALUE | 分区属性值 | 1、63665 |
Hive数据类型
数字类型
| Hive数据类型 | Java数据类型 | 长度 | 示例 |
|---|---|---|---|
| TINYINT | Byte | 1 byte,有符号整数,-128 ~ 127 | 100Y |
| SMALLINT | Short | 2 byte,有符号整数,-32768 to 32767 | 100S |
| INT/INTEGER | Int | 4 byte, 有符号整数,-2147483648 ~ 2147483647 | 100 |
| BIGINT | Long | 8 byte,有符号整数,-9223372036854775808 ~ 9223372036854775807 | 100L |
| FLOAT | Float | 4 byte,单精度浮点数 | 1.234 |
| DOUBLE | Double | 8 byte,双精度浮点数 | 1.234 |
| DECIMAL | BigDecimal | 表示 Java 中不可变的任意精度十进制数字,不指定长度默认decimal(10, 0) | 1.234 |
| NUMERIC | BigDecimal | 与DECIMAL 类似,Hive 3.0.0 引入 | 1.234 |
字符类型
| Hive数据类型 | Java数据类型 | 长度 |
|---|---|---|
| STRING | String | 字符串,可以用单引号(’)或双引号(”)定义。 |
| VARCHAR | String | 是STRING 存储变长的文本,对长度没有限制;varchar 长度上只允许在 1-65355 之间,定义长度后超出长度截断。 |
| CHAR | String | CHAR 是固定长度的,也就是说比指定长度值短的值空缺部分会用空格填充,但在尾部的空格不影响字符串的比较。最大长度固定为 255。 |
时间类型
| Hive数据类型 | Java数据类型 | 格式 |
|---|---|---|
| TIMESTAMP | java.sql.Timestamp | 时间戳,支持具有可选纳秒精度的传统 UNIX 时间戳,可以是以秒为单位的整数。 |
| DATE | java.sql.Date | 日期,格式为 YYYY-MM-DD |
其他类型
| Hive数据类型 | Java数据类型 | 格式 |
|---|---|---|
| BOOLEAN | Boolean | 布尔类型,true或者false |
| BINARY | byte[] | 字节数组 |
复杂类型
| Hive数据类型 | Java数据类型 | 描述 | 格式 |
|---|---|---|---|
| STRUCT | class | STRUCT类似于java的类变量使用,Hive中定义的struct类型也可以使用点来访问。从文件加载数据时,文件里的数据分隔符要和建表指定的一致。 | 只有字段值:struct(val1, val2, val3, …) 有字段名和字段值: named_struct(name1, val1, name2, val2, …) |
| ARRAY | arr[] | 表示一组相同数据类型的集合,下标从零开始,通过arr[下标] 获取元素数据。 | array(1,2,3),arr[0] |
| MAP | map | 是一组键值对的组合,可以通过KEY访问VALUE,键值之间同样要在创建表时指定分隔符。 | map_col[‘name’],map(‘a’, 1, ‘b’, 2, ‘c’, 3) |
| UNIONTYPE | Object | 特殊的数据类型,它允许一个字段存储多个不同类型的数据(例如:INT、STRING 或 DOUBLE)。 | create_union(0, “zhansan”, 19, 8000.88) |
Hive除了支持STRUCT、ARRAY、MAP这些原生集合类型,还支持集合的组合,不支持集合里再组合多个集合。
json格式数据处理
JSON是一个包含对象或数组的字符串。
- 数据为 键 / 值 (name/value)对;
- 数据由逗号(,)分隔;
- 大括号保存对象(object);
- 方括号保存数组(Array);
例如:
{"code":"100"}
#对象由花括号括起来的逗号分割的成员构成,成员是字符串键和上文所述的值由逗号分割的键值对组成:
{"code":20,"type":"mysql"}
#数组是由方括号括起来的一组值构成:
{"datesource":[
{"code":"20", "type":"mysql"},
{"code":"20", "type":"mysql"},
{"code":"20", "type":"mysql"}
]}GET_JSON_OBJECT
hive中提供了获取json数据的方法GET_JSON_OBJECT
json结构获取数据的方式与之前使用kettle获取接口数据的方式相同,$代表json串。
select get_json_object('{"code":20,"type":"mysql"}', '$.type')
-- 返回值
-- mysql
select get_json_object('{"datesource":[
{"code":"20", "type":"mysql"},
{"code":"20", "type":"mysql"},
{"code":"20", "type":"mysql"}
]}', '$.datesource[*]')
-- 不写[*]也一样
-- 返回值
-- [{"code":"20","type":"mysql"},{"code":"20","type":"mysql"},{"code":"20","type":"mysql"}]select get_json_object('{"datesource":[
{"code":"21", "type":"mysql"},
{"code":"22", "type":"mysql"},
{"code":"23", "type":"mysql"}
]}', '$.datesource[1]')
-- 返回值 ,可以看出下标从0开始
-- {"code":"22","type":"mysql"}JSON_TUPLE
为了解决get_json_object一次解析不了整个JSON文件的问题,我们就有了json_tuple这个函数,一条便能处理一条JSON数据。
语法如下:
json_tuple(json_string, k1, k2 ...)因为我们使用json_tuple函数后得到的是多个字段,所以如果想要指定别名,需要使用(col1, col2…)的格式
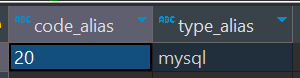
案例:
select json_tuple('{"code":20,"type":"mysql"}', 'code', 'type') as (code_alias, type_alias)返回值:
hive解析json数组
当我们遇到需要解析json数组的时候,例如json字符串,[{“website”:”baidu.com”,”name”:”百度”},{“website”:”google.com”,”name”:”谷歌”}]
在hive中\\进行转义
首先,使用regexp_replace,用正则进行字符串替换,把[]替换成空串。
select regexp_replace('[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\[|\\]','');
-- 返回值
{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}然后考虑将两个json串拿到,这里我们需要用split,但是中间的‘,’是不行的,所以先把中间‘,’替换成|。然后再split切分分成两个json字符串组成的数组。
select split(regexp_replace(regexp_replace('[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\[|\\]',''), '\\}\\,\\{', '\\}\\|\\{'), '\\|')
-- 返回值
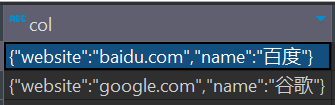
["{\"website\":\"baidu.com\",\"name\":\"百度\"}","{\"website\":\"google.com\",\"name\":\"谷歌\"}"]然后将数组中两个字符串变成两行数据,这里需要用到explode列转行语法。
explode(Array OR Map)explode()函数接收一个array或者map类型的数据作为输入,然后将array或map里面的元素按照每行的形式输出,即将hive一列中复杂的array或者map结构拆分成多行显示,也被称为列转行函数。
select explode(split(regexp_replace(regexp_replace('[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\[|\\]',''), '\\}\\,\\{', '\\}\\|\\{'), '\\|'))返回值
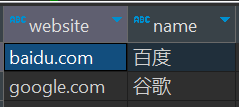
最后,我们可以把这个结果集当作一张表,使用json_tuple处理成我们想要的字段样式。
select json_tuple(json, 'website', 'name') as (website, name)
from
(select explode(split(regexp_replace(regexp_replace('[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\[|\\]',''), '\\}\\,\\{', '\\}\\|\\{'), '\\|')) as json) v返回值
类型转换
显性转换
cast()
使用cast函数进行强制类型转换;如果强制类型转换失败,返回 NULL。
select cast(1 as string)隐式转换
