
Spark的背景、生态、安装
MapReduce存在局限性,如下:
- 仅支持Map 和Reduce两种操作;
- MapReduce多个任务的中间结果落地磁盘,不能充分利用内存,任务运行效率低;
- 适合批处理,不适合实时性要求高的场景;
- 程序编写过于复杂;
- 资源不能复用,每次需要重新发分配资源。
Hadoop:可以用普通硬件搭建Hadoop集群,用于解决存储和计算问题;
- 解决存储:HDFS
- 解决计算:MapReduce
- 资源管理:YARN
Spark:Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷;
Spark不能代替Hadoop,但可能代替MapReduce。
什么是Spark
Spark,是一种通用的大数据计算框架,正如传统大数据技术Hadoop的MapReduce、Hive引擎,以及flink流式实时计算引擎等。
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架,用于构建大型的、低延迟的数据分析应用程序。
Spark使用强大的Scala语言开发,它还提供了对Scala、Python、Java(支持Java 8)和R语言的支持。
Apache顶级项目,项目主页:http://spark.apache.org
为什么要用Spark
- 运行速度快
- 使用DAG(全称Directed Acyclic Graph, 中文为:有向无环图)执行引擎以支持循环数据流与内存计算(当然也有部分计算基于盘,比如shuffle);
- 易用性好
- 支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程 ;
- 通用性强
- Spark提供了完整而强大的工具,包括SQL查询、流式计算、机器学习和图算法组件;
- 随处运行
- 可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源;
Spark 对比MapReduce
- spark可以把多次使用的数据放到内存中;
- spark可以使用的算法多,方便处理数据;
- spark大部分算子没有shuffle阶段,不会频繁的落地磁盘,降低磁盘IO;同时这些算子可以不需要排序,省略排序步骤;
- 在代码编写方面,不需要写那么复杂的MapReduce逻辑。
缺点:过度依赖内存,内存不够用了就很难堪。
Spark生态
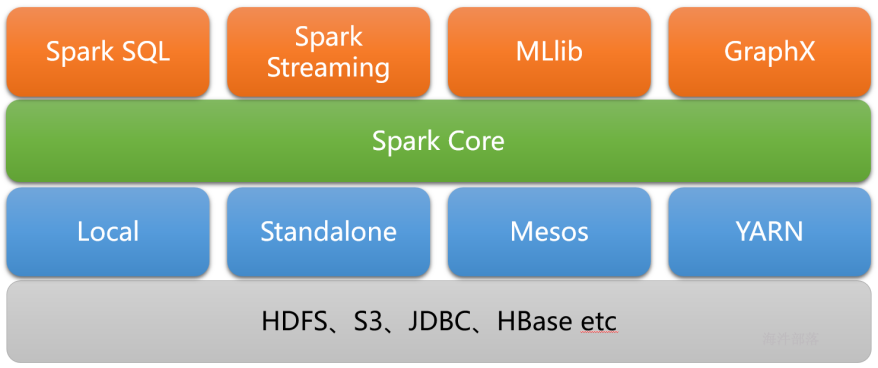
spark core实现了spark的基本功能、包括任务调度、内存管理、错误恢复与存储系统交互等模块。spark core中还包含了对弹性分布式数据集(resileent distributed dataset)的定义;
spark sql
是spark用来操作结构化数据的程序,通过SPARK SQL,我们可以使用SQL或者HIVE(HQL)来查询数据,支持多种数据源,比如HIVE表就是JSON等,除了提供SQL查询接口,还支持将SQL和传统的RDD结合,开发者可以在一个应用中同时使用SQL和编程的方式(API)进行数据的查询分析,SPARK SQL是在1.0中被引入的。
Spark Streaming
是Spark提供的对实时数据进行流式计算的组件,比如网页服务器日志,或者是消息队列都是数据流。
MLLib
是Spark中提供常见的机器学习功能的程序库,包括很多机器学习算法,比如分类、回归、聚类、协同过滤等。
GraphX
是用于图计算的比如社交网络的朋友关系图。
Spark安装、启动
首先解压压缩包tar -zxcf 文件 -C 指定路径。
spark 各个文件夹的内容
- bin 可执行脚本,偏使用;
- sbin 控制脚本,超级命令,集群的启动关闭,集群的管理等,偏管理;
- kubernetes 接入K8S使用;
- yarn yarn支持库,接入yarn使用;
- conf 配置文件目录;
- data 运行时的文件,examples里的测试样例的测试数据集;
- jars lib库,依赖包;
- examples 测试样例;
- python 接入python使用;
- R 接入R使用。
配置文件
准备文件,先来到conf目录下
mv spark-env.sh.template spark-env.sh
mv workers.template workers打开spark-env.sh进行配置
-- 这个JAVA_HOME是不需要配置的,但是我启动workers的时候报错,找不到JAVA_HOME,没找到问题,其他节点正常,也是可以使用java的。实在没办法,直接将JAVA_HOME写在这里了。
export JAVA_HOME=/usr/local/jdk1.8.0_411
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop还有一些其他的配置,也可以设置,在注释中都有,包括works的内存,核数等等。默认值是所有核和总内存-1g。
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=1G打开works进行配置
sl1
sl2
sl3配置完成后分发到各个节点。
启动spark
这里需要注意,如果使用start-all.sh 会与Hadoop的冲突。所以使用下面的命令启动
start-master.sh
start-workers.sh运行的端口,可以通过查看log文件,或者命令查看进程,jps或者ps aux 都可以查看进程。
netstat -natpl | grep 35568http://nn1:8080/可以查看相应的监控页面。
测试spark
使用spark-submit命令提交任务,直接回车可以看到帮助提示,主要以下四种方式。
- Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
- Usage: spark-submit –kill [submission ID] –master [spark://…]
- Usage: spark-submit –status [submission ID] –master [spark://…]
- Usage: spark-submit run-example [options] example-class [example args]
命令组成结构spark-submit [选项] jar包 参数
我们首先搭建的是standalone模式,所以关键参数如下:
--master MASTER_URL #集群地址
--class class_name #jar包中的类
--executor-memory MEM #executor的内存
--executor-cores NUM # executor的核数
--total-executor-cores NUM # 总核数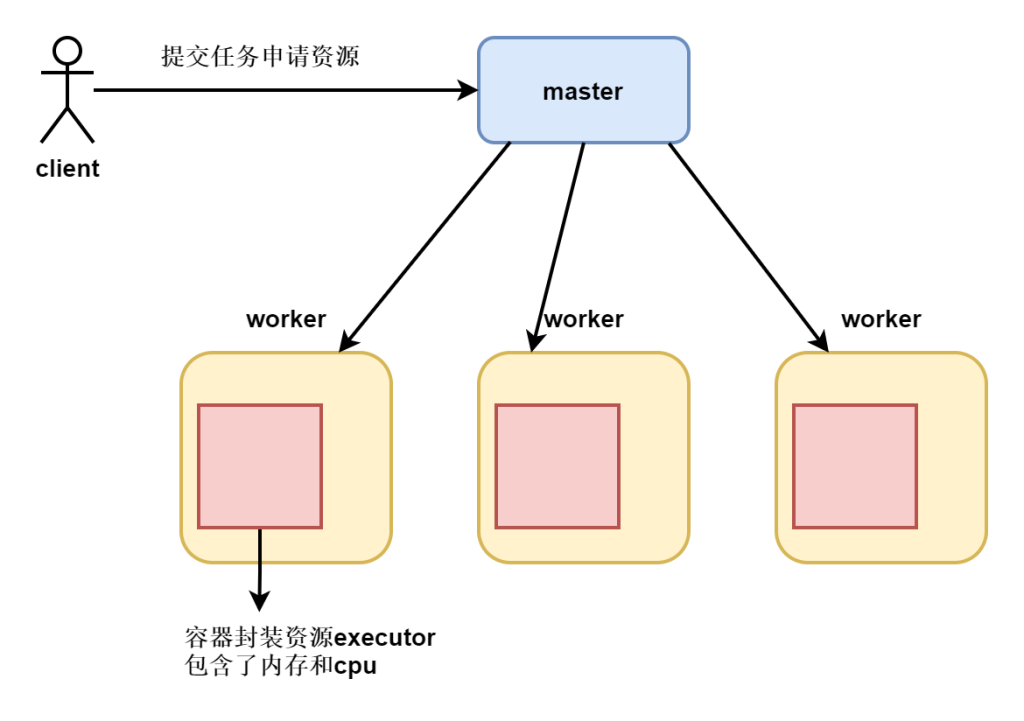
执行语句如下:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://nn1:7077 \
--executor-memory 1G \
--total-executor-cores 6 \
--class org.apache.spark.examples.SparkPi \
/usr/local/spark/examples/jars/spark-examples_2.12-3.5.5.jar \
1000executor资源的默认值是memory 1g。yarn模式下默认1core,其他是所有core。
配置历史服务
1.首先修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf2. 然后修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://ns1/directory注意:需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
sbin/start-dfs.sh
hadoop fs -mkdir /directory3. 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://ns1/directory
-Dspark.history.retainedApplications=30"参数含义如下:
- 参数 1 含义:WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
高可用配置(HA)
修改spark-env.sh
配置以下内容,并分发到各个节点,这里注意需要改一下WEB UI的监听端口,不然与zookeeper的冲突了。
-- 修改节点,因为会与zk的端口冲突
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=nn1:2181,nn2:2181,nn3:2181 -Dspark.deploy.zookeeper.dir=/spark3"注意,这里我因为端口冲突问题,修改了不少配置,最后才测试出是端口问题,解决端口冲突后,发现无法选举出ALIVE的节点。
