
kafka原理安装及基础操作
kafka是什么
Kafka是由LinkedIn开发的一个分布式的消息队列。它是一款开源的、轻量级的、分布式、可分区和具有复制备份的(Replicated)、基于ZooKeeper的协调管理的分布式流平台的功能强大的消息系统。与传统的消息系统相比,KafKa能够很好的处理活跃的流数据,使得数据在各个子系统中高性能、低延迟地不停流转。
Kafka使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。
什么是消息队列
消息队列:是在消息的传输过程中保存消息的容器。
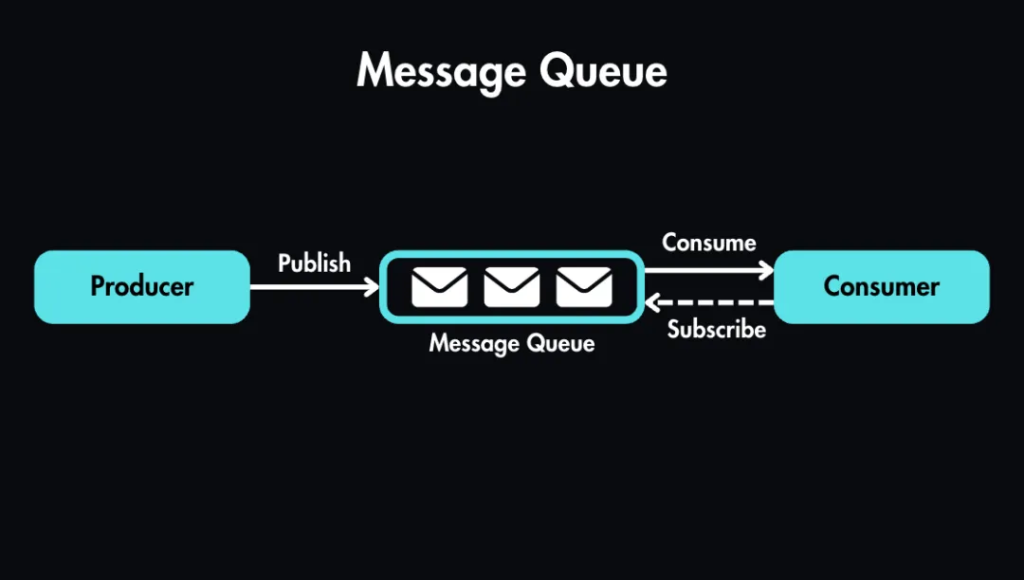
消息在原始的传输过程中是直接传输的,端对端的数据传递,但是有的时候我们需要将消息数据进行部分的缓冲存储,以达到方便使用的目的,中间的组件可以做消息的传输中间介质,这个组件就是消息队列。更像是一个消息的蓄水池一样的功能。
类比现实中更像是高速公路的休息区。
消息队列的好处
解耦
使用消息队列还可以降低系统耦合性。如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
生产者(客户端)发送消息到消息队列中去,消费者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
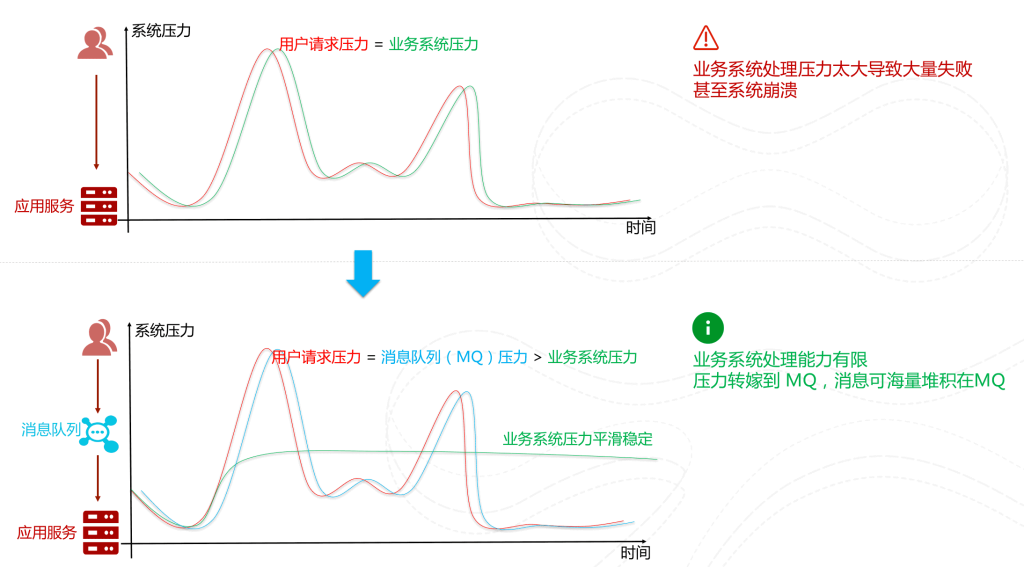
缓存消峰
先将短时间高并发产生的事务消息存储在消息队列中,然后后端服务再慢慢根据自己的能力去消费这些消息,这样就避免直接把后端服务打垮掉。
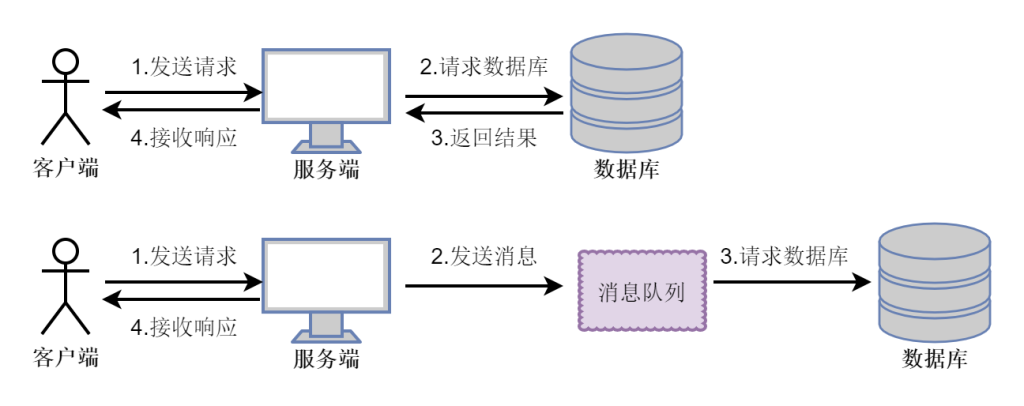
异步处理
将用户请求中包含的耗时操作,通过消息队列实现异步处理,将对应的消息发送到消息队列之后就立即返回结果,减少响应时间,提高用户体验。随后,系统再对消息进行消费。
例子:菜鸟驿站,快递员将快递放到驿站,客户直接从驿站获取快递。
消息消费模式
通过以上的讲解,我们可以了解整个kafka的原理和架构了,消息队列其实就是一个数据传输过程中的缓冲区,能够存储数据,在流程中作为一个中间的介质,承上启下,在特定的情景下起到解耦,缓冲,异步的功能。