Hive 的数据类型是可以进行隐式转换的,类似于oracle、 Java 的类型转换。
如果查询中将一种浮点类型和另一种浮点类型的值做对比,Hive 会将类型转换成两个浮点类型中值较大的那个类型,例如:将 FLOAT 类型转换成 DOUBLE 类型;当然如果需要的话,任意整型会转化成 DOUBLE 类型。总的来说数据转换遵循以下规律:
- 任何整数类型都可以隐式转换为一个范围更广的类型。tinyInt => int;int => bigint
- 所有整数类型、float、string(都是数字)都可以隐式转换为 Double
- tinyint、smallint、int => float
- boolean 不会转换
hive操作符
关系操作符
| 运算符 | 操作数 | 描述 |
|---|---|---|
| A = B | 所有基本类型 | 如果表达A等于表达B,结果TRUE ,否则FALSE。 |
| A != B | 所有基本类型 | 如果A不等于表达式B表达返回TRUE ,否则FALSE。 |
| A < B | 所有基本类型 | 如果表达式A小于表达式B返回TRUE,否则FALSE。 |
| A <= B | 所有基本类型 | 如果表达式A小于或等于表达式B返回TRUE,否则FALSE。 |
| A > B | 所有基本类型 | 如果表达式A大于表达式B返回TRUE,否则FALSE。 |
| A >= B | 所有基本类型 | 如果表达式A大于或等于表达式B返回TRUE,否则FALSE。 |
| A IS NULL | 所有类型 | 如果表达式的计算结果为NULL返回TRUE,否则FALSE。 |
| A IS NOT NULL | 所有类型 | 如果表达式A的计算结果为NULL返回FALSE,否则TRUE。 |
| A LIKE B | 字符串 | 如果字符串模式A匹配到B,否则FALSE。关系型数据库中的like功能。 |
| A RLIKE B | 字符串 | 字符串 B是否在A里面,在是TRUE,否则是FALSE(B可以是Java正则表达式) |
| A REGEXP B | 字符串 | 字符串 等同于RLIKE. |
这里大部分的运算符都非常熟悉了,只有RLIKE和REGEXP是没有用过的,这里试一下,看看都有什么用法。
-- 使用正则匹配
select * from test where map_col['english'] RLIKE '\\S';
-- 有空白字符
select 'fsef ' rlike '\\s';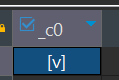
算数运算符
这些运算符支持的操作数各种常见的算术运算。所有这些返回数字类型。
| 运算符 | 操作 | 描述 |
|---|---|---|
| A + B | 所有数字类型 | A加B的结果 |
| A – B | 所有数字类型 | A减去B的结果 |
| A * B | 所有数字类型 | A乘以B的结果 |
| A / B | 所有数字类型 | A除以B的结果 |
| A % B | 所有数字类型 | A除以B产生的余数 |
| A & B | 所有数字类型 | A和B的按位与结果 |
| A | B | 所有数字类型 | A和B的按位或结果 |
| A ^ B | 所有数字类型 | A和B的按位异或结果 |
| ~A | 所有数字类型 | A按位非的结果 |
~A的运算之前确实不怎么用过
select ~6, ~9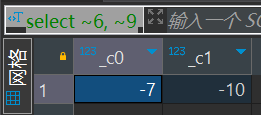
逻辑运算符
运算符是逻辑表达式,所有这些返回TRUE或FALSE。
| 运算符 | 操作 | 描述 |
|---|---|---|
| A AND B | boolean | 如果A和B都是TRUE,返回true,否则FALSE。 |
| A OR B | boolean | 如果A或B或两者都是TRUE,返回true,否则FALSE。 |
| NOT A | boolean | 如果A是FALSE,返回true,否则FALSE。 |
hive增删改操作
创建案例test表
在hive中建表语句与常用关系型数据库类似,只不过可以使用的数据类型可能不同,比如下面的语句。
CREATE TABLE `lmktest.test`(
`id` int,
`struct_col` struct<name:string,contory:string>,
`array_col` array<string>,
`map_col` map<string,string>,
`union_col` map<string,array<string>>
)
row format delimited fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';`也可以不加,在这其中有一些关键字,分别有着不同的用法。
row format delimited fields terminated by
插入数据自定义分隔符
collection items terminated by
指定集合的分隔符,比如array,struct
map keys terminated by
指定map中key和value的分隔符
insert
普通插入数据方式,与关系型数据库相同,这里不再介绍。
语法如下
INSERT INTO lmktest.test
VALUES (
100,
NAMED_STRUCT('name', 'lmk', 'contory', 'cn'),
array('23', '12', '42'),
map('english', 'abc'),
map('english', array('23', '12', '42'))
);数据插入后,数据显示内容如下:

可以查看一下文件存储的分隔符,找到相关文件,看到文件的内容如下:
100,lmk-cn,23-12-42,english:abc,english:23^D12^D42这里如果字段中嵌套了复杂结构,是无法约束复杂结构中分隔符的。
insert into
insert into 插入数据的语法与关系型数据库相同,下面两种写法都可以。
insert into user_info select * from user_info where id = 1
insert into table user_info select * from user_info where id = 1执行语句后会自动执行相关mapreduce任务。
insert overwrite
insert overwrite 只有一种写法,不能省略table关键字。如果使用overwrite插入,那么会将原表的数据覆盖插入,相当于插入前截断表。
insert overwrite table user_info select * from user_info where id in (2, 3, 4)hive DDL操作
(Data Definition Language)数据定义语言,也是比较熟悉的东西了。
create
创建语句,语法公式如下:
CREATE DATABASE/SCHEMA, TABLE, VIEW, FUNCTION, INDEXdrop
DROP DATABASE/SCHEMA, TABLE, VIEW, INDEXTRUNCATE
TRUNCATE TABLEALTER
ALTER DATABASE/SCHEMA, TABLE, VIEWSHOW
查看列表
SHOW DATABASES/SCHEMAS, TABLES, TBLPROPERTIES, PARTITIONS, FUNCTIONS, INDEX[ES], COLUMNS查看创建语句
SHOW CREATE TABLE查看结构语句
DESCRIBE(DESC) DATABASE/SCHEMA, table_name, view_name
如果想要查看当前使用哪个数据库,需要使用函数查看。
select current_database()hive数据库
创建数据库
语法公式如下:
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];DATABASE 和 SCHEMA 的使用是一样的,CREATE DATABASE 是(HIVE-675)增加的。
WITH DBPROPERTIES 是(HIVE-1836)增加的,可以指定一下数据属性数据。
案例
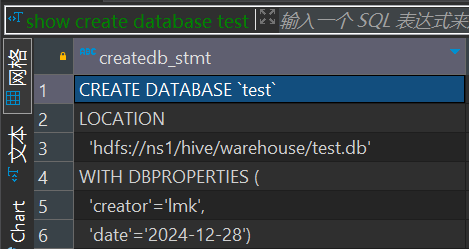
-- 创建数据库test
create database if not exists test with dbproperties('creator'='lmk','date'='2024-12-28')查看库创建语句
-- 查看创建语句
show create database test返回结果:
查看数据库结构
desc database test返回内容:

查看当前使用数据库
select CURRENT_DATABASE() 切换数据库
use test;也可通过 hive.cli.print.current.db 参数将当前数据打印到CLI提示符。
set hive.cli.print.current.db=true;这个属性可以直接配置到hive-site.xml中永久生效,set命令保障当前session生效。
修改数据库属性
ALTER DATABASE database_name SET DBPROPERTIES (property_name=property_value, ...);删除数据库
DROP DATABASE [IF EXISTS] database_name [RESTRICT|CASCADE];hive数据表
表的类型
hive中,有四种表,内部表、外部表、分区表、分桶表。
他们各有不同,详情查看图:

创建表
语法公式如下:
-- EXTERNAL 代表外部表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
-- 分区表设置 分区的字段和类型
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
-- 桶表设置 按照什么字段进行分桶
[CLUSTERED BY (col_name, col_name, ...)