解决方式为,进入zk,使用deleteall删除/spark3。并重新启动spark。
高可用启动
首先启动zookeeper
然后启动spark
-- nn1 操作
start-master.sh
start-workers.sh
-- nn2 操作
start-master.sh
-- nn3 操作
start-master.sh高可用演示
spark-submit --master spark://nn1:7077,nn2:7077,nn3:7077 \
--executor-cores 2 \
--executor-memory 1G \
--total-executor-cores 6 \
--class org.apache.spark.examples.SparkPi \
/usr/local/spark/examples/jars/spark-examples_2.12-3.5.5.jar \
10000高可用原理
在应用程序执行过程中,如果进行master 的ha切换不会影响应用程序的运行,因为程序运行前已经向master申请过资源了。申请过后就是Driver与Executors之间的通信,这个过程一般不需要Master参与,除非executor有故障。
粗粒度:应用程序需要多少资源,就一次性分配。
好处:是一次性分配资源好后,不需要再关心资源的分配,而在作业运行过程中可以让driver和executors交互,完成作业或程序运行。
弊端:假设有一百万个任务,如果只有一个任务没有完成,那么其他所有资源都会闲置,其他任务会等待,造成浪费。
Spark组成及大概流程
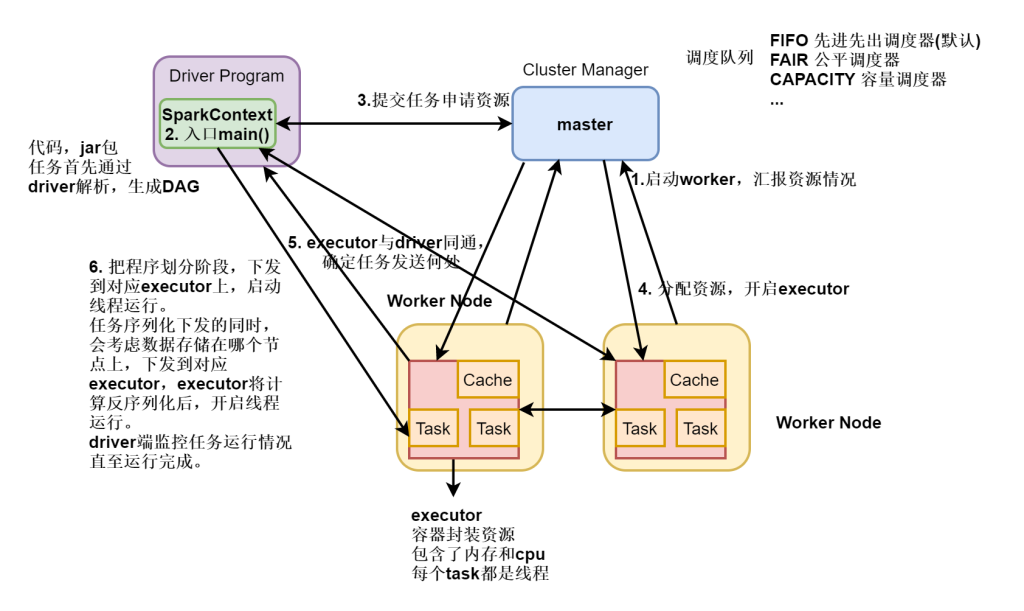
Driver: 运行 Application 的 main() 函数的节点,提交任务,并下发计算任务;
Cluster Manager:在standalone模式中即为Master主节点,负责整个集群节点管理以及资源调度;在YARN模式中为资源管理器;
Worker节点:上报自己节点的资源情况,启动 和 管理 Executor;
Executor:执行器,是为某个Application运行在worker节点上的一个进程;负责执行task任务(线程);
Task:被送到某个Executor上的工作单元,跟MR中的MapTask和ReduceTask概念一样,是运行Application的基本单位。
driver和exector都是一次性的,每个任务都会有自己的一组。
运行大概流程:
- driver 端提交应用,并向master申请资源;
- Master节点通过RPC和Worker节点通信,根据资源情况在相应的worker节点启动Executor 进程;并将资源参数和Driver端的位置传递过来;
- 启动的Executor 进程 会主动与 Driver端通信,Driver 端根据代码的执行情况,产生多个task,发送给Executor;
- Executor 启动 task 做真正的计算,每个Task 得到资源参数后,对相应的输入分片数据执行计算逻辑;
spark shell
是基础scala的的命令行客户端,是一个spark的driver应用程序,可以写spark程序进行测试,可以本地运行也可以集群运行,取决于是否设置 –master
spark-shell是交互式命令行,出发点是在客户端,主要是为了编程测试使用的。与spark-submit不同,提交的是一个整体的代码,打包成jar。
spark-shell是写一行命令执行一行。
命令模板如下:
spark-shell --master spark://nn1:7077 \
--executor-cores 2 \
--executor-memory 2G \
--total-executor-cores 6执行后进入driver端,生成一个没有执行任务的application。
提交模式
集群存在
- local模式,直接使用机器本地的资源。本地运行与集群无关。
- standalone集群,独立部署模式
local模式
// local 本地执行使用一个核
// local[3] 本地三个核相当于是一个伪集群
// local[*] 本地所有的核
spark-shell|spark-submit --master local | local[N] | local[*]本地执行不会用到集群的任何资源,是本地多线程模拟,启动后进入WEB UI什么也看不到。
standalone模式
spark-shell|spark-submit --master spark://集群资源设定提交
spark集群在standalone模式中默认存在一个问题,一旦设定好了每个executor的资源大小,它会按照整个集群的资源全部都给executor进行分配。
比如我们只设定executor的资源
spark-submit --executor-cores 2 --executor-memory 1G整个集群的资源每个机器是3G+3cores,每个worker = 2G + 3cores。
在分配资源的时候会,按照木桶原理,默认会总共启动3个executor,每个机器一个,尽量占用所有的资源。这样多个任务就不能并行执行,设定资源提交
// 多个任务并行执行
spark-shell --master spark://nn1:7077 --executor-cores 1 --executor-memory 1G \
--total-executor-cores 3
spark-shell --master spark://nn1:7077 --executor-cores 1 --executor-memory 1G \
--total-executor-cores 3就拿当前集群来说,集群中的资源 3*worker = 3cores + 2G =[9cores + 6G],可以设置的配置如下表:
| –executor-cores | –executor-memory | –total-executor-cores | num |
|---|---|---|---|
| / | / | / | 3 |
| / | 512M | / | 3 |
| 1 | 1G | / | 6 |
| 1 | 1G | 3 | 3 |
| 1 | 1G | 2 | 2 |
| 4 | 1G | / | 0 |
Yarn模式
Yarn和Spark的StandAlone调度模式对比
| yarn | standAlone调度模式 | spark集群各组件的功能 |
|---|---|---|
| ResourceManager | Master | 管理子节点,调度资源,接受任务请求 |
| NodeManger | Worker | 管理当前节点,并管理子节点 |
| YarnChild | Executor (Task) | 运行真正的计算逻辑(Task) |
| client | client | driver(Client+AppMaster)提交App,管理该任务的Executor |
| ApplicationMaster | driver |
yarn模式下spark的executor在container里面,driver可能在client端,也可能在appMaster上。
yarn的提交命令
# yarn的提交命令参数
--master yarn #执行集群
--deploy-mode # 部署模式
--class #指定运行的类
--executor-memory #指定executor的内存
--executor-cores # 指定核数
--num-executors # 直接指定executor的数量
--queue # 指定队列为了提交任务首先修改yarn的配置文件
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1536</value>
<description>单个任务可申请的最多物理内存量</description>
</property>
# 分发配置文件
scp_all.sh /usr/local/hadoop/etc/hadoop/yarn-site.xml /usr/local/hadoop/etc/hadoop/yarn-client模式
是driver端是独立于 yarn集群的,运算的时候,driver端需要管理executor 中task的运行,所以driver端(客户端)是不能离开的,关掉客户端就挂了。
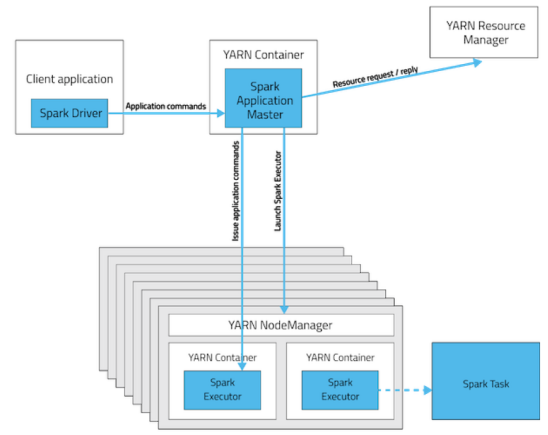
spark-shell只能是yarn-client模式。
driver端在客户端上,所以好调试日志。所以测试调试,执行小任务的时候比较方便,可以使用。
当在客户端提交多个spark应用时,它会对客户端造成很大的网络压力,yarn-client模式只适合 交互式环境开发。
spark-shell提交代码如下:
spark-shell --master yarn --deploy-mode client --queue root.hainiu --executor-cores 1 --executor-memory 1G执行后,可以进入WEB UI查看情况,点击application –> appMaster进入到监控页面。