作为中间的介质,它的上下游需要传输和拉取数据,上游传输数据的部分称之为生产者,生产数据发送到kafka中,下游拉取数据的组件称之为消费者,自己拉取想要的数据并且进行数据的计算和处理,消费者和消费者以及kafka是三个部分,大家一定要注意,他们不是一个整体
点对点消费
点对点的方式,在队列中的数据有且只有一个消费者可以消费数据,在消费完毕数据以后会将数据从队列中删除,这个数据有且只有一次消费
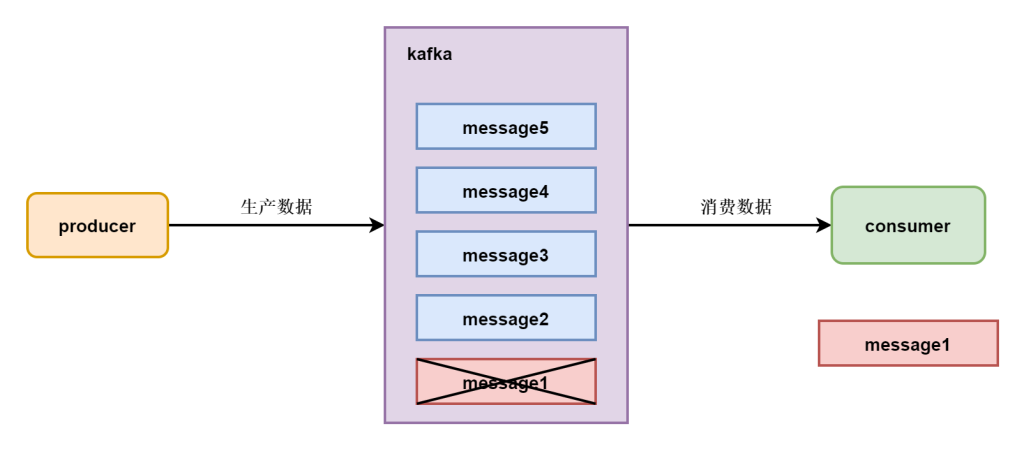
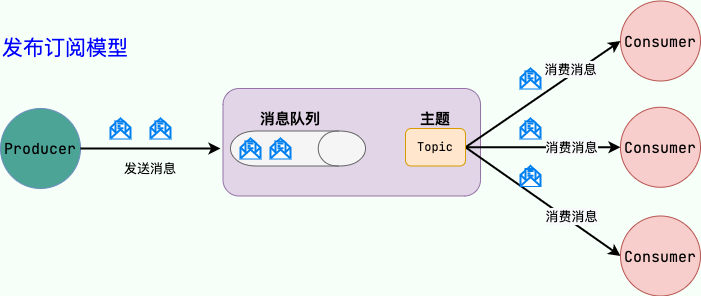
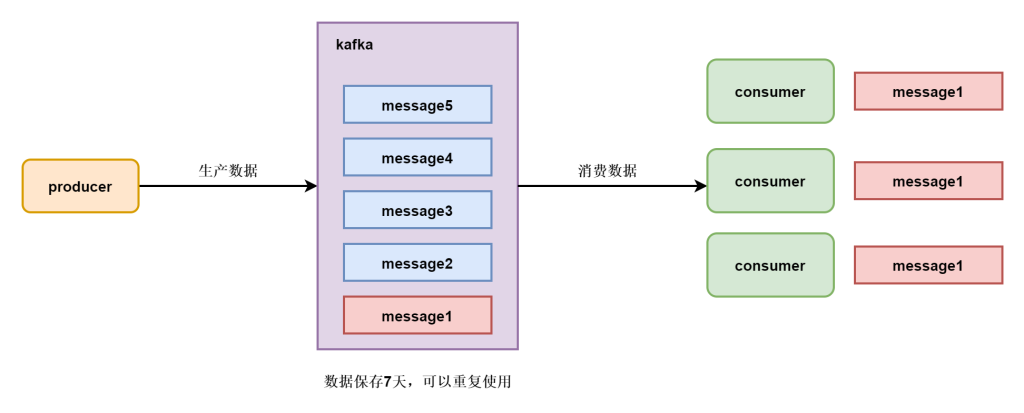
发布订阅模式
发布定语模式中每个人可以消费数据,这个数据会在队列中存储七天,每个订阅这个数据的人都可以消费到相应的数据,并且可以重复的进行消费数据,在大多数情况下我们都使用发布订阅模式
kafka的基础架构
kafka作为消息队列,主要在大数据的处理和计算过程中起到承上启下的作用。作为中间的一个缓冲中间件,那么它首先就要具备数据的稳定性和可靠性,并且存储数据量和吞吐量以及数据的检索速度一定要有所保证,那么单台机器肯定是没有办法解决这个问题的。
首先要保证性能一定要多台机器,分布式计算和存储才能保证性能,其次就是数据一定要做副本备份才能在多台机器的集群中保证数据的稳定性。所以首先要给大家介绍的就是kafka的集群组成结构。
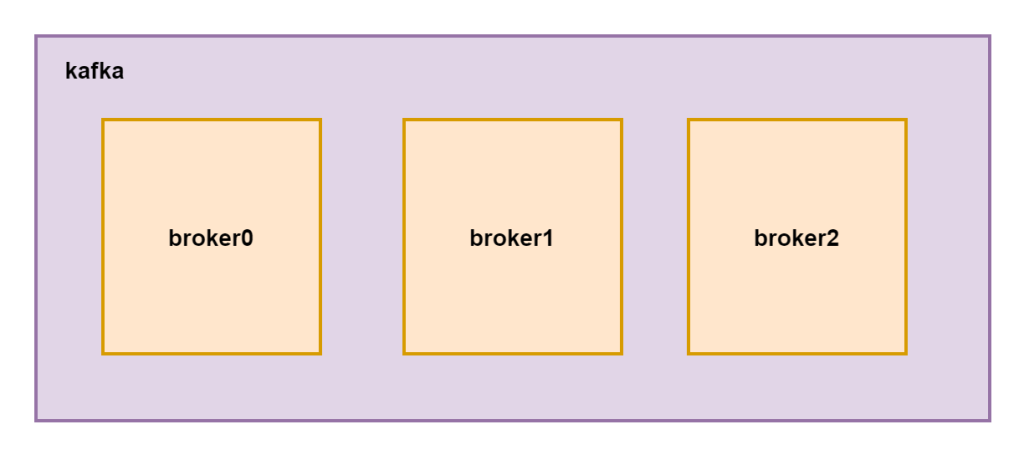
kafka首先我们要知道它不是一个主从集群,主从集群中节点有的天生就是主节点不能被其他的从节点替代。
在非主从集群中每个节点都可以作为主节点,如果一个节点宕机那么其他的节点可以选举为主节点管理整个集群,在kafka集群中每个节点都称之为broker。其中每个节点都存在一个kafka_controller组件,但是只有一台节点的controller组件是活跃状态的,其他的都是standby状态。