-- 桶内的文件 是按照 什么字段排序 分多少个桶
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
-- 分隔符 + 序列化反序列化
[ROW FORMAT row_format]
-- 输入输出格式,默认textfile不压缩,可以直接查看
[STORED AS file_format]
-- 表所对应的hdfs目录,多为创建外部表使用
[LOCATION hdfs_path] CREATE TABLE
创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常;
EXTERNAL
EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION);
COMMENT
可以为表与字段增加描述;
ROW FORMAT
指定分隔符,上面创建案例表的时候也有用到。
-- 字段间分隔符
DELIMITED [FIELDS TERMINATED BY char]
-- 集合间分隔符
[COLLECTION ITEMS TERMINATED BY char]
-- map k v 间分隔符
[MAP KEYS TERMINATED BY char]
-- 行分隔符
[LINES TERMINATED BY char]
--序列化和反序列化设置
SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。
hive本质还是使用mapreduce做计算,如果数据想要放到hdfs做计算,就必须经过序列化和反序列化。
Serialize把hive使用的java object转换成能写入hdfs的字节序列,或者其他系统能识别的流文件。
Deserilize把字符串或者二进制流转换成hive能识别的java object对象。
实际就是将java的对象序列化成为一个二进制数组,最后写入到hdfs中。后面如果我们要读取数据的时候,需要将二进制的数组或者字符串反序列化识别成一个java对象。
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
STORED AS
- SEQUENCEFILE –包含键值对的二进制的文件存储格式,支持压缩,可以节省存储空间
- TEXTFILE –最普通的文件存储格式,内容是可以直接查看(默认的)
- AVRO –带有schema文件格式的, 一行的数据是个map,添加字段方便
- RCFile(Record Columnar File) –是列式存储文件格式,适合压缩处理。对于有成百上千字段的表而言,RCFile更合适。
- ORC(Optimized Row Columnar) — 是列式存储文件格式,带有压缩和轻量级索引, 一行数据是个数组,查询快,不适合添加字段
- parquet — 是列式存储文件格式,带有压缩和轻量级索引, 和orc比较类似
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。
如果数据需要压缩,使用 STORED AS SEQUENCEFILE、RCFile、ORC 。
内部表
内部表就是普通的表,创建语句与关系型数据库的常规表一样。
创建的时候直接create就可以了,不用加什么关键字。
外部表
这里我们创建外部表,就可以提前准备数据文件,然后创建表关联数据文件了。这里需要注意的是数据的分隔符一定要对应好,如果文件中的分隔符不是默认/001。那么创建外部表的时候要指定对应的分割符才能识别出来。
create external table ext_user (id int, username string)
row format delimited fields terminated by ' '
stored as textfile
location '/test/createtable'
location中需要指定到表对应的目录,指定文件会报错。
分区表
创建分区表的好处是查询时,不用全表扫描,查询时只要指定分区,就可查询分区下面的数据。
分区表可以是内部表,也可以是外部表。
建表方式有两种
单个partition 格式
--在表中添加单个partition,相当于hdfs:'/……/表名/20141117/00'
alter table 分区表 add IF NOT EXISTS partition(分区字段='值1',分区字段='值2') location '指定分区在HDFS上目录结构';多个partition 格式
--在表中添加多个partition
--相当于hdfs:'/……/表名/20141117/00'
--相当于hdfs:'/……/表名/20141117/01'
alter table par_test add partition(day='20141117',hour='00') location '20141117/00' partition(day='20141117',hour='01') location '20141117/01';查看表分区
show partitions tableName;删除partition
alter table 表名 drop if exists partition(字段1='值1',字段2='值2');案例1
-- 创建一个分区表
create table book(id int, name string) partitioned by (country string) row format delimited fields terminated by ' ';
-- 查看表结构
desc book;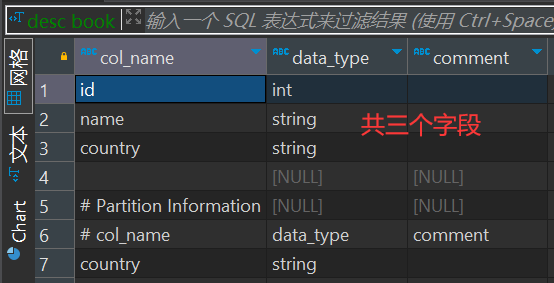
表创建好以后是没有任何分区的,接下来给表增加分区。
alter table book add partition(country = 'cn');当我们执行完这条alter语句后,hive会先将分区的元数据记录到mysql中,同时在hdfs中创建一个分区目录,目录名就是country = ‘cn’。

我们可以使用location指定创建的分区名称
alter table book add partition(country = 'ru') location 'ru'
也可以进行删除语句如下:
alter table book drop partition(country='ru');为表插入数据,我们先准备数据文件,内容不需要写入分区字段。
-- 准备数据文件,内容如下
-- 1 sanguo
-- 2 shuihu
-- 3 hongloumeng
-- 4 xiyouji
-- select 查询数据
select * from book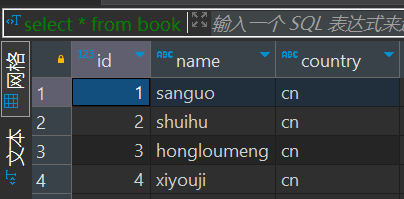
注意,这里如果我们手动创建了一个分区文件想要查询,是查询不到的。因为上面提到过,创建分区的时候首先将元数据信息存储到mysql中,我们手动创建的分区文件是没有将元数据存放到mysql中的。
如果我们想要添加,有两种方式
- 还是需要再使用alter语句添加partition;
- 手动修复分区
- msck repair table book;
查看都有哪些分区,使用show
show partitions book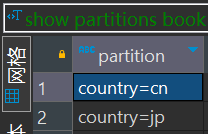
案例2外部分区表
创建表,这里我们创建外部分区表,分隔符使用\t,指定hdfs位置/test/createtable/student_par。
create external table student_par(name string) partitioned by (age int, sex string) row format delimited fields terminated by '\t' location '/test/createtable/student_par'表创建完成后,增加分区,这里有两个分区字段,创建出的目录是两层。
alter table student_par add partition(age = 10, sex = 'boy') location '10/boy'如果我们要放文件数据进去,需要将文件放到最里层。
如果想查询哪个分区对应location,可以通过SQL元数据查询。
select t1.NAME
,t2.TBL_NAME
,t4.PART_NAME
,t3.LOCATION
from DBS t1
left join TBLS t2 on t1.DB_ID = t2.DB_ID
left join PARTITIONS t4 on t2.TBL_ID = t4.TBL_ID
left join SDS t3 on t4.SD_ID = t3.SD_ID
where t1.NAME = 'lmktest'
and t2.TBL_NAME like 'student_par' 
也可以给表添加多个分区
alter table lmktest.student_par add IF NOT EXISTS partition (age=11,sex='boy') location '11/boy' partition (age=11,sex='girl') location '11/girl';如果想要查看查询的时候是否只查询了当前区域的数据,那么可以执行一个mr任务查看,比如count操作,然后去页面查看。
分桶表
对于每一个表,可以进一步组织成桶,其实就是更细粒度的数据抽样查询。Bucket是对指定列进行hash,然后根据hash值除以桶的个数进行取余,决定该条记录存放在哪个桶中。分桶表还支持在桶内对数据排序。