客户端在nn1 driver也在nn1,appmaster也会占用资源在s1节点,s2和s3分别运行的是executor。
spark-submit提交代码如下:(不加–deploy-mode 默认就是client)
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--queue master \
/usr/local/spark/examples/jars/spark-examples_2.12-3.5.5.jar \
20000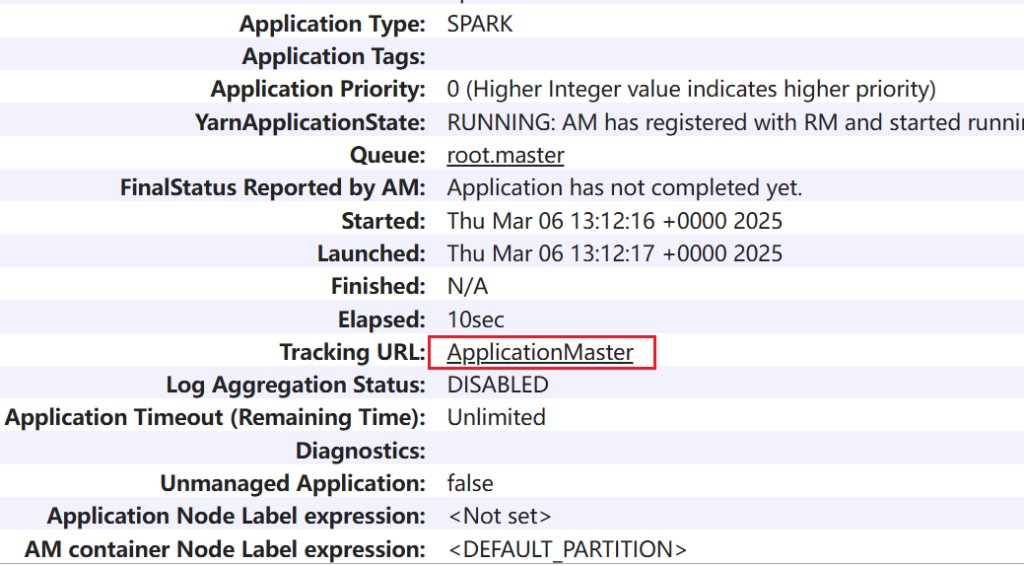
可以跳转到spark WEB UI查看executors,如下:
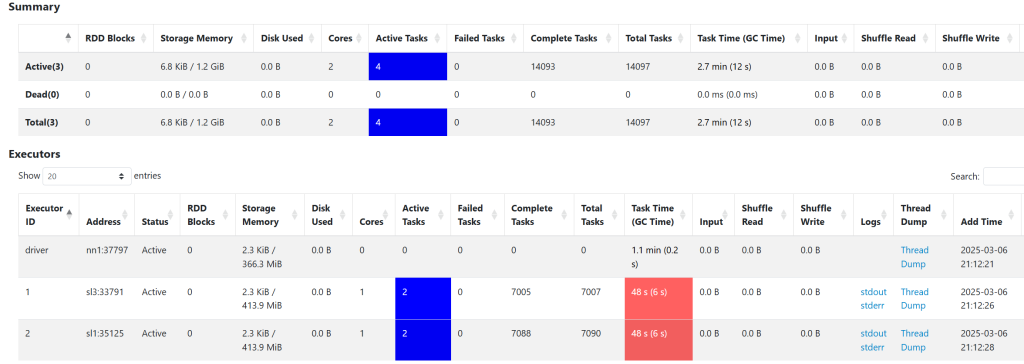
yarn模式中不设置资源也会存在默认值
- executor-memory =1G
- executor-cores = 1
- num-executors = 2
yarn-cluster模式
driver端是在APPMater节点,是在yarn集群里面,那运行和监控executor 的任务都是在yarn集群里面。yarn提交任务的客户端是可以离开的。
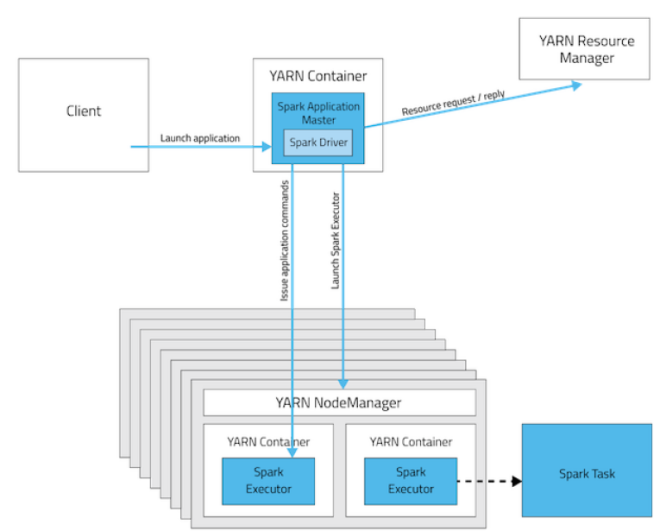
driver端在yarn集群里面,所以不好调试日志。客户端一经提交可以离开,常用于正常的提交应用,适合生产环境。
可以看出来,appMaster和driver在一起的,就算是client断开,任务还可以继续运行。
如果不配置运行参数,默认启动两个executor。
执行语句如下:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--queue master \
--deploy-mode cluster \
/usr/local/spark/examples/jars/spark-examples_2.12-3.5.5.jar \
20000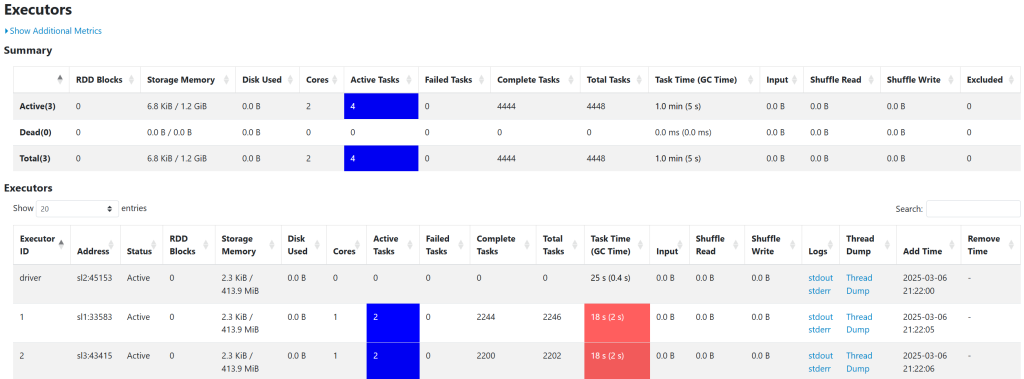
可以看出来,driver已经与client不是同一个了。
查看日志可以使用:
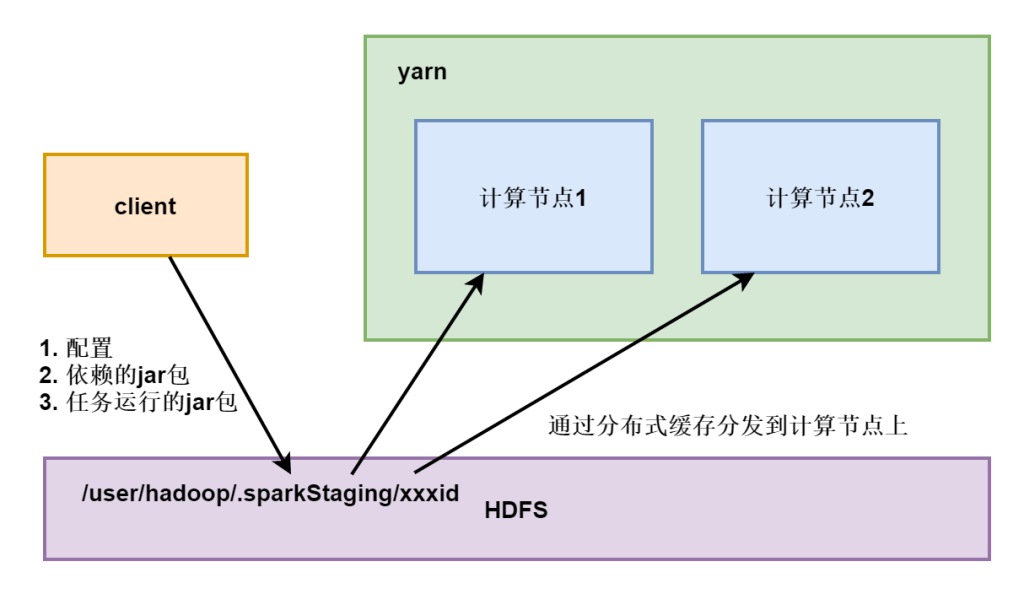
yarn logs -applicationId application_1741266478854_0003 | grep 3.14任务在执行的时候可以看到,任务上传到hdfs中,含有的内容 jar、xml、split、额外jar。可以看到在/user/hadoop/.sparkStaging/applicationId/存在的依赖资源,运行结束自动删除。
spark on yarn提交流程
当spark在yarn上运行时,yarn要拿到 :
- 运行用的配置
- 运行要依赖的jar包,默认是SPARK_HOME/jars 目录下的jar包打包,如果想加入其它jar包,可通过 –jars 添加。
- 运行任务的jar包(带有代码的jar包)
这三种需要从提交程序端 上传到 /user/xxx/.sparkStaging/yarnid/目录下(分布式缓存),然后再分发到运行任务的计算节点。
spark 核心
- Spark基于弹性分布式数据集(RDD)模型,具有良好的通用性、容错性与并行处理数据的能力。当数据在内存存不下,才会把数据写到磁盘上。
- RDD( Resilient Distributed Dataset ):弹性分布式数据集(相当于集合),它的本质是数据集的描述(只读的、可分区的分布式数据集),而不是数据集本身
- RDD的关键特征:
- RDD使用户能够显式将计算结果保存在内存中,控制数据的划分,并使用更丰富的操作集合来处理
- 使用更丰富的操作来处理,只读(由一个RDD变换得到另一个RDD,但是不能对本身的RDD修改)
- 记录数据的变换而不是数据本身保证容错(lineage)
- 通常在不同机器上备份数据或者记录数据更新的方式完成容错,但这种对任务密集型任务代价很高
- RDD采用数据应用变换(map,filter,join),若部分数据丢失,RDD拥有足够的信息得知这部分数据是如何计算得到的,可通过重新计算来得到丢失的数据
- 这种恢复数据方法很快,无需大量数据复制操作,可以认为Spark是基于RDD模型的系统
- 懒操作,延迟计算,action的时候才操作
- 瞬时性,用时才产生,用完就释放
RDD不包含待处理数据,真正的数据只有在执行的时候才加载进来
加载数据主要由两个来源
- Spark外部(HDFS,本地磁盘)
- Spark内部(其他RDD)
Spark任务来说,最终的目标是Action(save, collect)
构建RDD方式
Spark允许从以下四个方面构建RDD
- 从共享文件系统中获取,如从HDFS中读数据构建RDD
val a = sc.textFile(“/xxx/yyy/file”)sc. => Sparkcontext是spark的入口,编写spark程序用到的第一个类,包含sparkconf sparkenv等类
- 通过现有RDD转换得到
val b = a.map(x => (x, 1))
- 定义一个scala数组
val c = sc.parallelize(1 to 10, 1)
- 有一个已经存在的RDD通过持久化操作生成
val d = a.persist(), a. saveAsHadoopFile(“/xxx/yyy/zzz”)
RDD分类
Spark针对RDD提供两类操作:transformations和action
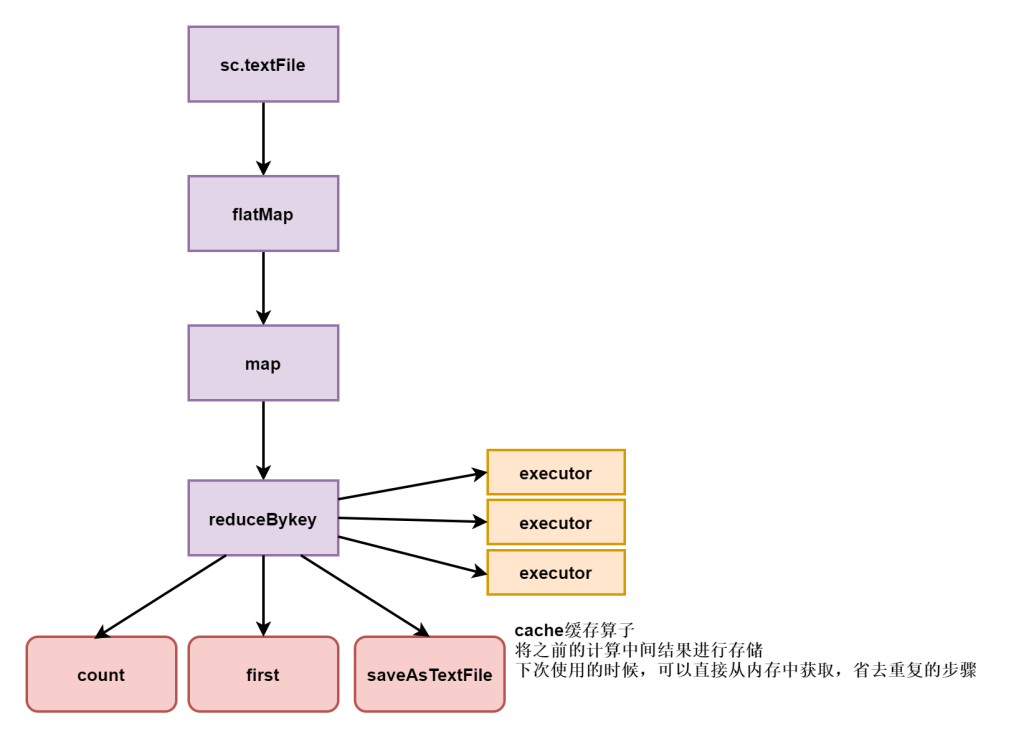
- Transformation 算子 转换算子——转换并不是触发提交,完成作业中间过程处理。
- Action 算子 行为算子——触发作业,触发sparkcontext(sc),可以将结果输出到HDFS、hbase、kafka、console(终端),也可以不输出(for循环)
transformations是RDD之间的变换,action会对数据执行一定的操作。
transformations是RDD之间的变换,action会对数据执行一定的操作。
transformations采用懒策略,仅在对相关RDD进行action提交时才触发计算。延迟计算
——懒惰机制

算子细分如下,对于transformations算子:
- 一对一:map、flatmap
- 多对一:union、cartesian(笛卡尔积)
- 多对多:groupby
- 输出是否是输入子集合:filter、distinct
- cache类:cache、persist(是包含cache的)
- 聚集:reduceByKey、combineByKey、PartitionBy
- 连接:join、leftOutJoin、rightOutJoin
Action(行为算子)——触发(sparkcontext:sc)作业,可以将结果输出hdfs、hbase、kafka、console
- 无输出:foreach(for循环)
- 有输出:saveAsTextFile
- 统计类:count、collect、take
应用开发环境
spark-shell开发
spark的代码分为两种
- 本地代码在driver端直接解析执行没有后续
- 集群代码,会在driver端进行解析,然后让多个机器进行集群形式的执行计算
首先启动spark-shell,我们这里使用standalone模式
spark-shell --master spark://nn1:7077 --executor-memory 1G --executor-cores 2-- 注意这里是hdfs目录,不是本地,这是集群代码,这个命令所有机器都会执行
scala> sc.textFile("/test/a.txt")
-- 生成一个rdd
res6: org.apache.spark.rdd.RDD[String] = /test/a.txt MapPartitionsRDD[5] at textFile at <console>:24
scala> res6.flatMap(_.split(" "))
res7: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at flatMap at <console>:24
scala> res7.map((_,1))
res8: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[7] at map at <console>:24
scala> res8.groupBy(_._1)
res9: org.apache.spark.rdd.RDD[(String, Iterable[(String, Int)])] = ShuffledRDD[9] at groupBy at <console>:24
// 分组完毕后的返回值不再是map,而是一个RDD[String, Interable]
scala> res9.mapValues(_.size)
res10: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[10] at mapValues at <console>:24