如果只有主节点宕机了,那么从节点才会选举成为主节点,但是究竟谁是主节点呢?这个时候我们需要一个外部协调管理组件zookeeper进行集群选举。在zookeeper中有一个独享锁,在文件夹中,谁先注册,将自己的ip放到里面,获得锁,谁就是active。
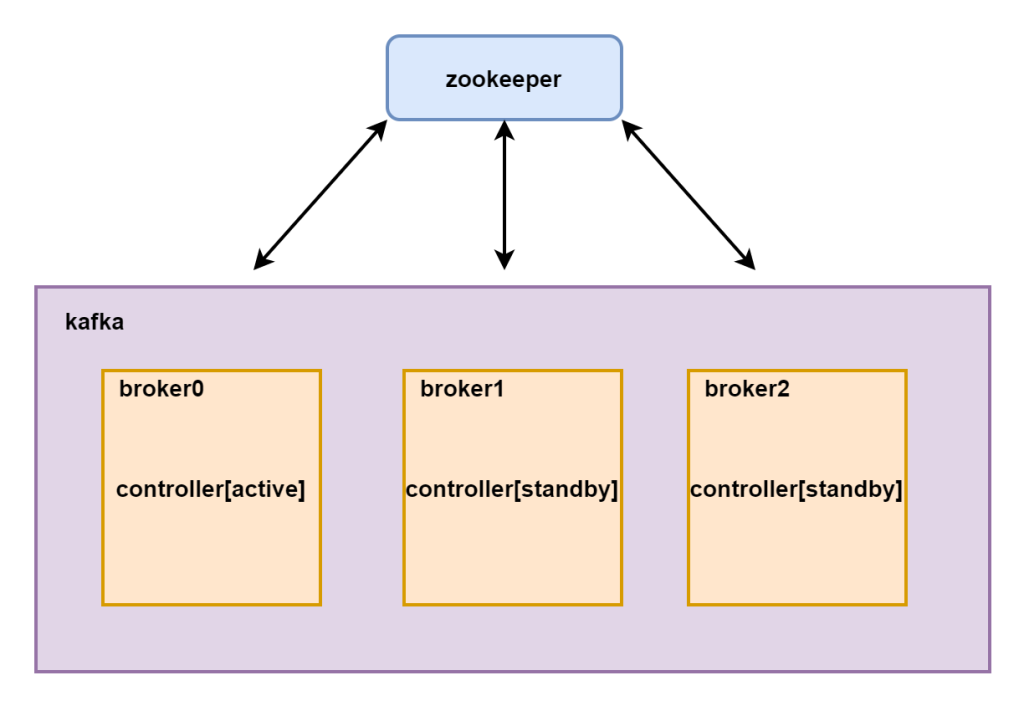
kafka的组件结构
broker
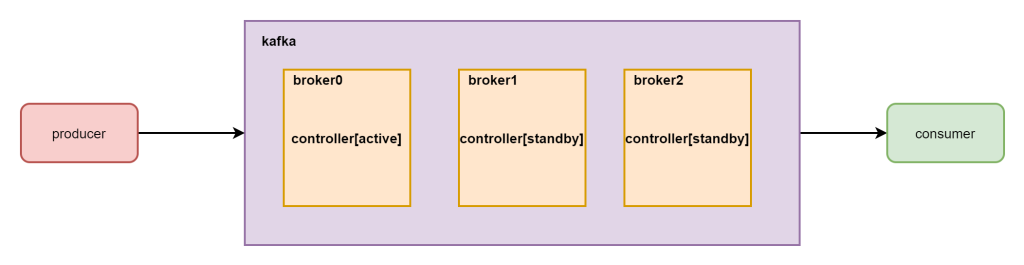
broker:每个kafka的机器节点都会运行一个进程,这个进程叫做broker,负责管理自身的topic和partition,以及数据的存储和处理。
因为kafka是集群形式的,所以一个集群中会存在多个broker。
但是kafka的整体又不是一个主从集群,需要选举出来一个broker节点为主节点,管理整个集群中所有的数据和操作以及所有节点的协同工作,每个broker上面都存在一个controller组件,这个组件就是主节点管理组件,负责整个集群的管理。但是只有一个机器是active状态的,这个需要zookeeper进行协调和选举。
topic
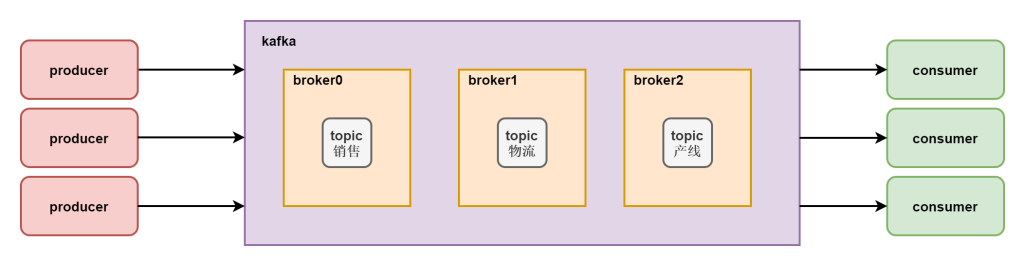
在kafka中存在一个非常重要的逻辑结构叫做topic,可以称之为主题。
当我们很多业务需要使用kafka进行消息队列的消息缓存和处理的时候我们会将消息进行分类处理,不能让多种类的数据放入到一起,这样使用特别混乱。
所以按照topic主题进行分类,是kafka数据处理的一大特色,可以类比现实中的主播。一个主播在直播的时候都会创建一个自己的房间,每个主播都不会相互干扰,各自主播自己的内容。
partition
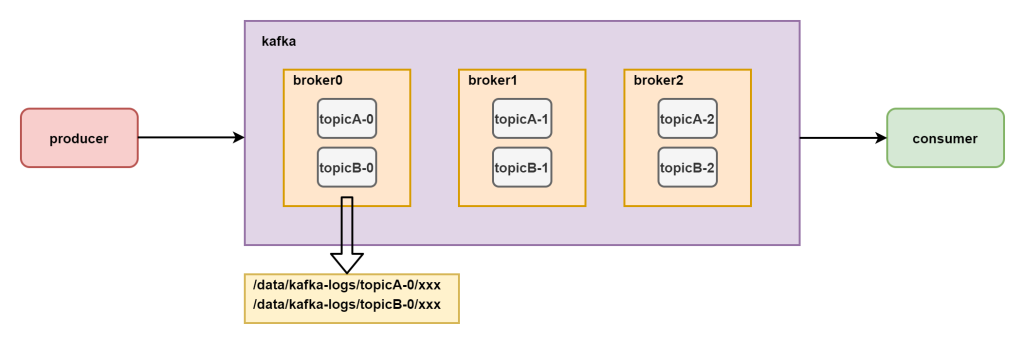
分区,每个topic中在使用过程中会存储很多数据,这些数据如果默认只给一个broker进行处理,那么这个broker的压力会太大,集群应该负载均衡让数据的压力在不同的机器上共同分摊,所以每个topic都会分为不同的分区,一个分区是一个topic数据真正的物理存储方式,让数据分为不同的部分,在多个节点上存储和管理。