分桶表的数据更加分散,方便我们进行抽样查询。
分区以后的表还可以再分桶,但是不要与分区字段相同,不然分桶就没有意义。
公式:whichBucket = hash(columnValue) % numberOfBuckets
总结:桶表就是对一次进入表的数据进行文件级别的划分。
创建桶表
create external table t_truckenter(
id string,
numberplate string,
type int,
code string,
uptime bigint)
comment 'This is thee buckets_table table'
partitioned by (dt string)
-- 分桶字段,按照uptime降序排序,分10个桶
clustered by(code) sorted by(uptime desc) into 10 buckets
location 'hdfs://ns1/test/createtable/t_truckenter'分桶表不能通过hadoop fs -put的方式,将数据直接写入到桶表所在的hdfs目录,因为这样存放相当于没有分桶操作。
实现方式:
- 创建一个临时表,把数据导入到临时表中,然后再通过查询导入的方式,将临时表的数据导入到桶表中。在导入的时候,会生成mapreduce任务,将来有多少个桶,就会对应多少个reducetask,每个reducetask都有一个结果文件,多少个reduce就会生成多少个文件。
- load的方式,与上面的方式相似,也是生成mapreduce任务。
分桶表数据导入
这里我们使用第一种方式实现,首先创建一个临时表,并给表添加分区,这里我准备的数据是\t分隔。
CREATE TABLE t_truckenter_temp(
id string,
numberplate string,
type int,
code string,
uptime bigint)
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t';
alter table t_truckenter_temp add if not exists partition (dt = '20250101') location '20250101';当前表分多少桶是根据数据来决定的,按照country分组进行count操作,从大到小排列求和,占总条数90%为止,有多少个country,就分多少组。
使用select语句给分区插入数据
insert overwrite table t_truckenter partition(dt='20250101')
select id,
numberplate,
type,
code,
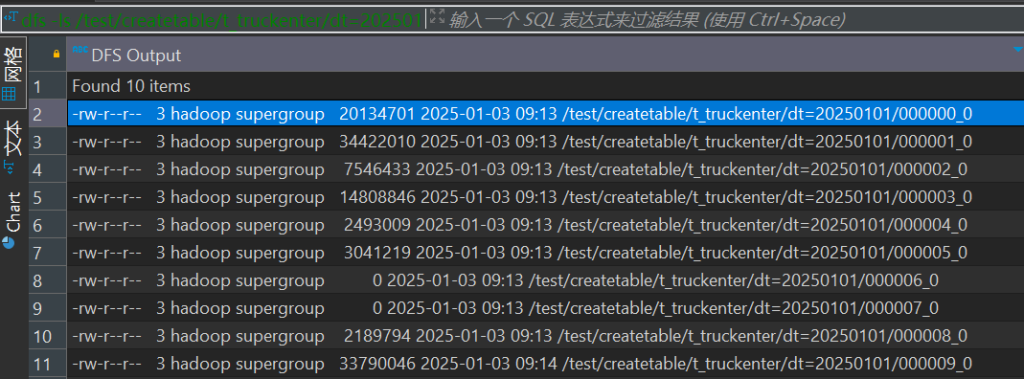
uptime from t_truckenter_temp where dt='20250101';这里我们查看文件,生成了10个文件
抽样查询
当数据量特别大时,对全体数据进行处理存在困难时,抽样就显得尤其重要了。抽样可以从被抽取的数据中估计和推断出整体的特性,是科学实验、质量检验、社会调查普遍采用的一种经济有效的工作和研究方法。
语法如下:
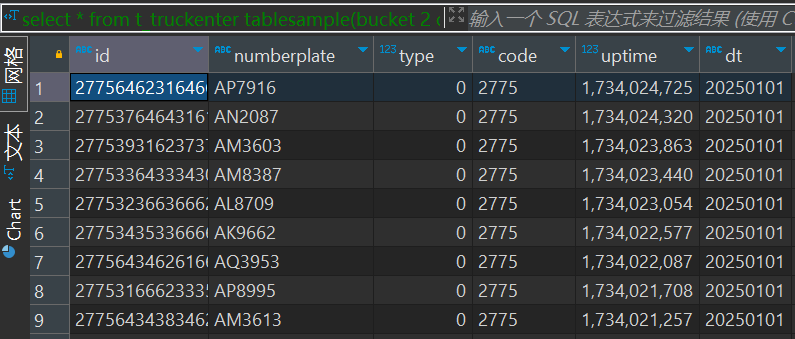
table_sample: TABLESAMPLE (BUCKET x OUT OF y [ON colname])
select * from t_truckenter tablesample(bucket 2 out of 10 on code)返回结果
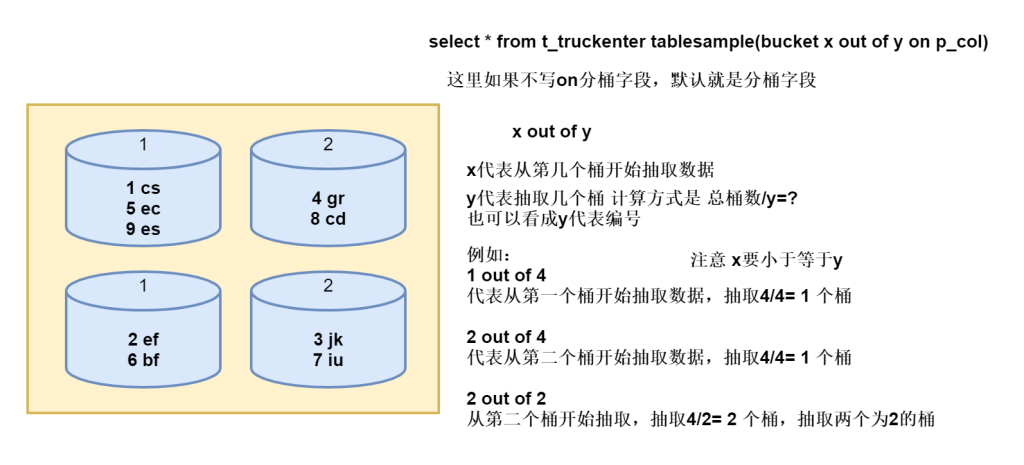
普通表也可以抽样,只不过还是全表扫描,不会分桶。
特性
- 如果桶表分桶字段和抽样字段不一致,扫描全表
- 如果表不是桶表,抽样扫描全表
- 如果桶表分桶字段和抽样字段一致,不扫描全表
hive3.0现在分桶抽样计算是有bug的,使用count进行统计的时候数据是错误的。
AVRO表
创建表
之前说存储格式,默认都是TEXTFIEL,也可以选择avro格式。
如果后续表经常进行增删字段的操作,那么就可以创建AVRO格式存储的表。
建表语法如下
CREATE EXTERNAL TABLE IF NOT EXISTS word_avro
-- AVRO表序列化和反序列化的方式是固定的
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
-- 指定schema文件路径,指定字段
WITH SERDEPROPERTIES ('avro.schema.url'='/test/createtable/config/avro.schema')
-- 如果不写就是默认Textfile
STORED AS avro
LOCATION '/test/createtable/word_avro';创建schema文件
如果马上执行会报错,因为找不到avro.schema文件,schema文件用json类型表示,格式如下
{
"type": "record",
"name": "RunRecord",
"namespace": "com.lmk",
-- 写入文件名和文件类型,下面是两个字段
"fields": [{
"name": "word",
"type": "string"
}, {
"name": "num",
"type": "long",
"default":1
}
]
}avro表因为存储数据的方式与常规表的方式不同,所以没法直接将准备文件写入表中,需要从一张表中查询数据导入。当然使用insert into语句单条插入也可以,但是慢,之前说过。
插入数据
-- 插入数据
insert into word_avro
select name, id from user_info这里我们再查看表的数据文件,会发现数据的存储方式如下:

把文件拿到本地查看,如下:

在给表新增字段的时候,别忘了给新字段增加默认值,如果不写,查询的时候会报错如下:
优缺点
优点:后续数据的字段扩展不影响以前表的使用,或者后续表的修改不影响读取以前的数据。
缺点:数据里面存在冗余的数据,会使数据的文件变的很大。
应用场景:最原始的etl数据使用,因为最原始的数据经常变动结果。使用这种数据格式不受影响。
ORC表
定义
ORC File,它的全名是Optimized Row Columnar (ORC) file。(有索引有压缩的列式存储格式)据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、写以及处理数据的性能。 ORC File格式最主要的优点是在文件中存储了一些轻量级的索引数据。
之前提到的表都是行式存储,现在说的是列式存储。如果行式存储,我们在查询某个字段的时候,往往需要全表扫描,而列式存储就不需要了。
ORC File文件结构
ORC File包含一组组的行数据,称为stripes,除此之外,ORC File的file footer还包含一些额外的辅助信息。在ORC File文件的最后,有一个被称为postscript的区,它主要是用来存储压缩参数及压缩的大小。在默认情况下,一个stripe的大小为256MB(低版本250MB)。大尺寸的stripes使得从HDFS读数据更高效
+-----------------------------------------+
| File Header | <-- 文件头部,保存版本信息等基本数据
+-----------------------------------------+
| Stripe 1 |
| +-------------------------------+ |
| | Index Data | | <-- 每列的行索引信息(行偏移)
| +-------------------------------+ |
| | Row Data | | <-- 实际存储的数据(按列存储)
| +-------------------------------+ |
| | Stripe Footer | | <-- 当前 Stripe 的统计信息和偏移
| +-------------------------------+ |
| ... |
| Stripe N |
| +-------------------------------+ |
| | Index Data | |
| | Row Data | |
| | Stripe Footer | |
| +-------------------------------+ |
+-----------------------------------------+
| File Footer | <-- Stripe 的索引和统计汇总
+-----------------------------------------+
| PostScript | <-- 压缩信息和 Footer 的位置
+-----------------------------------------+
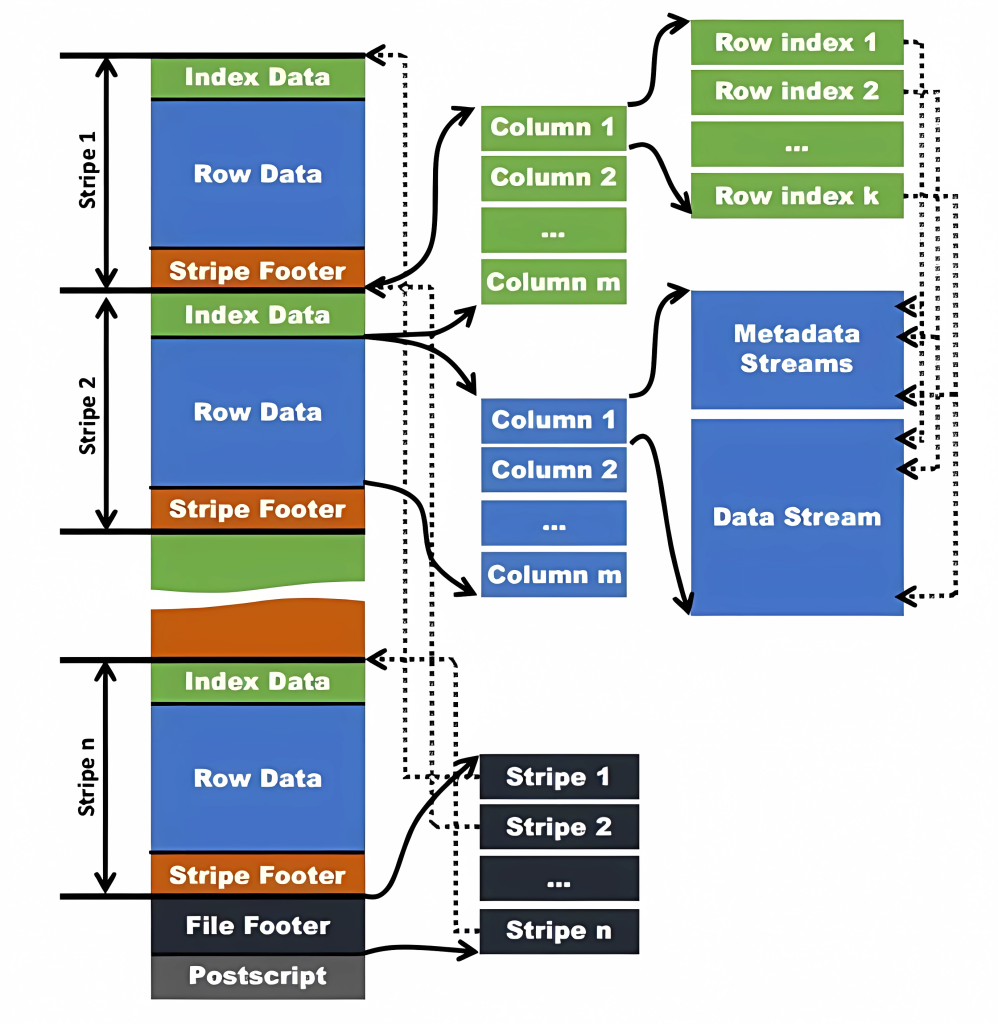
- 文件头(File Header)
- 文件头包含ORC文件的元数据,如ORC文件的版本信息、创建该文件的库和版本等。
- 它帮助读取器快速识别该文件是否是有效的ORC文件。
- Stripe
- ORC文件被分为多个Stripe。每个Stripe是文件中的数据块,包含一定数量的数据和元数据。一个Stripe通常包含多个行。
- Index Data:存储行索引信息,每列对应的索引信息,注意这里的索引是稀疏索引,不会对每个值创建索引,默认10000行创建一个。