// mapValues在scala中只能作用在map集合上,现在可以作用在RDD[k,v]
scala> res10.foreach(println)
// 打印数据的时候每个机器都有,因为是分布式执行的
[Stage 0:> (0 + 0) / 2rdd就是一个集合,如果是sc调用的方法会在集群中执行,rdd调用的方法也会集群执行。
因为在spark-env.sh文件中配置了HADOOP_CONF_DIR,所以可以直接读取hdfs中的文件。
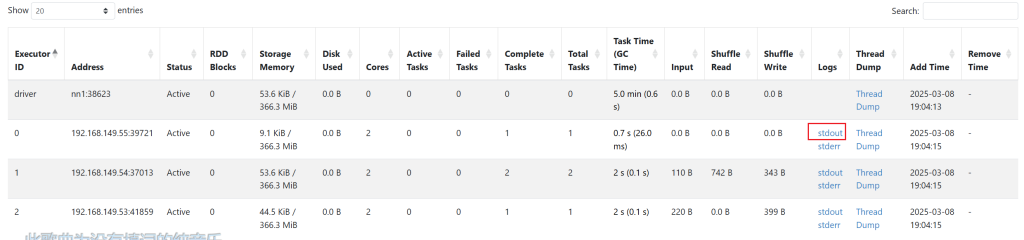
程序执行完毕后,因为是分布式的,写代码的时候在driver,真正执行的时候在executor中,我们不在一起,所以看不到结果。可以去executor中查看,打开WEB UI,选择executor。
IDEA开发及配置
1. 安装scala插件
ctrl+alt+s进入设置页面,点击plugin搜索scala安装,安装完毕重启
配置sdk
2. 添加maven依赖
<dependencies>
<!-- Spark Core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.5.5</version>
</dependency>
<!-- Hadoop Client (与你的 Hadoop 3.4.0 一致) -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.4.0</version>
</dependency>
<!-- Log4j 2.x + SLF4J 桥接(避免 Log4j 1.x 漏洞) -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.20.0</version> <!-- 安全版本 -->
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.20.0</version>
</dependency>
</dependencies>3. 添加 log4j2.properties 在src/main/resources
status = error
name = Log4j2Config
appender.console.type = Console
appender.console.name = Console
appender.console.target = SYSTEM_OUT
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yy/MM/dd HH:mm:ss} %p %c{1}:%M(): %m%n
rootLogger.level = info
rootLogger.appenderRefs = Console
rootLogger.appenderRef.Console.ref = Consolewordcount 开发
scala本地版本
先使用本地执行,本地执行的时候,需要指定AppName和Master为local[*]
代码如下:
package com.lmk.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
/**
* 步骤
* 1. 读取数据
* 2. 打平,split
* 3. (单词,1)
* 4. 分组
* 5. 求和
* sc rdd 他们调用的方法是集群执行的
*/
object WorldCount {
def main(args: Array[String]): Unit = {
val config = new SparkConf()
config.setAppName("WordCount")
// 本地执行
config.setMaster("local[*]")
val sc = new SparkContext(config)
//sc.textFile("data/a.txt").flatMap(_.split(" ")).map((_, 1)).reduceBy(_._1).mapValues(_.size).foreach(println)
val rdd:RDD[String] = sc.textFile("data/a.txt")
val rdd1:RDD[String] = rdd.flatMap(_.split(" "))
val rdd2:RDD[(String, Int)] = rdd1.map((_, 1))
val rdd3:RDD[(String, Iterable[(String, Int)])] = rdd2.groupBy(_._1)
val rdd4:RDD[(String, Int)] = rdd3.mapValues(_.size)
// 执行延迟设置,执行的时候同样可以在localhost:4040查看
//val rdd5:RDD[(String, Int)] = rdd3.mapValues(x=>{
// Thread.sleep(Long.MaxValue)
// x.size
//})
rdd4.foreach(println)
}
}返回结果如下:

scala本地生成文件
在输出成本地文件的时候,使用的是mr原生的存储方式,需要注意,如果输出文件存在,就会报错,所以我们先写定义隐式转换的工具类,对存在的文件进行删除。
package com.lmk.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
object FileUtils {
implicit def strFileUtils(s: String): FileUtils = new FileUtils(s)
}
class FileUtils(path:String) {
def delete = {
val fs = FileSystem.getLocal(new Configuration())
if(fs.exists(new Path(path))) {
fs.delete(new Path(path), true)
}
}
}
然后可以直接使用 path.delete 删除文件了
//rdd4.foreach(println)
val output = "data/res"
output.delete
// 输出的文件夹不能存在
rdd4.saveAsTextFile(output)打包集群运行
在打包的时候,不仅将源码打包,还需要将maven依赖也打包进去(如果只是sapark代码确实可以不用maven依赖)。
在打包之前需要修改一下代码,当前的代码是不能运行的,修改步骤如下:-submit –master
- 输入路径和输出路径都变化
- 受数据的时候使用args
- 需要进行编译
- maven项目分为两个 src中这里面是人为开发的源码
- target目录是编译后的class文件
- package打包,就是将target目录中的所有class文件打成一个jar包
- 最好用的编译方式,运行不管是不是出错肯定先编译
代码如下:
package com.lmk.spark
import com.lmk.spark.FileUtils.strFileUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WorldCountForCluster {
def main(args: Array[String]): Unit = {
val Array(input, output) = args
val config = new SparkConf()
// config.setAppName("WordCount")
// config.setMaster("local[*]")
val sc = new SparkContext(config)
val rdd:RDD[String] = sc.textFile(input)
val rdd1:RDD[String] = rdd.flatMap(_.split(" "))
val rdd2:RDD[(String, Int)] = rdd1.map((_, 1))
val rdd3:RDD[(String, Iterable[(String, Int)])] = rdd2.groupBy(_._1)
val rdd4:RDD[(String, Int)] = rdd3.mapValues(_.size)
output.delete
// 输出的文件夹不能存在
rdd4.saveAsTextFile(output)
}
}执行,进行编译后,使用maven工具打包,双击package
上传集群后,standalone执行语句如下:
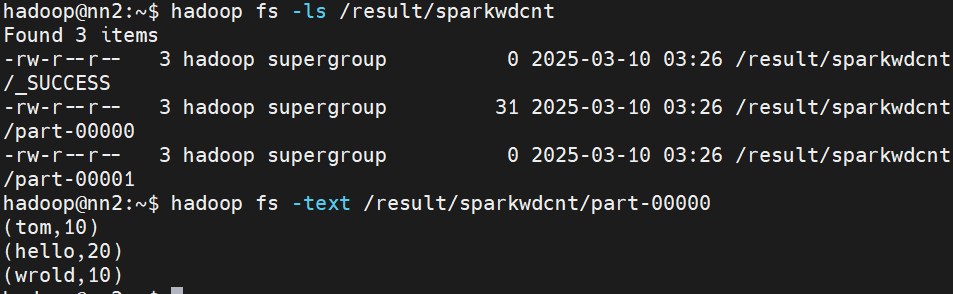
spark-submit --master spark://nn1:7077 --executor-memory 1G --total-executor-cores 6 --class com.lmk.spark.WorldCountForCluster spark-1.0-SNAPSHOT.jar /test/a.txt /result/sparkwdcnt执行完毕后,输出结果会放到指定目录中。