分区是kafka物理存储最小的负载均衡单位,生产者生产数据的时候指向多个分区,消费者也可以在消费数据的时候从不同的分区读取数据。
每个broker节点会按照topic的名称和分区的名称组合在一起形成一个文件夹进行文件内容的存储,一个broker会管理多个topic的不同分区的数据
备份
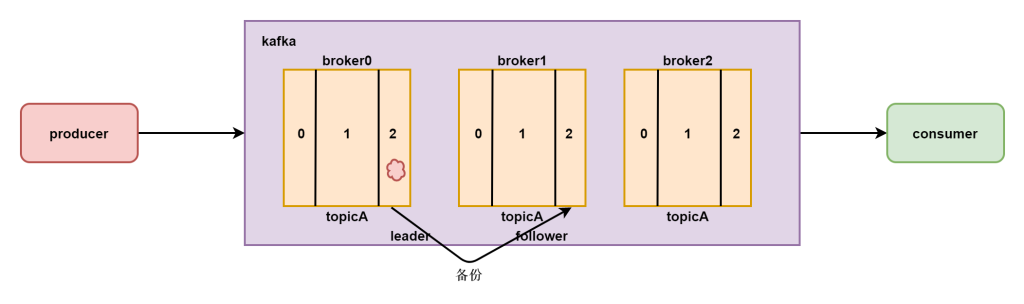
在一个topic中存在多个分区,每个分区存储一部分这个topic的数据,但是因为存在多个机器上,不能够保证数据的稳定性,所以数据需要进行备份管理,所以分区是存在备份的,比如topicA的数据就需要存储多份在不同的机器上,这样数据损坏一份,其他的部分还可以使用。
主从
数据在存储的时候需要备份多个,那么这些数据就要保证数据的一致性,所以我们不能再存放数据的时候随意的向任何副本写入。
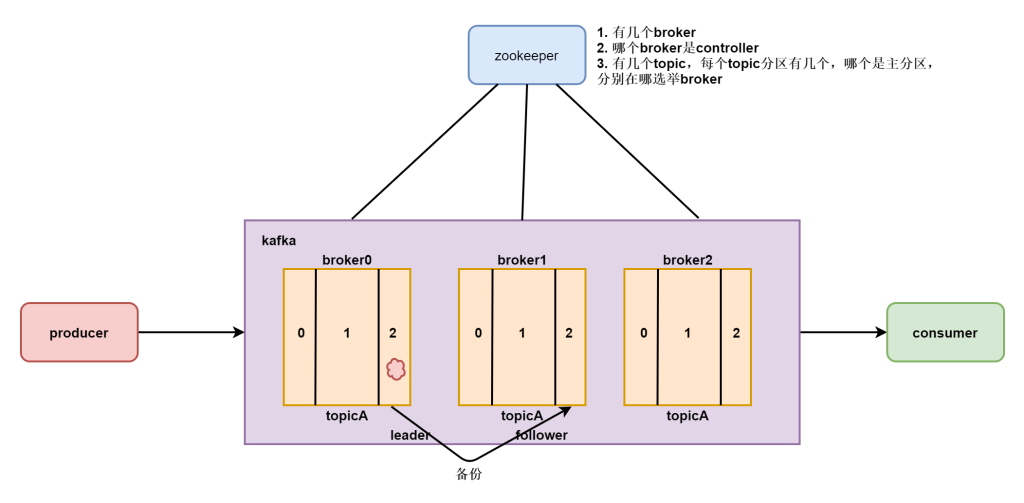
因为这样集群中一个分区的多个副本没有办法保证数据的一致性,所以我们只能写入数据到一个副本,这个副本叫做主副本,其他的副本会从主副本同步数据,从而保证数据的一致性。
这个主从的选举是broker的主节点进行选举的和zookeeper没有关系。
- zookeeper:帮助选举broker为主,记录哪个是主broker,集群存在几个topic,每个topic存在几个分区,分区存在几个副本,每个分区分别在哪个机器节点上
- producer: 生产者,将数据远程发送到kafka集群,一般都是flume进行数据采集,并且发送到集群,producer一般只能发送数据到一个topic中,和一个主播只能在自己的房间直播一样
- consumer:消费者,消费数据并且参加计算处理,一般都是spark,flink等计算框架充当。但是一个消费者可以同时消费多个分区的数据,就如一个观众可以一起看多个小姐姐直播一样
数据不管是生产者还是消费者,都是一条一条的操作,这个才是消息队列,这也是消息队列和hdfs等存储介质不同的地方,消息队列更加偏向于流式处理,并不是整体存取。
kafka配置