- 存储行索引信息,每列对应的索引信息,包括:
- 每列的行索引(Row Index):包含行位置的偏移量。
- 用于快速跳过无关数据的索引。
- 存储行索引信息,每列对应的索引信息,包括:
- Row Data
- 实际存储的表数据,按列(Columnar Storage)存储。
- 每一列的数据是以 流的形式(Data Stream) 保存的。
- 支持多种压缩格式(如 Zlib、Snappy)。
- 实际存储的表数据,按列(Columnar Storage)存储。
- Stripe Footer:每个Stripe的结束部分存储了关于该Stripe的元数据,比如列的统计信息和索引。包括:
- 列的统计信息(如最大值 Max、最小值 Min、行数 Count、空值数量 Null Count)。
- 各列的编码信息,各列数据流的偏移量(位置指针),游程编码(行程编码)、字典编码、bit编码,用于定位 Row Data 的具体位置。
- 文件尾(File Footer)
- 文件尾包含ORC文件的元数据和索引信息。它的结构包括:
- 统计信息(Statistics):包括列的最小值、最大值、空值数等信息,用于帮助查询优化。
- 每个 Stripe 的位置信息(起始位置和长度)。
- 文件尾包含ORC文件的元数据和索引信息。它的结构包括:
- PostScript
- 描述文件压缩类型和压缩块的大小,版本信息。
- 指明 File Footer 的位置和长度,便于快速读取。
- Columnar Storage Format
- 数据在ORC文件中是按列而不是按行存储的。每列的数据被独立存储,这使得在查询时可以只读取需要的列,减少I/O开销。
- 数据被存储为 流(Stream) 的形式(如
Metadata Streams和Data Streams)。数据按列存储,查询时可以只读取需要的列,提高效率。
- Compression
- ORC文件采用压缩技术来减少存储空间,常见的压缩方法包括Zlib、Snappy等。
- 每个Stripe中的数据通常会独立压缩,这有助于提高读取效率并减少解压缩的开销。
Hive读取数据的时候,根据FileFooter读出Stripe的信息,根据IndexData读出数据的偏移量从而读取出数据。
表创建
CREATE EXTERNAL TABLE lmktest.t_truckenter_orc(
id string,
numberplate string,
type int,
code string,
uptime bigint)
PARTITIONED BY (dt string)
STORED AS orc
LOCATION 'hdfs://ns1/test/createtable/t_truckenter_orc'
TBLPROPERTIES ('orc.compress'='SNAPPY', 'orc.create.index'='true');给表导入数据,先创建分区并插入数据。
alter table t_truckenter_orc add if not exists partition (dt='20250101') location '20250101';
insert overwrite table lmktest.t_truckenter_orc partition(dt='20250101')
select
id,
numberplate,
type,
code,
uptime
from lmktest.t_truckenter_temp
where dt='20250101';查询
当我们使用select语句查询ORC表的时候,先去找PostScript的信息,然后到File Footer,再到Stripe Footer找到对应最大最小,再到Index Data,是从下往上找的。
因为ORC表自带索引,索引如果查询需要用到索引,速度就会比没有索引的表快。没有索引,需要执行mapreduce任务,找到这条数据,有索引就不需要可以直接扫描orc文件。但是如果全表扫描就不一定了。而且ORC表有压缩,占用的空间就小一些。
优点
- ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,文件中的数据尽可能的压缩以降低存储空间的消耗
- 以二进制方式存储,不可以直接读取
- 自解析,包含许多元数据,这些元数据都是同构ProtoBuffer进行序列化的
- 会尽可能合并多个离散的区间尽可能的减少I/O次数
- 在新版本的ORC中也加入了对Bloom Filter的支持,它可以进一 步提升谓词下推的效率,在Hive 1.2.0版本以后也加入了对此的支持。
Parquet表
Parquet 是面向分析型业务的列式存储格式,由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 的孵化器里毕业成为 Apache 顶级项目,支持大部分计算框架。
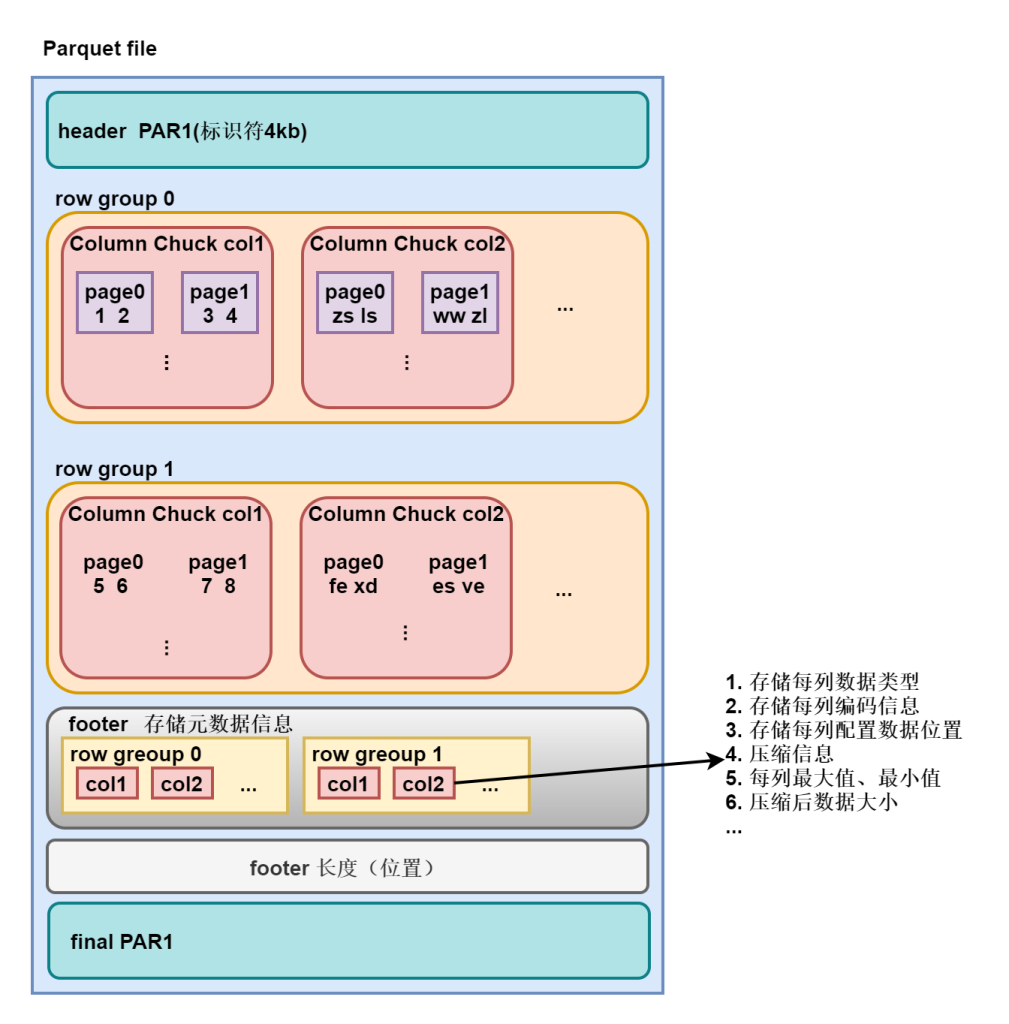
- Parquet文件由一个文件头(header)就是是该文件的Magic Code,用于校验它是否是一个Parquet文件。
- 一个或多个紧随其后的行组(Row Group)、Row Group由列块(Column Chuck)、页(Page)组成。
- 以及一个用于结尾的文件尾(footer)构成。
表创建
create table if not exists lmktest.user_parquet(id int, name string)
stored as parquet
tblproperties ("parquet.compress"="SNAPPY")插入数据
insert into lmktest.user_parquet
select * from user_info查询
当我们使用select * from table_parquet where id = 1查询的时候,首先会从footer长度位置,找到对应的footer。然后通过footer中的元数据信息,找到对应存储的数据。
优点
- Parquet支持嵌套的数据模型,类似于Protocol Buffers,每一个数据模型的schema包含多个字段,每一个字段有三个属性:重复次数、数据类型和字段名
- Parquet中没有Map、Array这样的复杂数据结构,但是可以通过repeated和group组合来实现
- 通过Striping/Assembly算法,parquet可以使用较少的存储空间表示复杂的嵌套格式,并且通常Repetition level和Definition level都是较小的整数值,可以通过RLE算法对其进行压缩,进一步降低存储空间
- Parquet文件以二进制方式存储,不可以直接读取和修改,Parquet文件是自解析的,文件中包括该文件的数据和元数据
hive可以用hdoop配置的压缩方式
之前在hadoop配置core-site.xml文件中有压缩方式,这些hive都可以使用
<property>
<name>io.compression.codecs</name> <value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
<description>相应编码的操作类</description>
</property>
配置压缩方式1
设置hive输出压缩
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;配置完成后,就算是默认textfile的表也会进行压缩。
配置压缩方式2
将文本文件,直接用gzip压缩,再上传到表的hdfs目录上。
hadoop fs -put user.gz /hive/warehouse/lmktest/demo_taselect语句创建表
与关系型数据库语法类似,可以使用create table tabname as select col from tablename2的语法创建一张表。语法如下:
create table table_name [stored as orc]
as
select ......注意只能这样创建内部表,不支持分区、分桶,查询一个分区表创建一张新表,新表也不会是分区表。
复制空表
方式1
只复制表结构,不复制表数据。这个操作在关系型数据库中经常使用,与上面的方式相同,只需要加个条件1=2(false)让查询没有数据就可以了,这是其中一个实现方式。但是同样,只能创建内部表。
方式2
使用like创建表,可以完全复制表结构,所以可以直接使用这种方式创建。语法如下:
CREATE TABLE tabname LIKE tablename;显示所有表的列表
显示所有表
SHOW TABLES;通用写法
在使用show查看表列表的时候,可以添加条件过滤信息。需要注意的是,这里通配符用的是*。
show tables like '*user*';删除表
使用drop删除表,与关系型数据库相同。语法如下:
DROP TABLE [IF EXISTS] table_name [PURGE]; - 对于内部表来说,删除表的操作的本质是删除表的元数据,然后hadoop fs -rm(将表数据挪到回收站目录, .Trash/Current)。
- 如果增加PURGE则不进回收站数据直接删除,不能恢复;
- 对外部表而言只删除元数据, 不删除数据目录,加PURGE也不删。
例如:
-- 删除表
drop table inner_test1;
-- 不进回收站数据直接删除表
drop table book purge;截断表(内部表)
截断表使用truncate与关系型数据库相同,语法如下:
TRUNCATE TABLE table_name [PARTITION partition_spec];- 可以删除表和删除分区数据,和drop的区别是不删除元数据(表结构),只删除数据,外部表是不能truncate操作的。
- 外部表不支持使用TRUNCATE语句。
使用partition 关键字可以清空表某个分区内的数据。
truncate table book partition(country='jp')修改表操作
| 操作 | 内部表 | 外部表 |
|---|---|---|
| 修改表名 | 元数据和hdfs目录均修改 | 只修改元数据,hdfs目录不修改 |
| 增加表分区 | 自动创建hdfs目录 | 自动创建hdfs目录 |
| 删除表分区 | 元数据和hdfs目录均删除 | 只删除元数据,hdfs目录不删除 |
| 修改分区路径 | 元数据修改,但目标分区路径的hdfs目录没有创建 | 元数据修改,但目标分区路径的hdfs目录没有创建 |
| 表分区重命名 | 元数据和hdfs目录均修改 | 只修改元数据,hdfs目录不修改 |
修改表名
修改表名的语法如下:
ALTER TABLE table_name RENAME TO new_table_name;内外部表区别:
- 内部表修改了表名之后,表对应的存储文件地址也跟着改,相当于作了HDFS的目录重命名。
- 外部表不会改对应的location地址。
增加表分区
可以使用alter … add partition() …增加表分区,语法如下:
alter table ext_task add IF NOT EXISTS partition(taskname='wordcount') location 'wordcount';内外部表区别:
- 内部表增加表分区,自动创建目录。
- 外部表增加表分区,自动创建目录。
查看分区目录语句:
-- 查询具体表的分区目录
select t1.`NAME`, t2.TBL_NAME,t4.PART_NAME, t3.LOCATION
from DBS t1, TBLS t2 , SDS t3 , `PARTITIONS` t4
where t1.DB_ID=t2.DB_ID and
t4.SD_ID = t3.SD_ID AND
t2.TBL_ID = t4.TBL_ID and
t1.`NAME` = 'lmk' AND
t2.TBL_NAME like '%task'
UNION
-- 查询具体表的目录
select t1.`NAME`, t2.TBL_NAME,'null', t3.LOCATION
from DBS t1, TBLS t2 , SDS t3
where t1.DB_ID=t2.DB_ID and
t2.SD_ID = t3.SD_ID AND
t1.`NAME` = 'lmk' AND
t2.TBL_NAME like '%task' ;删除表分区
可以使用alter … drop …删除分区表的分区,语法如下:
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec[, PARTITION partition_spec, ...];内外部表区别:
- 内部表删除分区,同时删除分区对应的目录。
- 外部表删除分区不删除分区对应的目录。
案例如下:
alter table inner_task DROP IF EXISTS partition(taskname='sortword');修改表或分区的路径
可以使用alter修改表或分区路径,语法格式:
ALTER TABLE table_name [PARTITION partition_spec] SET LOCATION "new location";内外部表区别:
- 内部表修改分区路径,元数据修改,但hdfs目录没有创建,等导入数据时创建,或者自己主动创建。
- 外部表修改分区路径,元数据修改,但hdfs目录没有创建,等导入数据时创建,或者自己主动创建。
案例:
alter table inner_task PARTITION (taskname='wordcount') set location "hdfs://ns1/hive/warehouse/lmktest/inner_task/wordcount1";无论是外部表还是内部表,修改分区路径,需要自己手动创建路径,或者等导入数据时创建。
分区重命名
可以使用alter … rename to …的方式分区重命名,语法格式如下
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;内外部表区别:
- 内部表,分区重命名,分区对应的地址也会跟着改变
- 外部表,分区重命名,分区对应的地址不变
案例:
alter table inner_task partition (taskname='maxword') rename to partition (taskname='maxword01');增加表字段
可以增加表字段、使用新列集合替换现有数据列,语法格式
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)ADD COLUMNS 可以在表列的最后和分区字段前面增加字段。
案例:
alter table ext_test add columns (test_col string);修改表字段
可以使用 alter… change …语法格式如下:
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name] 数据加载
insert (insert into)语句插入数据
insert语法插入数据的方式,这里就不多介绍了,不推荐使用,因为需要走mapreduce,比较慢。
当然也可以使用insert into 加select语句的方式。
文件put加载
使用数据文件put的方式写入数据,简单粗暴,之前也有用到。
load 加载数据
hive可以通过load加载数据,语法如下:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]load加载数据的时候存在两种情况,分别时 load linux本地数据和 load hdfs上的数据。
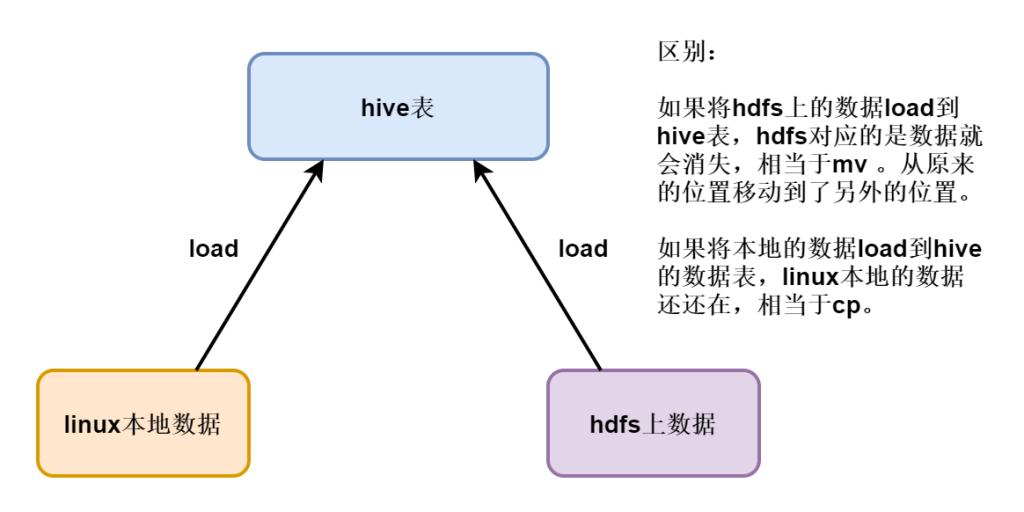
说明:
- hive 的数据加载不会对本地数据文件做任何处理,只是将文件或目录中的所有文件拷贝到表定义的数据目录,分桶表使用load加载数据(低版本没有)会生成mapreduce任务,将数据分到多个桶文件进行存放;
- 指定local本地文件上传,如果没有指定local,则是从hdfs上传数据;
- 文件加载hive没有做严格校验,文件格式和压缩选项等匹配需要用户自己保证;
- 分区表要指定具体加载数据分区,动态分区不支持;
- 如果指定OVERWRITE会覆盖相应表数据或分区数据,相当于 rm 原有目录数据,然后上传新数据文件。
[LOCAL] 含义,以覆盖或追加的方式 , 从linux本地 copy文件到表或表分区里。如果不加就是以覆盖或追加的方式 , 从hdfs move 文件到表或表分区里。
注意:从本地load数据到表的时候,如果用的是overwrite,会帮我们创建一个分区目录,并将数据上传到新创建的目录下,并且linux本地的数据不会消失。
案例:
1. 创建一个外部分区表
CREATE EXTERNAL TABLE `lmktest.ext_par_task1`(
`word` string,
`num` int)
PARTITIONED BY (
`taskname` string)
PARTITIONED BY (taskname STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/test/createtable/ext_par_task1';2. 给ext_par_task1表增加一个分区wordcount
alter table ext_par_task1 add if not exists partition (taskname='wordcount') location 'wordcount';也可以不创建,不创建分区,load会自动创建分区,名字就是默认的。
3. load导入本地数据
load data local inpath '/home/hadoop/test/createtable/word' into table ext_par_task1 partition(taskname = 'wordcount');4. select查看数据
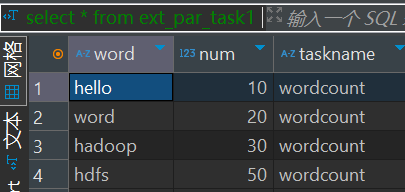
5. load导入hdfs数据
load data inpath '/test/word' into table ext_par_task1 partition(taskname = 'wordcount')因为是into,所以追加数据。
而且/test/word没有了,移动到了表分区/test/createtable/ext_par_task1/wordcount目录下。
案例2 覆盖导入
使用overwrite关键字,实现覆盖导入。
load data inpath '/test/word' overwrite into table ext_par_task1 partition(taskname = 'wordcount')这里/test/word文件直接移动到表分区/test/createtable/ext_par_task1/wordcount目录下,并且将原来的文件删除。