RDD
在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。显然,如果能将结果保存在内存当中,就可以减少大量IO。
RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的落地存储,大大降低了数据复制、磁盘IO和序列化开销。
RDD概念
RDD(Resilient Distributed Datasets,弹性分布式数据集)代表可并行操作元素的不可变分区集合。
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段(HDFS上的块),并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
RDD不是数据,RDD也不存数据,只存储数据的分区信息和读取方法(HDFS、其他RDD)。表示数据在流动到此处的时候要进行什么样的处理,可以理解为rdd是一个代理对象。
每个RDD包含了数据分块/分区(partition)的集合,每个partition是不可分割的。
RDD Stage和依赖关系
首先说一下stage,一次性处理,在内存中加载过程叫做一个阶段。比如以下图例
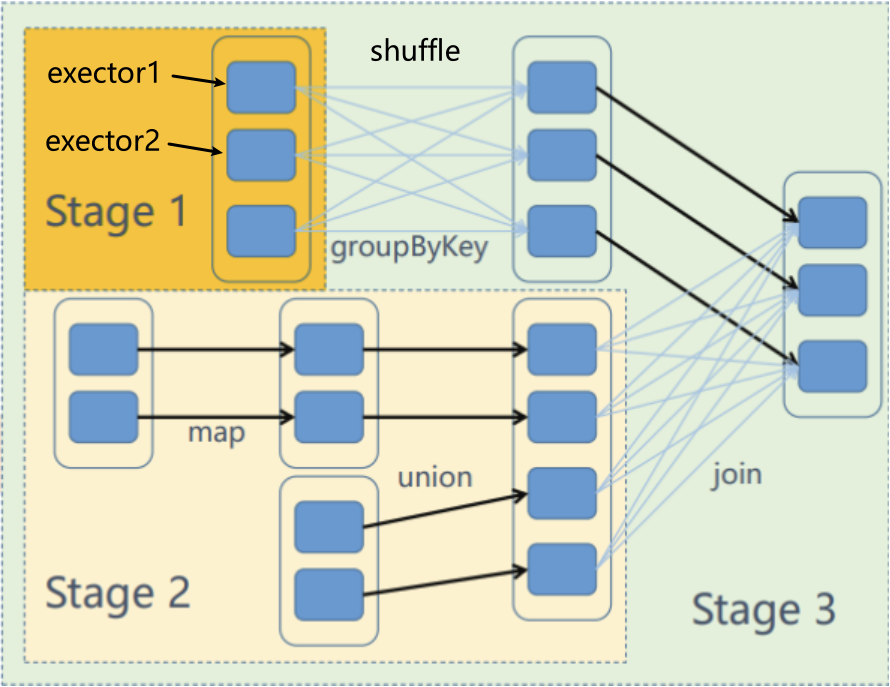
RDD的依赖关系(rddA=>rddB)
- 宽依赖: B的每个partition依赖于A的所有partition。宽依赖一般数据会备份。因为获取困难
- 比如groupByKey、reduceByKey、join……,由A产生B时会先对A做shuffle分桶
- 窄依赖: B的每个partition依赖于A的常数个partition。窄依赖一般会之间重新按照顺序执行,因为获取较快。
- 比如map、filter、union……
上面图中,从后往前,将宽依赖的边删掉,连通分量及其所在原图中所有依赖的RDD,构成一个stage
DAG是在计算过程中不断扩展,在action后才会启动计算。
每个stage内部尽可能多的包含一组具有窄依赖关系的转换,并将他们流水线并行化(pipeline)
切分阶段的好处,运行任务的时候,我们知道按照什么样的逻辑进行,这个执行过程是按照阶段为主体的。整个业务时不需要将数据写出磁盘的,避免很多IO和序列化反序列化,这就是DAG图的整体。
在一个阶段中业务时一样的,但是这个业务逻辑会并行执行,每个并行都是一个task任务,例如 sc.textFile.flatMap.map => task,有几个分区就有几个task任务。
shuffle:上游的数据因为分组或排序时,需要将上游的数据分发到下游。上游任务将所有的数据处理完毕后,把数据放入本地,下游去拿去这个数据的过程就是shuffle。
job:从第一个算子开始到action算子结束,整个过程是一个job,所以一个main方法中是可以存在多个action算子的,一个action算子就是一个job任务。
任务的执行和层级关系
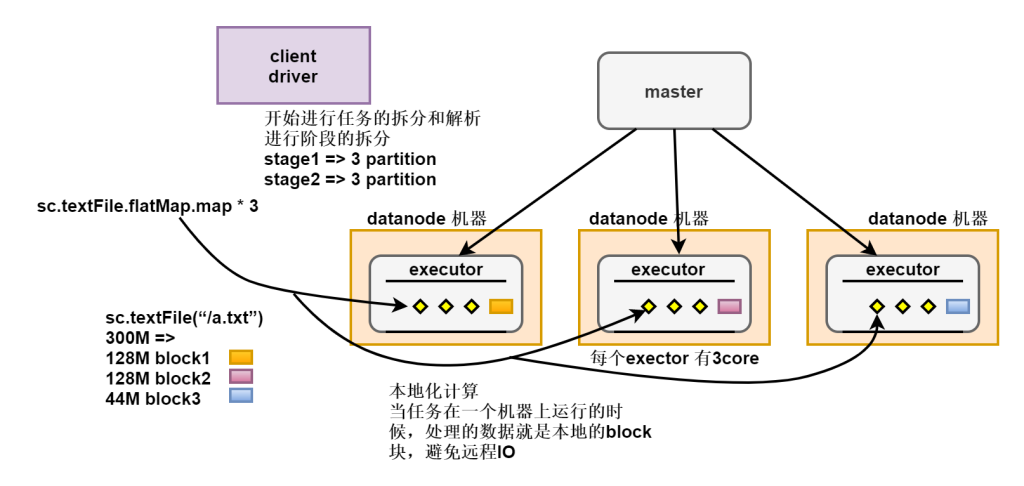
读取hdfs数据的时候映射是一个block块对应一个partition分区。
总结:
- 在一个任务中,一个action算子会生成一个job
- 在一个job中存在shuffle算子,比如group sort切分阶段,shuffle就+1个阶段
- shuffle是任务的划分的重点,前面的任务会将数据放入到自己的本地存储,后续的任务进行数据的拉取
- 在一个stage中任务都是管道形式执行的,避免了IO,序列化和反序列化,这个就是dag切分的原理
- 在一个阶段中分区数量就是task任务的数量,task任务就是一堆非shuffle类算子的整体任务链
- 有几个分区就会并行的执行几个task任务
- 有几个分区是根据读取的文件来进行适配的,比如有三个block那么就会生成三个分区,因为我们可以在每个分区中进行处理数据,实现本地化的处理,避免远程IO
RDD缓存和内存管理
cache算子
cache算子能够缓存中间结果数据到各个executor中,后续的任务如果需要这部分数据就可以直接使用避免大量的重复执行和运算。
cache源码如下:
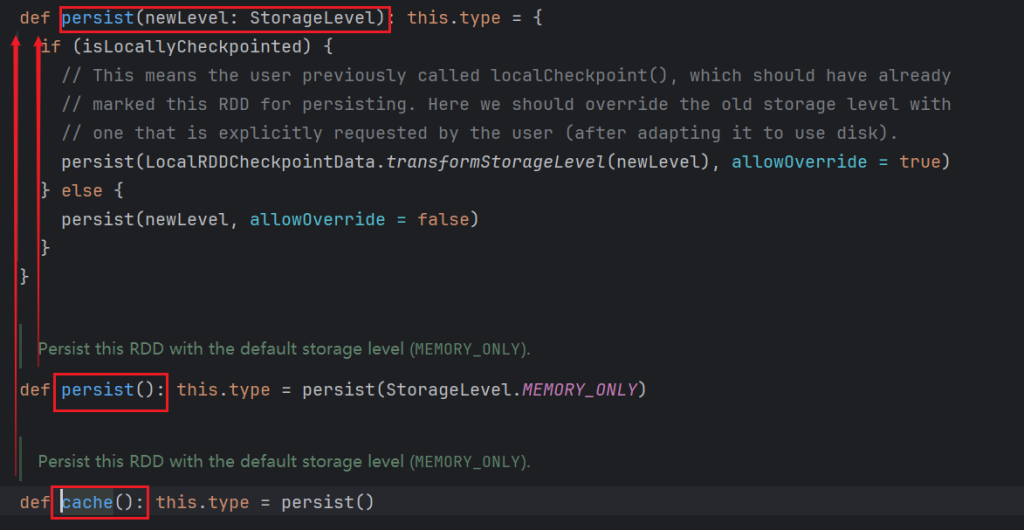
rdd 存储级别中默认使用的算子cache算子,cache算子的底层调用的是persist算子,persist算子底层使用的是persist(storageLevel)默认存储级别是memoryOnly。
scala> sc.textFile("/test/a.txt")
res0: org.apache.spark.rdd.RDD[String] = /test/a.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> res0.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
res2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:24
scala> res2.cache()
res3: res2.type = ShuffledRDD[4] at reduceByKey at <console>:24
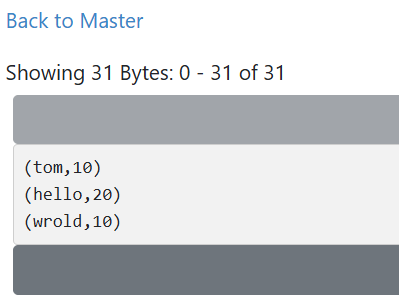
scala> res3.first
res6: (String, Int) = (tom,10)
scala> res3.count
res7: Long = 3
scala> res3.collect
res8: Array[(String, Int)] = Array((tom,10), (hello,20), (wrold,10))cache算子是转换类算子,不会触发执行运算,count算子触发运算,后续的算子的使用就可以直接从内存中取出值了。
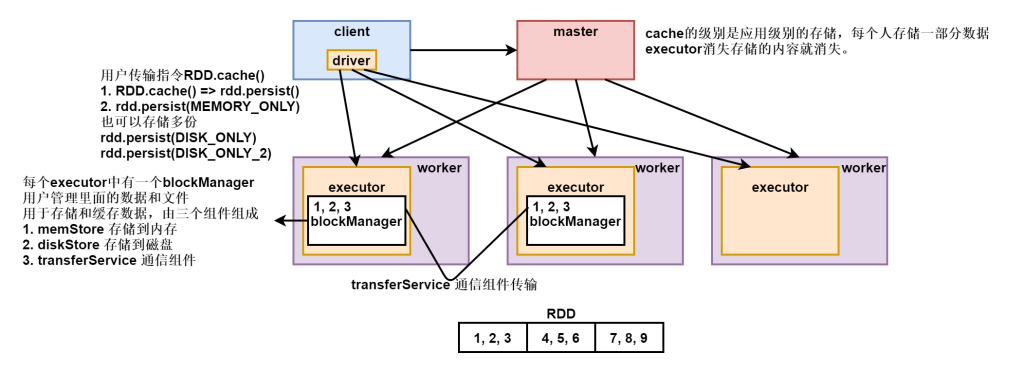
cache算子的存储位置
每个executor中都存在一个blockManager的组件,这个组件主要是executor缓存数据用的,并且是job级别。
每个blockManager中存在三个组成部分 memstore diskStore transferService。
rdd的缓存级别
rdd的存储级别选项如下:
object StorageLevel {
// 四个参数分别为_useDisk(是否使用磁盘)、_useMemory(是否使用内存)、_useOffHeap、_deserialized(是否非序列化)
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val DISK_ONLY_3 = new StorageLevel(true, false, false, false, 3)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)存储级别分12种,分别根据构造器的参数不同构造出来。
none:不存储DISK_ONLY:仅磁盘方式,磁盘必须存储序列化的, _deserialized = falseDISK_ONLY_2:存储磁盘并且备份数量2MEMORY_ONLY:仅内存_deserialized = true 不序列化,executor就是一个jvm,使用的内存是jvm的内存,可以直接存储对象数据。MEMORY_ONLY_SER:仅内存并且是序列化的方式 _deserialized = true,将存储的jvm中的对象进行二进制byte[],存储起来,以内存的方式,序列化完毕的数据更能够减少存储空间。MEMORY_AND_DISK:先以内存为主,然后再使用磁盘,存储空间不够不会报错,会存储一部分数据,可以不序列化,不序列化指的是内存的部分。MEMORY_AND_DISK_SER:存储的时候将存储的内容先序列化然后存储OFF_HEAP:堆外内存,一个机器中除了jvm以外的内存,又叫做直接内存。比如worker内存总共2G,一个executor的jvm占用1G,堆外内存就是剩下的1G。- 首先存储到直接内存中,可以使得jvm的内存使用量减少,效率更高,但是比较危险。
- jvm中存在GC(垃圾回收器),可以清空垃圾,但是如果使用直接内存的话,垃圾多了我们可以删除,但是如果应用程序异常退出,这个时候内存是没有人可以管理的。
缓存的使用
scala> sc.textFile("/test/a.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
res0: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:24
scala> res0.cache()
res1: res0.type = ShuffledRDD[4] at reduceByKey at <console>:24
scala> res1.count
res3: Long = 3
scala> res1.collect