当前版本查看,已经不需要使用zookeeper了,可以使用KRaft (Kafka Raft) 模式。KRaft 模式将元数据管理从 Zookeeper 转移到了 Kafka 内部,由 Kafka 自己的 Controller 节点组成的 Raft 仲裁来负责。
现在我有6台机器,准备使用混合模式。
- 3 台 Controller-Eligible/Combined 节点 (nn1, nn2, nn3):它们将同时扮演 Kafka Broker 和 Kafka Controller 的角色,并构成 KRaft 的元数据仲裁。
- 3 台 Broker-Only 节点 (sl1, sl2, sl3):它们只扮演 Kafka Broker 的角色,负责存储和传输数据,并通过 Controller 仲裁获取元数据。
生成集群 ID
KRaft 集群需要一个唯一的集群 ID。这个 ID 在集群生命周期内是固定的。在任何一台机器上执行一次即可。
# 进入 Kafka 安装目录 (例如 /opt/kafka)
cd /opt/kafka
# 生成一个随机的集群 UUID
# 会在控制台输出一个 UUID,请务必复制下来,后面会用到
bin/kafka-storage.sh random-uuid我生成的uuid为Kio-9QPYTCyWWmKcNsmNCQ
这里在执行命令的时候报错java.lang.NoSuchMethodError,因为Hadoop 和 Kafka 的依赖库发生冲突。这里我将环境变量中的HADOOP_HOME相关注释掉就可以了。
server.properties
Controller-Eligible/Combined 节点 (nn1, nn2, nn3)
# Basic settings
process.roles=broker,controller
node.id=2
# Listener for clients (broker) and internal controller communication
listeners=PLAINTEXT://nn2:9092,CONTROLLER://nn2:9093
advertised.listeners=PLAINTEXT://nn2:9092,CONTROLLER://nn2:9093