注意从本地导入数据有不同,本地导入数据后,会自动创建一个新分区目录,之前的分区目录就失效了。
所以我们上传数据的时候,尽量使用hdfs上传。
select 加载
以通过查询一张表的数据,将查询出来的数据导入另一张表。这个导入的方式之前经常使用,在日常操作关系型数据库的时候也有使用。语法如下:
--通过select,将select数据覆盖表或分区的语法格式
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]]
select_statement1 FROM from_statement;
--通过select,将select数据追加到表或分区的语法格式
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1 FROM from_statement;- 加了 IF NOT EXISTS,如果存在分区就跳过下面的select语句。
- INSERT OVERWRITE 会覆盖表或分区数据,但覆盖分区时增加IF NOT EXISTS,如果分区已经存在则不会覆盖。
- INSERT INTO 向表或分区追加数据,不影响历史数据。
案例1
1. 先给表ext_par_task1再添加一个分区
alter table ext_par_task1 add if not exists partition(taskname = 'wordcount2') location 'wordcount2'2. 使用select将数据导入分区
insert into ext_par_task1 partition(taskname = 'wordcount2')
select name, id from user_info ui insert 后面加上overwrite就是覆盖导入了。
导入数据动态分区
从一张不是分区表中查询数据导入到分区表中。如果分区的个数比较多的时候,就需要多次查询导入。
Hive默认是静态分区,我们在插入数据的时候要手动设置分区,如果源数据量很大的时候,那么针对一个分区就要写一个insert,比如说,有很多我们日志数据,我们要按日期作为分区字段,在插入数据的时候手动去添加分区,那样太麻烦。因此,Hive提供了动态分区,动态分区简化了我们插入数据时的繁琐操作。
如果历史数据导入,不适合静态分区,需要要用动态分区。
开启动态分区语法如下:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;案例1,表数据动态写入分区表
1. 先创建一张student表
CREATE TABLE student(
id int,
name string,
age int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';2. 使用load将准备的数据导入表中
load data local inpath '/home/hadoop/test/createtable/student' into table student 3. 准备一张分区表student_dyna
CREATE TABLE student_dyna(
id int,
name string)
partitioned by (age int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';4. 按照年龄分区,将student表中的数据导入分区表student_dyna
如果静态导入,那么有多少个分区就需要导多少次,非常麻烦。
--开启动态分区
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
-- 这里的table是不能省略的,必须写
insert overwrite table student_dyna partition (age)
select id, name, age from student;执行成功后,自动创建了分区如下:
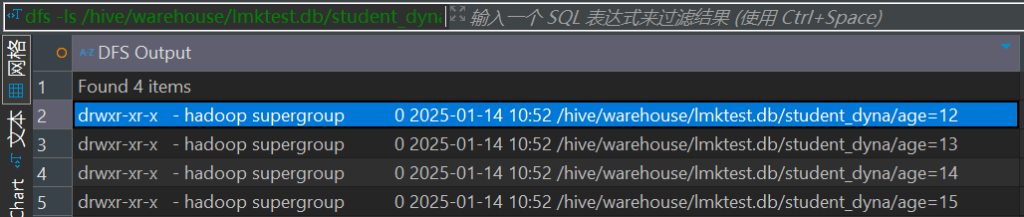
动态参数相关分区参数
--开启动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
------------------------------------------------------------------------
--表示每个节点生成动态分区的最大个数,默认是100
set hive.exec.max.dynamic.partitions.pernode=10000;
--表示一个DML操作可以创建的最大动态分区数,默认是1000
set hive.exec.max.dynamic.partitions=100000;
--表示一个DML操作可以创建的最大文件数,默认是100000
set hive.exec.max.created.files=150000hive数据导出
将hive表中的数据导出到本地或者hdfs。
语法:
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...导出单个文件
导出到本地案例
将select的数据写入到本地文件中,多层目录会自动创建。
insert overwrite local directory '/home/hadoop/test/output' row format delimited fields terminated by '\t' select * from ext_par_task1 ept where taskname='wordcount'案例2
将select的数据写入到本地文件中,文件存储格式为orc。
orc格式如果指定分隔符也无效。
insert overwrite local directory '/home/hadoop/test/output' stored as orc select * from ext_par_task1 where taskname='wordcount'导出多个文件
导出多个文件的语法有所不同,如下:
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 row_format
select_statement1 where
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 row_format
select_statement2 where 注意:
- 导出到文件系统的数据都序列化成text,非原始类型字段会序列化成json,导出文件以^A分隔 。
- INSERT OVERWRITE 到HDFS目录,可以通过MR job实现并行写入。这样在集群上抽取数据不仅速度快,而且还很方便。
- 批量导出多个文件,需要导出文件的类型一致,如果一个是avro,一个是text,报错。
案例
将ext_par_task1表中不同分区的数据分别导出到本地和hdfs。
from ext_par_task1
insert overwrite local directory '/home/hadoop/test/output' row format delimited fields terminated by '\t' select * where taskname='wordcount'
insert overwrite directory '/test/output' row format delimited fields terminated by '\t' select * where taskname='wordcount2'hive -e 执行命令导出
hive -e其实就是在命令行的方式启动hive,执行某段语句。
例如
hive -e "use lmktest;select * from ext_par_task1 where taskname='wordcount'"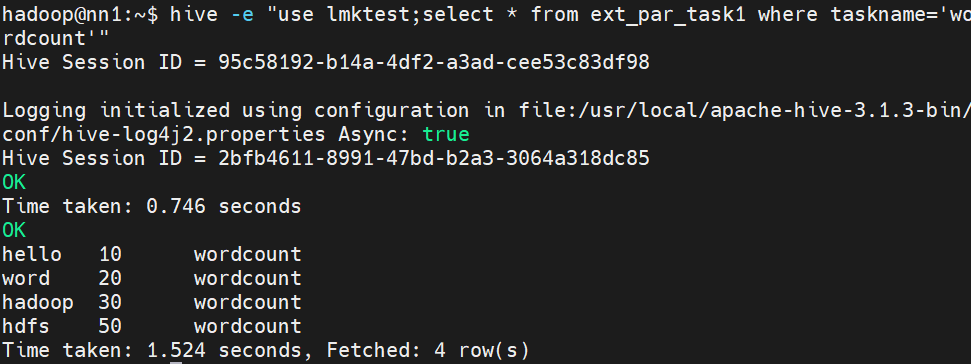
同样我们可以使用这个方式将数据导出到文件。
导出文件方式:
hive -e "use lmktest;select * from ext_par_task1 where taskname='wordcount'" > ext_par_task1.out后台运行导出文件方式:
nohup hive -e "use lmktest;select * from ext_par_task1 where taskname='wordcount'" 1>ext_par_task1.out 2>err.log &hive -f 执行命令导出
hive -f与hive -e类似。都是命令的方式执行sql语句。只不过f是读取文件中的sql语句,如果语句是多个,语句很长,是存储在文件中的,那么就可以使用hive -f filename.type执行文件中的语句。
hive优化
hive性能优化时,把HiveQL当做M/R程序来读,即从M/R的运行角度来考虑优化性能,从更底层思考如何优化运算性能,而不仅仅局限于逻辑代码的替换层面。
列裁剪
Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其它列。指定需要的列名,减少select * 。
分区裁剪
可以在查询的过程中减少不必要的分区,不用扫描全表。
合理设置reduce的数量
reduce个数的设定极大影响任务执行效率,在设置reduce个数的时候需要考虑这两个原则:使大数据量利用合适的reduce数;使每个reduce任务处理合适的数据量。
在不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下,两个设定:
-- 参数1:(每个reduce任务处理的数据量,在Hive 0.14.0及更高版本中默认为256M)
hive.exec.reducers.bytes.per.reducer
-- 参数2:(每个任务最大的reduce数,在Hive 0.14.0及更高版本中默认为1009)
hive.exec.reducers.max计算reducer数的公式: N = min( 参数2,总输入数据量 / 参数1 )
默认情况,执行6个reduce。例如我们的任务输入数据1g,那么N = min(1009, 1g/256m) = 4。
也可以设置每个reduce处理的数据量。
-- 设置为500M
set hive.exec.reducers.bytes.per.reducer=500000000;也可以通过直接通过参数来设置reduce个数。
-- (默认是-1,代表hive自动根据输入数据设置reduce个数)
mapred.reduce.tasks reduce个数并不是越多越好,启动和初始化reduce会消耗时间和资源;另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题。
job并行运行设置
带有子查询的hql,如果子查询间没有依赖关系,可以开启任务并行,设置任务并行最大线程数。
-- (默认是false, true:开启并行运行)
hive.exec.parallel
-- (最多可以并行执行多少个作业, 默认是 8)
hive.exec.parallel.thread.number小文件的问题优化
如果小文件多,在map输入时,一个小文件产生一个map任务,这样会产生多个map任务;启动和初始化多个map会消耗时间和资源,所以hive默认是将小文件合并成大文件。
-- 默认
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
-- 关闭小文件合并大文件
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;如果map输出的小文件过多,hive 默认是开启map 输出合并。(看情况合并,比如我们就想要一个记录对应一个结果的情况,那就不需要合并)
-- 控制map输出的小文件合并(默认是 false)
set hive.merge.mapfiles=true
-- 控制整个MapReduce任务输出的小文件进行合并(默认是 false)
set hive.merge.mapredfiles=true
-- 合并文件的大小,默认 256M
hive.merge.size.per.task
-- 所有文件的平均大小小于该值时,会启动一个MR任务执行merge,默认16M
hive.merge.smallfiles.avgsizejoin操作优化
多表join,如果join字段一样,只生成一个job 任务。
Join 的字段类型要一致。
--只产生一个job任务
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
select * from test_a a
inner join test_b b on a.id=b.id
inner join test_c c on a.id=c.id;
--产生多个job任务
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
select * from test_a a
inner join test_b b on a.id=b.id
inner join test_c c on a.name=c.name;MAP JOIN操作
如果你有一张表非常非常小,而另一张关联的表非常非常大的时候,你可以使用mapjoin此Join 操作在 Map 阶段完成,不再需要Reduce(hive默认开启mapjoin)。
配置方式如下:
-- 将小表刷入内存中,默认是true
set hive.auto.convert.join=true;
set hive.ignore.mapjoin.hint=true;
-- 刷入内存表的大小(字节),根据自己的数据集加大
set hive.mapjoin.smalltable.filesize=2500000; SMBJoin
SMB Join是 sort merge bucket操作,首先进行排序,继而合并,然后放到所对应的bucket中去,bucket是hive中和分区表类似的技术,就是按照key进行hash,相同的hash值都放到相同的bucket中去。在进行两个表联合的时候。我们首先进行分桶,在join会大幅度的对性能进行优化。
桶可以保证相同key 的数据都分在了一个桶里,这个时候我们关联的时候不需要去扫描整个表的数据,只需要扫描对应桶里的数据(因为key 相同的一定在一个桶里),smb的设计是为了解决大表和大表之间的join的,核心思想就是大表化成小表,然后map join 解决是典型的分而治之的思想。
SMB join 成立的前提条件
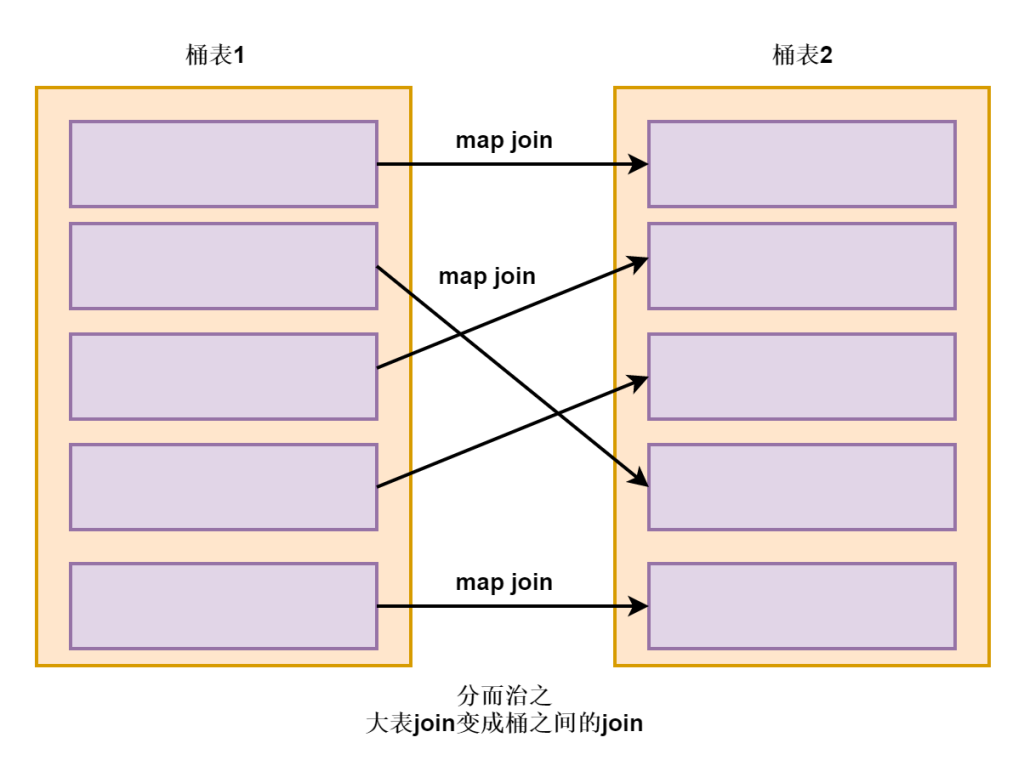
1.两张表是桶表,且分桶字段和桶内排序字段要一致,在创建表的时候需要指定:
CREATE TABLE(……) CLUSTERED BY (col_1) SORTED BY (col_1) INTO buckets_Nums BUCKETS2. 两张表分桶的字段必须是JOIN 的 KEY
3. 设置bucket 的相关参数,默认是 false,true 代表开启 smb join。
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;4. 两个join的桶表内桶数量可以相等,也可以是倍数关系。
hive数据倾斜的优化
对于mapreduce 计算框架,数据量大不是问题,数据倾斜是个问题。
数据倾斜的原因
- key分布不均匀,本质上就是业务数据有可能会存在倾斜
- 某些SQL语句本身就有数据倾斜
| 关键词 | 情形 | 后果 |
|---|---|---|
| Join | 其中一个表较小,但是key集中 | 分发到某一个或几个Reduce上的数据远高于平均值 |
| group by | group by 维度过小,某值的数量过多 | 处理某值的reduce非常耗时 |
数据倾斜的表现
- 任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
- 单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
通用解决方案——参数调节
对于group by 产生倾斜的问题,就与之前学mapreduce的map端combiner一样。
hive开启两个配置就可以了。
-- 默认是 true
set hive.map.aggr=true; 开启map端combiner,减少reduce 拉取的数据量。
-- 负载均衡,默认是 false
set hive.groupby.skewindata=true; 有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两个 MR Job。
第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;
第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
SQL 语句调节
大表Join小表(非法值过多)
关联字段重复值太多,或者非法数据太多,比如null,就会出现这种情况。
把空值的key变成一随机数(随机值类型需要跟key的类型一致),把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
注意:join的字段类型一定要一致,否则数据不会分到不同的reduce上。
解决案例:
SELECT * FROM test_a a
LEFT JOIN
test_b b
ON
CASE WHEN a.id IS NULL THEN ceil(RAND()*100) ELSE a.id END =b.id; 这里是有个风险的,需要保证random里的值,与b的id无重复值,否则就会出现匹配错误,导致有的数据错误。
count distinct 数据倾斜
在执行下面的SQL时,即使设置了reduce个数也没用,它会忽略设置的reduce个数,而强制使用1。这唯一的Reduce Task需要Shuffle大量的数据,并且进行排序聚合等处理,这使得它成为整个作业的IO和运算瓶颈。
set mapred.reduce.tasks=3;
select count (distinct country) from user_install_status_limit;优化方案:
设置多个reduce时,在reduce阶段可以多个reduce处理数据,而不是只有一个reduce处理数据。
方式1
-- 开启负载均衡,默认是 false
set hive.groupby.skewindata=true; 方式2 ,不使用count (distinct ),拆开
select count(*) from (select country from user_install_status_limit group by country)t;
或
select count(*) from (select distinct country from user_install_status_limit)t;order by
使用distribute by sort by 替代