res4: Array[(String, Int)] = Array((tom,10), (hello,20), (wrold,10))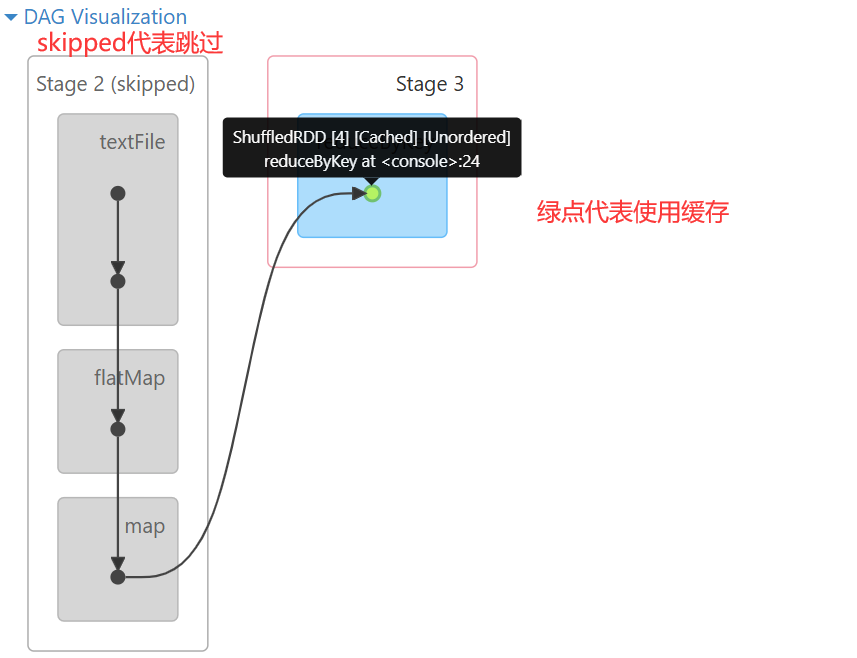
查看缓存数据

缓存的位置可以进入页面查看
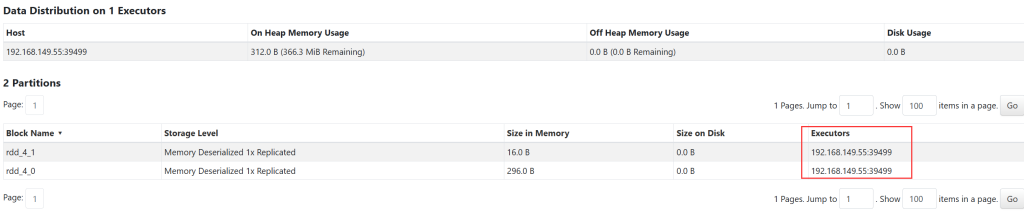
去除缓存
rdd.unpersist()
scala> res1.unpersist()
res5: res1.type = ShuffledRDD[4] at reduceByKey at <console>:24缓存是应用级别的,spark-shell它启动完毕的所有job都可以使用,关闭应用缓存也会失效
checkpoint
cache是应用级别的,spark-submit或者是spark-shell提交完毕都会启动一套executor。
在这个应用中执行的所有job任务都可以共享cache的缓存数据,当然是单个应用的
多个应用共享一份数据怎么进行实现。
checkpoint就是实现多应用共享数据的一种方式,原理就是一个应用将数据存储到外部,一个大家都能访问的位置,然后就可以直接使用了,使用的存储是hdfs,saveAsTextFile存储起来。
scala> sc.textFile("/test/a.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
res6: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[9] at reduceByKey at <console>:24
// 报错,需要指定存储路径
scala> res6.checkpoint
org.apache.spark.SparkException: Checkpoint directory has not been set in the SparkContext
at org.apache.spark.errors.SparkCoreErrors$.checkpointDirectoryHasNotBeenSetInSparkContextError(SparkCoreErrors.scala:160)
at org.apache.spark.rdd.RDD.checkpoint(RDD.scala:1660)
... 47 elided
// 这里指定的是hdfs路径
scala> sc.setCheckpointDir("/ckpt")
25/04/27 13:47:48 WARN SparkContext: Spark is not running in local mode, therefore the checkpoint directory must not be on the local filesystem. Directory '/ckpt' appears to be on the local filesystem.
scala> res6.checkpoint
scala> res6.count
res10: Long = 3
存储的hdfs的文件可以查看一下,与saveAsTextFile的结果一样。
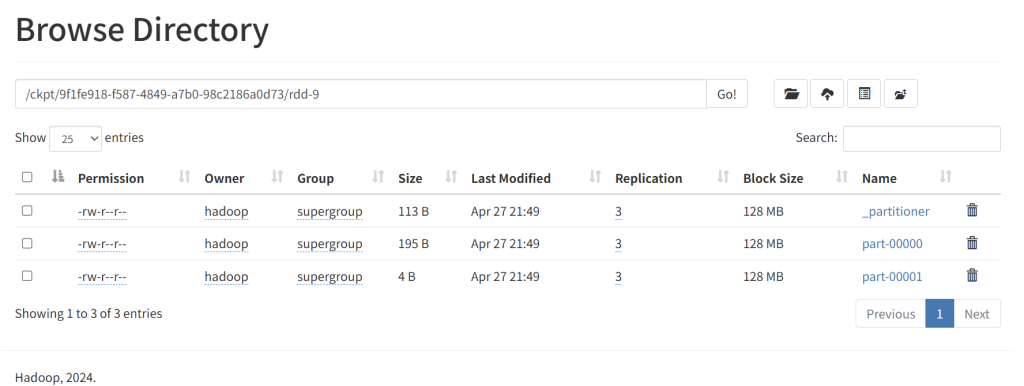
如果再执行操作,那么就可以直接从ckpt中获取数据了,前面的计算逻辑都被跳过。
scala> res6.first
res11: (String, Int) = (tom,10)
cache与checkpoint的区别
- checkpoint数据共享,现在数据已经存储到hdfs中了,我们直接从hdfs中拿,实现多应用共享
- cache数据缓存完毕,下次使用的时候逻辑是不截断的,ckpt是截断的,前面什么都没有了
- checkpoint是存储数据到hdfs的共享盘中,cache是存储到内存的缓存中,所以ckpt需要另外触发一次计算才可以
一次性调用collect,但是spark会执行两个任务
scala> sc.textFile("/test/a.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
res12: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[15] at reduceByKey at <console>:24
scala> res12.checkpoint
scala> res12.collect
res14: Array[(String, Int)] = Array((tom,10), (hello,20), (wrold,10))
第一次的任务是collect,第二次的任务是为了存储数据到外部。所以为了优化任务的执行
rdd.cache()
rdd.checkpoint()
cache和checkpoint连用,这样的话,第二次执行的时候就可以直接从缓存中读取数据了,不需要进行第二次计算。
RDD五大特性
rdd的源码注释如下:
- A list of partitions 每个RDD都存在一系列分区列表
- A function for computing each split 每个RDD上面都存在comput算法进行计算
- A list of dependencies on other RDDs 每个RDD上面都存在一系列的依赖关系
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) 在k-v类型的rdd上面存在可选的分区器
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file) 优先位置进行计算
每个RDD都存在一系列分区列表
每个rdd都存在一系列的分区列表,rdd弹性分布式数据集,必须是存在分区的,因为存在分区才会让集群多个线程进行执行,并行操作速度和效率更快。
分区可以进行调节,shuffle类算子可以修改分区,coalesce算子和repartition算子,修改分区在一定程度上可以增加计算效率。
一个阶段中的一个rdd的分区代表的是一个task任务,并且在读取hdfs文件的时候,一个block块对应的是一个分区,让数据的计算本地化执行。
每个RDD上面都存在comput算法进行计算
rdd是调用算子进行计算的,一个元素一个元素的进行计算,compute帮助进行递归rdd的数据使用用户定义的逻辑进行计算。
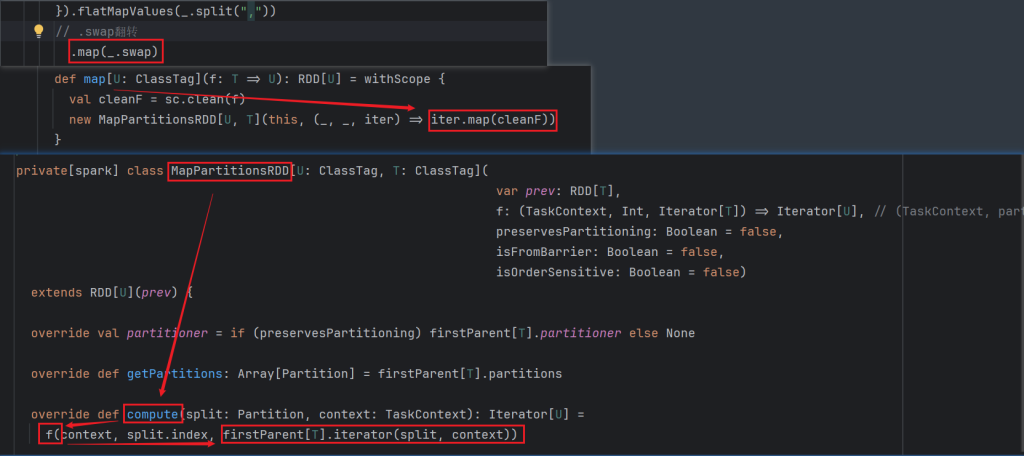
f这个函数就是用户自己定义的方法,最后遍历进行处理。compute方法是如何遍历RDD中的元素的,如下:
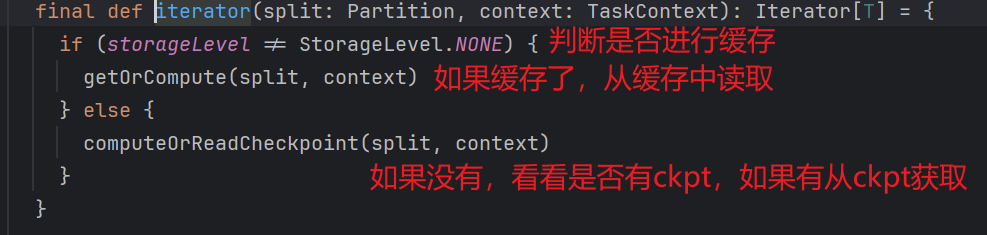

如果是缓存了,那么从缓存中读取数据 getOrCompute。

如果设置了缓存,并且已经有人计算完毕放入到缓存中了,那么直接从缓存中取值,如果缓存中没有值,我们需要计算并且存储到缓存中。
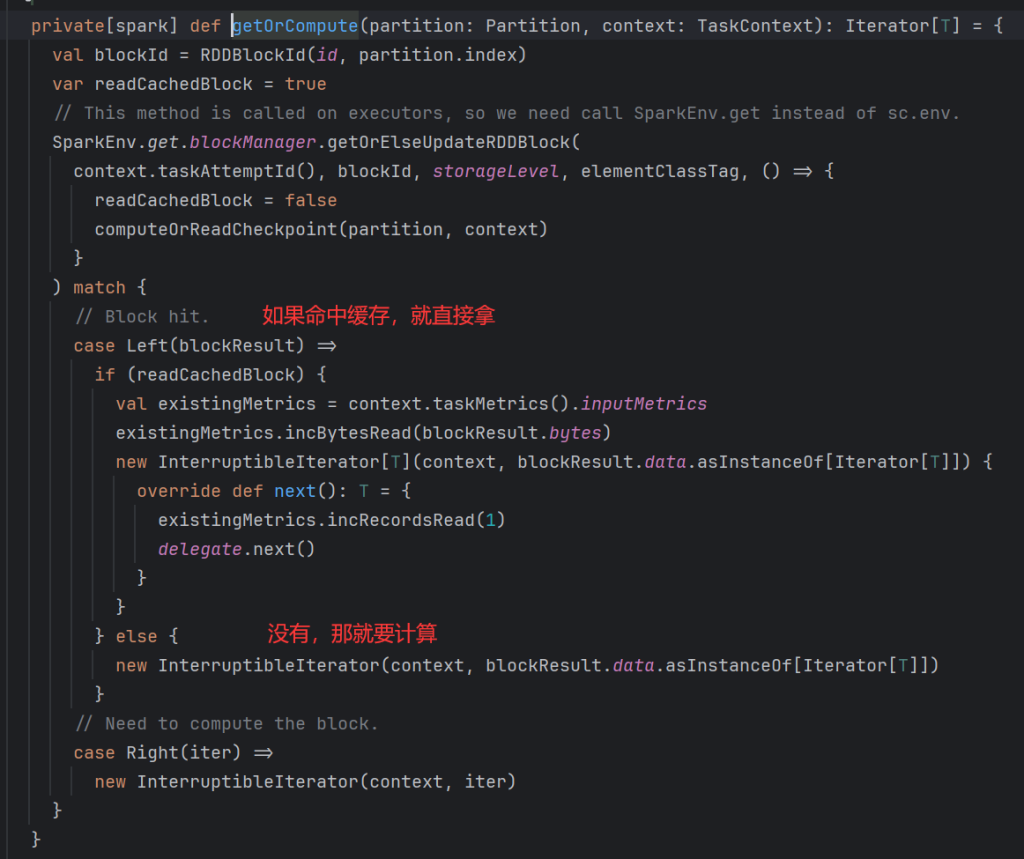
读取数据,如果命中就直接返回,如果没有命中就计算。
获取缓存数据如下:
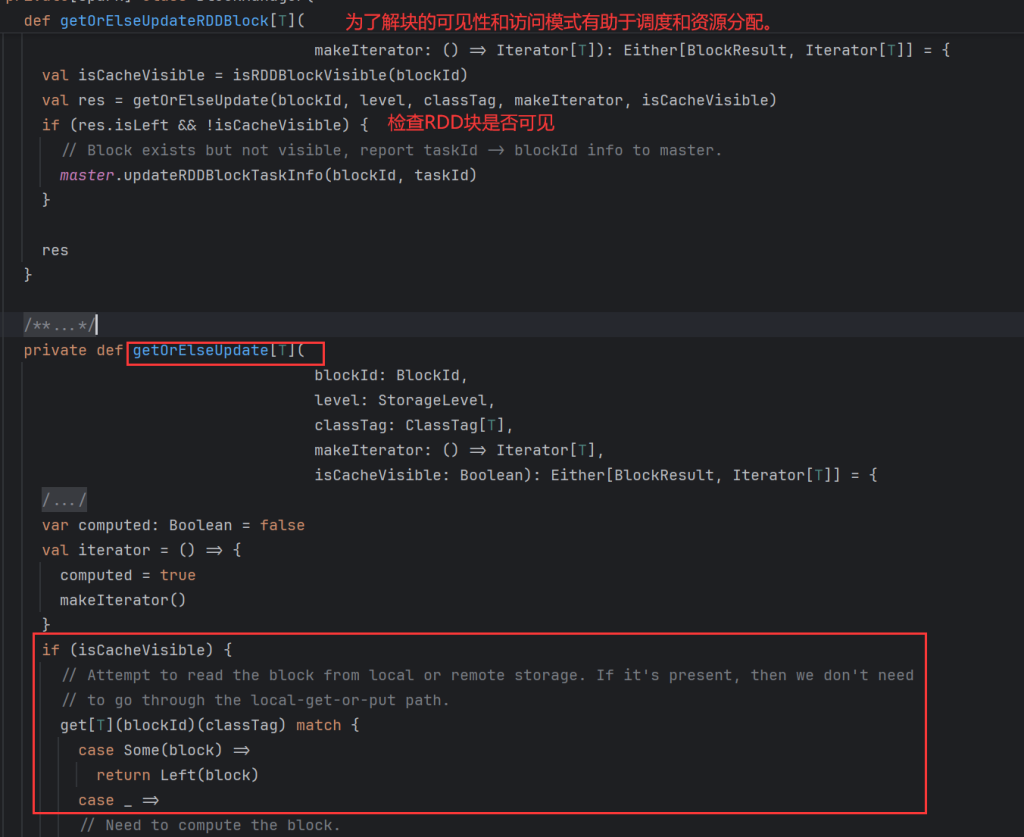
没有获取到数据需要进行计算,放入到缓存中,在从缓存中读取数据。
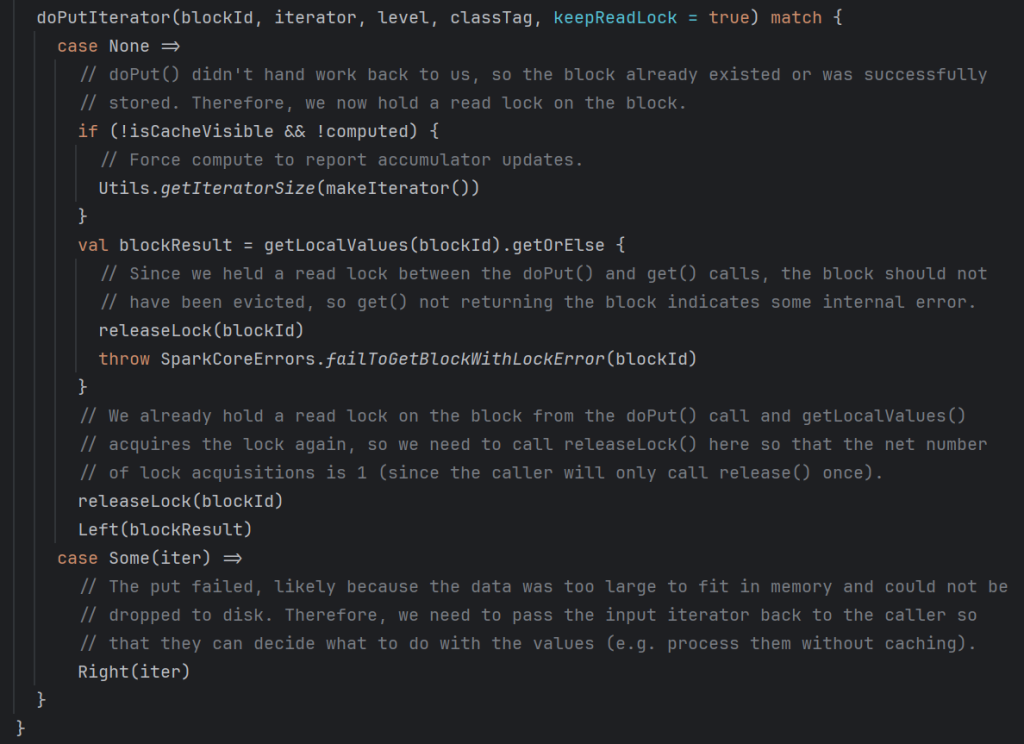
doPutIterator存储数据到缓存中,判断存储级别,分别放入数据到缓存或者磁盘中并且对数据进行备份和副本。然后当放入完毕以后再次从缓存中读取数据。
每个RDD上面都存在一系列的依赖关系
rdd之间存在一系列的依赖关系,所说的依赖关系就是rdd之间的关系,依赖关系就是算子的关系,转换类算子的关系,比如调用的算子不同关系也不相同。
宽依赖、窄依赖
shuffle就是宽依赖,非shuffle的算子就是窄依赖

- 窄依赖:以流水线的方式计算分区
- map flatMap mapPartitions filter 一对一的关系
- 宽依赖:必须计算好父分区的数据,然后进行shuffle
- groupBy sortBy groupByKey sortByKey reduceBykey 他们都是带有shuffle的算子
失效问题处理:
- 窄依赖:只需要计算丢失RDD分区的父分区,不同节点可以并行
- 宽依赖:单点失效了,可能导致整个RDD所有祖先丢失的分区重新计算
宽依赖
窄依赖
窄依赖还分三类:
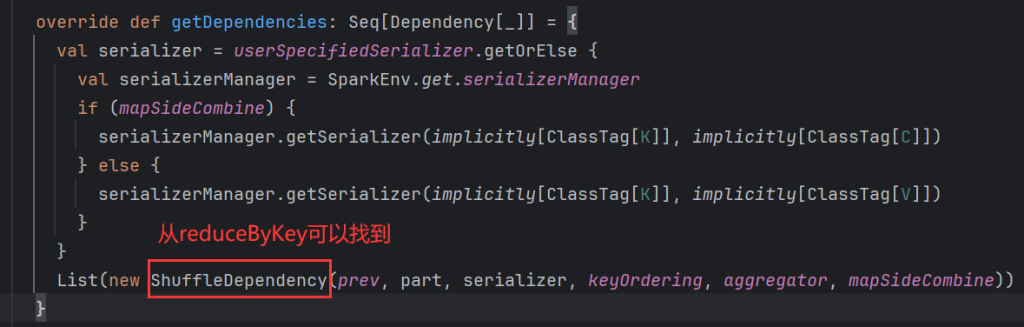
- oneToOneDependency: 一个对一个的关系,例如 map FlatMap filter…
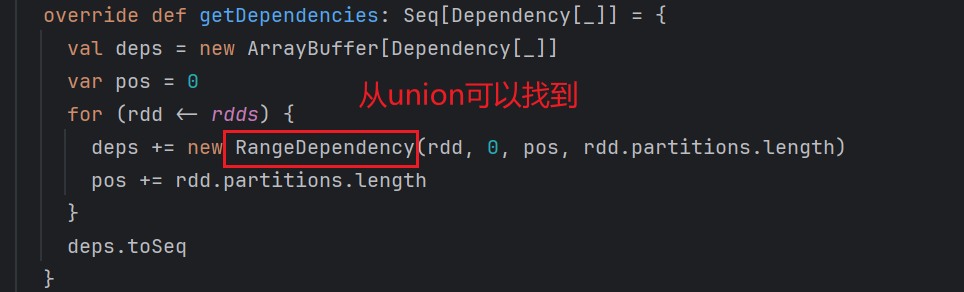
- rangeDependency: union范围依赖
- pruneDependency: filterByRange 子类关系,父节点的部分数据被子节点继承了,排序完毕的结果被子节点继承一部分
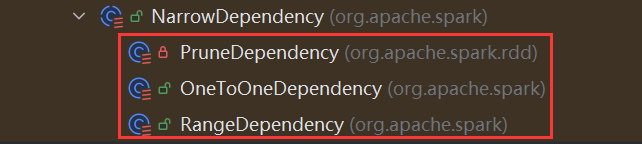
oneToOneDependency: 通过map算子可以看到
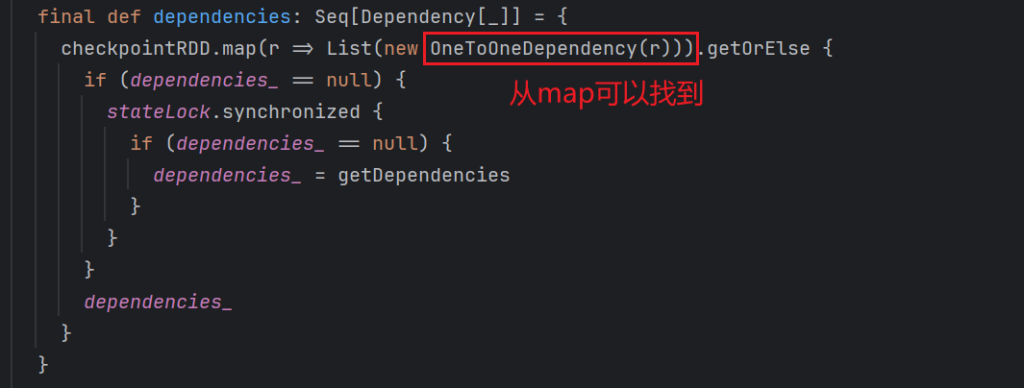
rangeDependency: 通过union算子可以找到