# Controller quorum bootstrap servers (list all 3 controller-eligible nodes)
controller.quorum.bootstrap.servers=nn1:9093,nn2:9093,nn3:9093
# Specify the controller listener name
controller.listener.names=CONTROLLER
# Log directories (broker data and controller metadata will be stored here)
log.dirs=/opt/kafka/data/kraft-combined-logs # 确保这个目录存在且有写入权限
# Internal Topic settings
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2Broker-Only 节点 (sl1, sl2, sl3)
# Basic settings
process.roles=broker
node.id=5
# Listener for clients (broker)
listeners=PLAINTEXT://sl2:9092
advertised.listeners=PLAINTEXT://sl2:9092
# Controller quorum bootstrap servers (list all 3 controller-eligible nodes)
controller.quorum.bootstrap.servers=nn1:9093,nn2:9093,nn3:9093
# Log directories (broker data will be stored here)
log.dirs=/opt/kafka/data/kraft-broker-logs # 确保这个目录存在且有写入权限
# Internal Topic settings
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2创建数据目录 (所有机器)
mkdir /data/kraft-logs格式化存储 (所有机器,首次启动前执行一次)
这里需要使用之前生成的CLUSTER_ID
cd /usr/local/kafka
bin/kafka-storage.sh format -t Kio-9QPYTCyWWmKcNsmNCQ -c config/server.properties启动 Kafka 服务器 (所有机器)
bin/kafka-server-start.sh config/server.properties
# 后台执行
nohup bin/kafka-server-start.sh config/server.properties > /opt/kafka/logs/server.log 2>&1 &docker快速搭建
使用docker compose搭建
version: '3.6'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest # Zookeeper 通常向下兼容,保持最新问题不大
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
networks:
- kafka-net
kafka:
image: confluentinc/cp-kafka:7.5.0 # <--- 将此处替换为明确支持 Zookeeper 的旧版本
# 或者尝试 confluentinc/cp-kafka:7.4.0
hostname: kafka
container_name: kafka
ports:
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
# KAFKA_PROCESS_ROLES: broker # <--- 移除此行,旧版本通常不需要
networks:
- kafka-net
networks:
kafka-net:
driver: bridge启动命令
docker-compose up -d