pruneDependency: 通过filterByRange可以找到,需要用到前面RDD几个分区的数据。

在k-v类型的rdd上面存在可选的分区器
首先rdd上面是不存在分区器的,只有调用了shuffle类算子才会有分区器,默认的分区器HashPartition[分组]。
rangePartitioner[排序] 同样我们可以人为自定义分区器,但是不管是人为的还是系统自带的都需要在Key进行处理
不是kv类型的rdd肯定没有分区器,kv类型的rdd上面不一定存在分区器,分区器可以规定数据的流向,上游数据到下游相应分区中是可以定义规则的。
优先位置进行计算
一般数据的切片大小和block块的大小是一一对应的,可以实现本地化执行操作,block块在哪任务就在哪,避免了远程io
读取hdfs的文件切片计算逻辑中就可以找到
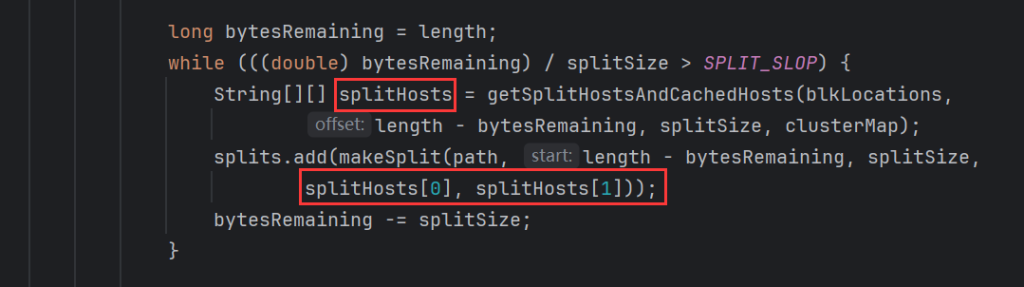
每次形成切片的时候都带有block的域名信息,处理和计算的时候就可以直接找到地址,按照本地化进行执行
spark内存管理
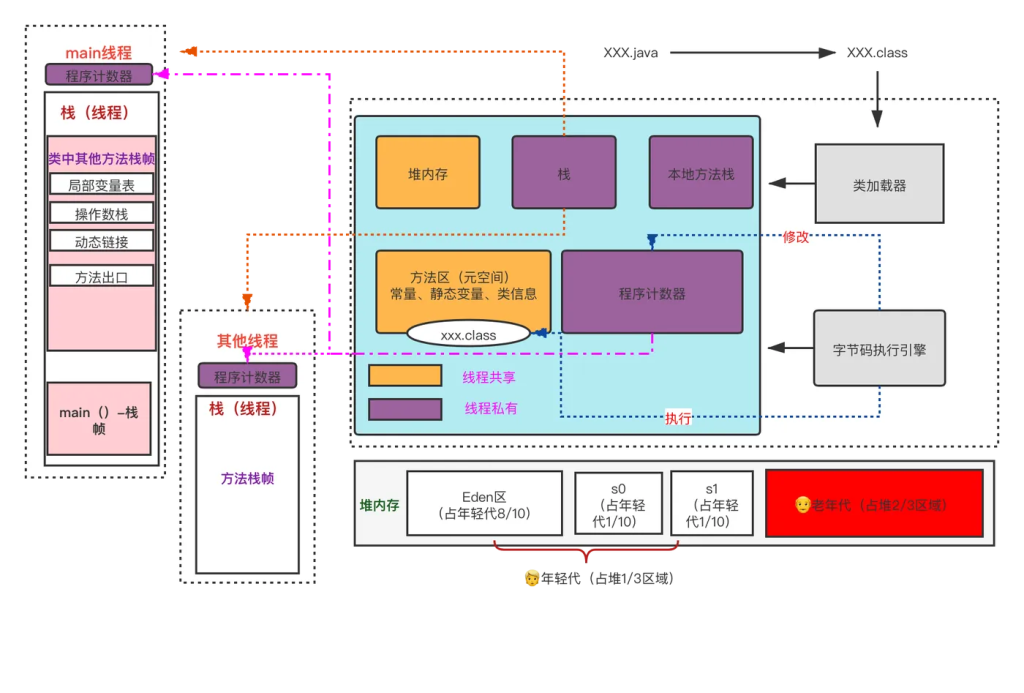
spark由scala开发,而scala的底层是java。所以最终还是基于JVM的。
Spark 作为一个以擅长内存计算为优势的计算引擎,内存管理方案是其非常重要的模块。Spark的内存可以大体归为两类:
- execution(运行内存),包括shuffles、joins、sorts和aggregations所需内存
- storage(存储内存),包括cache和节点间数据传输所需内存
spark中有两种内存的管理方式,分别是静态内存管理方式和统一内存管理方式(动态)
在Spark 1.5和之前版本里,运行内存和存储内存是静态配置的,不支持借用;Spark 1.6之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,提供更好的性能。
静态内存管理 spark1.5
spark1.5 的内存管理实现类: StaticMemoryManager
spark.storage.memoryFraction:
spark 存储总内存占 系统内存的百分比,默认是 0.6。
spark.shuffle.memoryFraction:
spark shuffle 执行用到的内存 占系统内存的百分比,默认是0.2。
spark.storage.safetyFraction:
可用的存储内存占总存储内存的百分比,默认是 0.9。
spark.shuffle.safetyFraction:
可用的shuffle操作执行内存占总执行内存的百分比, 默认是 0.8。
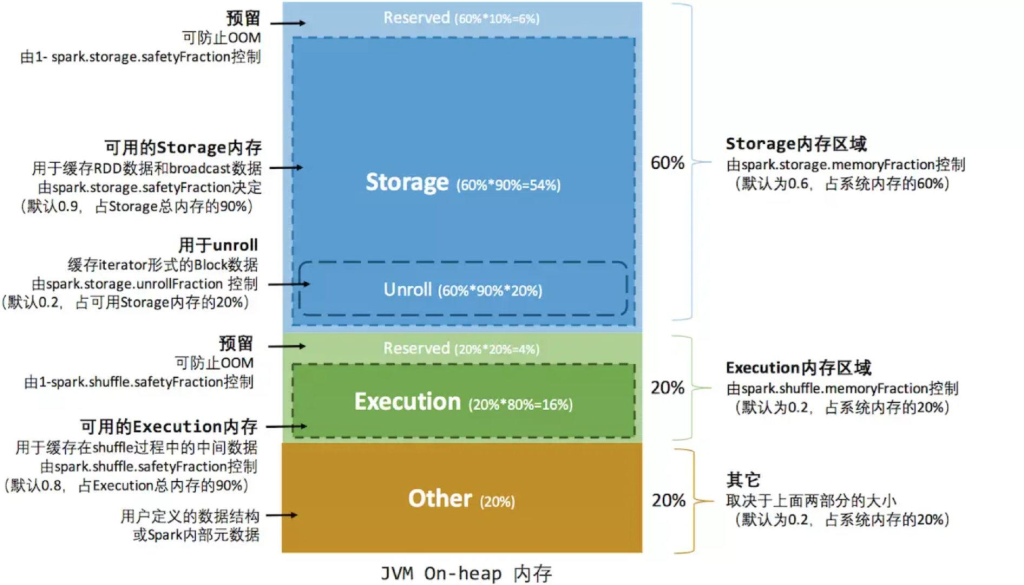
例如:
executor 的最大可用内存1000M
存储总内存 = 1000M * 0.6 = 600M
运行总内存 = 1000M * 0.2 = 200M
other = 1000M – 600M – 200M = 200M
存储总内存 = 安全存储内存 + 预留内存(防止OOM)
安全存储内存 = 存储总内存 * 0.9 = 600 * 0.9 = 540M
预留内存 = 存储总内存 * (1-0.9) = 60M
运行总内存 = 安全运行内存 + 预留内存(防止OOM)
安全运行内存 = 运行总内存 * 0.8 = 200M * 0.8 = 160M
预留内存 = 运行总内存 * (1-0.8) = 40M
缺点也是有的,这种内存管理方式的缺陷,即 execution 和 storage 内存分配,即使在一方内存不够用而另一方内存空闲的情况下也不能共享,造成内存浪费。
统一内存管理 spark1.6后
当spark.memory.useLegacyMode=false时,采用spark1.6 及以后的内存管理。
spark1.6及以后 的内存管理实现类: UnifiedMemoryManager
当前spark版本是 spark3.1.2 ,参数配置部分与spark1.6 不同,下面讲解按照spark3.1.2 版本进行参数讲解。
spark.memory.fraction:
spark内存占可用内存(系统内存 – 300)的百分比,默认是0.6。
spark.memory.storageFraction:
spark的存储内存占spark内存的百分比,默认是0.5。
spark的统一内存管理,可以通过配置 spark.memory.storageFraction ,来调整 存储内存和执行内存的比例,进而实现内存共享。
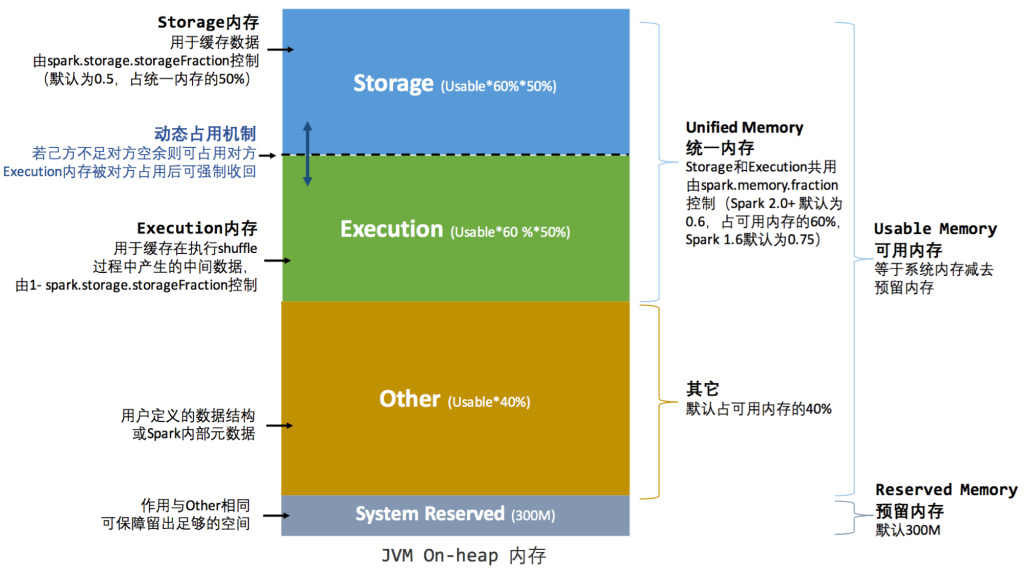
例如:系统内存1000M
系统预留内存 = 300M
可用内存 = 系统内存 – 系统预留内存 = 1000 – 300 = 700M
spark内存 = 可用内存 * 0.6 = 700 * 0.6 = 420M
存储内存 和 执行内存 均占一半, 210M
为了提高内存利用率,spark针对Storage Memory 和 Execution Memory有如下策略:
1)一方空闲,一方内存不足情况下,内存不足一方可以向空闲一方借用内存;
2)只有Execution Memory可以强制拿回Storage Memory在Execution Memory空闲时,借用的Execution Memory的部分内存(如果因强制取回,而Storage Memory数据丢失,重新计算即可);
3)Storage Memory只能等待Execution Memory主动释放占用的Storage Memory空闲时的内存。(这里不强制取回,因为如果task执行,数据丢失就会导致task 失败);
spark-shell默认执行spark-shell --master spark://nn1:7077,nn2:7077,nn3:7077 --executor-memory 1G,结果如下:
jvm的内存查看参数,添加下面的参数执行:
# 打印一些GC的详情
--conf "spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC"
# spark-shell执行代码如下
spark-shell --master spark://nn1:7077,nn2:7077,nn3:7077 --executor-memory 1G --conf "spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC"详情可以在stdout中查看。
spark-shuffle和共享变量
共享变量
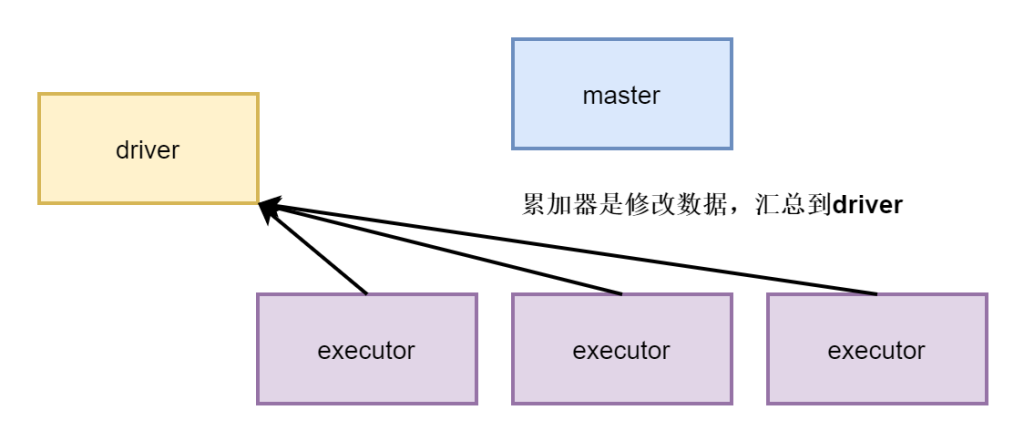
Spark两种共享变量:广播变量(broadcast variable)与累加器(accumulator)。
累加器用来对信息进行聚合,相当于mapreduce中的counter;而广播变量用来高效分发较大的对象,相当于semijoin中的DistributedCache 。
package com.lmk.spark
import org.apache.spark.{SparkConf, SparkContext}
object TestAcc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("TestAcc")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(Array(1,2,3,4,5,6,7,8,9), 3)
val count = rdd.map(x => 1).reduce(_ + _)
println(count)
// 累加器的计数,其实是一个辅助功能
// val acc = sc.longAccumulator("count")
// // var count = 0
//
// rdd.foreach(x => {
// acc.add(1)
// })
//
// println(acc.value)
}
}共享变量出现的原因:
我们传递给Spark的函数,如map(),或者filter()的判断条件函数,能够利用定义在函数之外的变量,但是集群中的每一个task都会得到变量的一个副本,并且task在对变量进行的更新不会被返回给driver。
原因总结:
- 对于executor端,driver端的变量是外部变量。
- excutor端修改了变量count,根本不会让driver端跟着修改。如果想在driver端得到executor端修改的变量,需要用累加器实现。
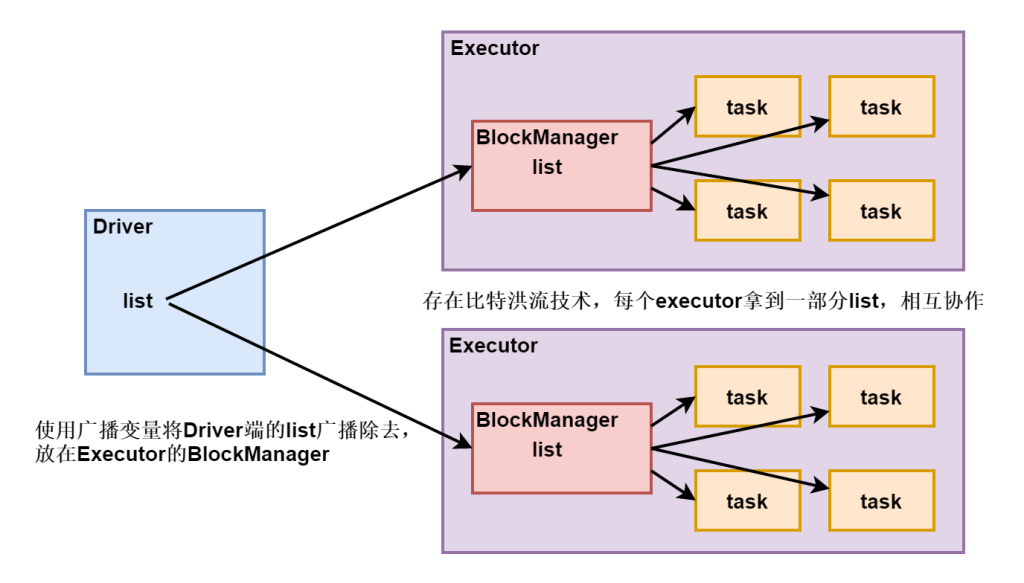
- 当在Executor端用到了Driver变量,不使用广播变量,在每个Executor中有多少个task就有多少个Driver端变量副本。如果这个变量中的数据很大的话,会产生很高的传输负载,导致执行效率降低,也可能会造成内存溢出。需要广播变量提高运行效率。
累加器
累加器可以很简便地对各个worker返回给driver的值进行聚合。累加器最常见的用途之一就是对一个job执行期间发生的事件进行计数。
用法:
var acc: LongAccumulator = sc.longAccumulator // 创建累加器
acc.add(1) // 累加器累加
acc.value // 获取累加器的值累加器的简单使用如下:
package com.lmk.spark
import org.apache.spark.{SparkConf, SparkContext}
object WordCountWithAcc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("WordCountWithAcc")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val acc = sc.longAccumulator("count")
sc.textFile("data/a.txt")
.flatMap(_.split(" "))
.filter{x=>
if(x.equals("shit")){
acc.add(1)
false
}else{
true
}
}
.map((_,1))
.reduceByKey(_+_)
.foreach(println)
println("invalid words: "+acc.value)
}
}广播变量
ip案例如下:
package com.lmk;
public class IpUtils {
public static Long ip2Long(String ip) {
String fragments[] = ip.split("[.]");
Long ipNum = 0L;
for(int i=0;i<fragments.length;i++) {
ipNum = Long.parseLong(fragments[i]) | ipNum << 8L;
}
return ipNum;
}
}代码如下:
package com.lmk.spark
import com.lmk.IpUtils
import org.apache.spark.{SparkConf, SparkContext}
object IpTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("IpTest")
val sc = new SparkContext(conf)
val accessRDD = sc.textFile("data/localhost_access_log.2025-05-14.txt")
.map(x => {
val strs = x.split(" ")
IpUtils.ip2Long(strs(0))
})
// 因为RDD在中不能嵌套RDD,所以需要转换成Array
// 这个ip的内容比较少,适合收集成一个集合,放入内存
val ipArr: Array[(Long, Long, String)] = sc.textFile("data/ip.txt")
.map(x => {
val strs = x.split("\\|")
(strs(2).toLong, strs(3).toLong, strs(6)+" "+strs(7))
}).collect()
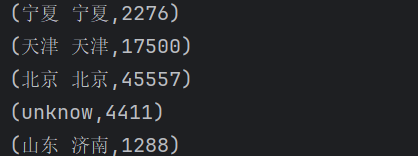
accessRDD.map(ip => {
ipArr.find(x => {
x._1 <= ip && x._2 >= ip
}) match {
case Some(v) => (v._3, 1)
case None => ("unknow", 1)
}
// option类型的数据
}).reduceByKey(_+_)
.foreach(println)
}
}返回结果如下:
使用广播变量可以使程序高效地将一个很大的只读数据发送到executor节点,会将广播变量放到executor的BlockManager中,而且对每个executor节点只需要传输一次,该executor节点的多个task可以共用这一个。
二分法优化
val bs = sc.broadcast(ipArr)
// 减少冗余存储,一个executor对应一份数据
accessRDD.map(ip => {
(binarySearch(bs.value, ip), 1)
// 一个一个找相当于笛卡尔积
// bs.value.find(x => {
// x._1 <= ip && x._2 >= ip
// }) match {
// case Some(v) => (v._3, 1)
// case None => ("unknow", 1)
// }
// option类型的数据
}).reduceByKey(_+_)
.foreach(println)
}
// 二分法,前提是ip需要有序
def binarySearch(arr: Array[(Long, Long, String)], ip: Long): String = {
var left = 0
var right = arr.length - 1
while (left <= right) {
val mid = (left + right) / 2
if (arr(mid)._1 <= ip && arr(mid)._2 >= ip) {
return arr(mid)._3
} else if (arr(mid)._1 > ip) {
right = mid - 1
} else {
left = mid + 1
}
}
"unknow"
}累加器运行时间统计
val acc = sc.longAccumulator("run time")
val bs = sc.broadcast(ipArr)
// 减少冗余存储,一个executor对应一份数据
accessRDD.map(ip => {
// 一个一个找相当于笛卡尔积
val start = System.currentTimeMillis()
val res = (binarySearch(bs.value, ip), 1)
// val res = bs.value.find(x => {
// x._1 <= ip && x._2 >= ip
// }) match {
// case Some(v) => (v._3, 1)
// case None => ("unknow", 1)
// }
val end = System.currentTimeMillis()
acc.add(end - start)
res
// option类型的数据
}).reduceByKey(_+_)
.foreach(println)
println("run time is " + acc.value)BlockManager分析
BlockManager是Spark的分布式存储系统,与我们平常说的分布式存储系统是有区别的,区别就是这个分布式存储系统只会管理Block块数据,它运行在所有节点上。
BlockManager的结构是Maser-Slave架构,Master就是Driver上的。
BlockManagerMaster,Slave就是每个Executor上的BlockManager。
BlockManagerMaster负责接受Executor上的BlockManager的注册以及管理。
BlockManager的元数据信息。
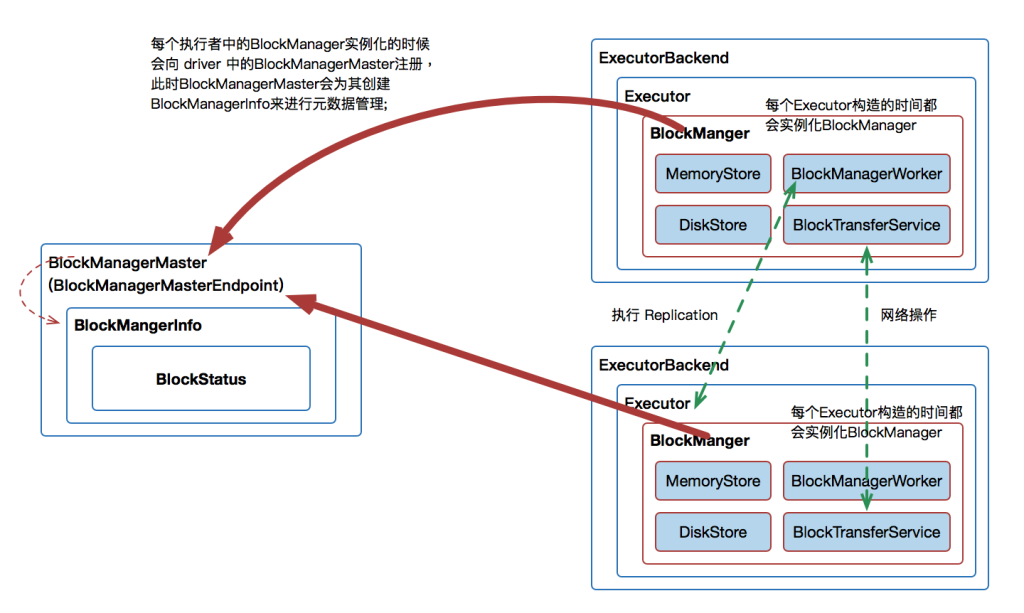
- 在 Application 启动的时候会在 SparkEnv 中注册 BlockMangerMaster。
- BlockManagerMaster:对整个集群的Block 数据进行管理;
- 每个启动一个 Executor 都会实例化 BlockManagerSlave 并通过远程通信的方式注册给 BlockMangerMaster;
- BlockManagerSlave由 4部分组成:
- MemoryStore:负责对内存上的数据进行存储和读写;
- DiskStore:负责对磁盘上的数据进行存储和读写;
- BlockTransferService:负责与远程其他Executor 的BlockManager建立网络连接;
- BlockManagerWorker:负责对远程其他Executor的BlockManager的数据进行读写;
- 当Executor 的BlockManager 执行了增删改操作,那就必须将 block 的 blockStatus 上报给Driver端的BlockManagerMaster,BlockManagerMaster 内部的BlockManagerMasterEndPoint 内维护了 元数据信息的映射。通过Map、Set结构,很容易维护 增加、更新、删除元数据,进而达到维护元数据的功能。
// 维护 BlockManagerId 与 BlockManagerInfo 的关系
// 而BlockManagerInfo内部维护 JHashMap[BlockId, BlockStatus] 的映射关系
private val blockManagerInfo = new mutable.HashMap[BlockManagerId, BlockManagerInfo]
// 维护 executorID 与 BlockManagerId 的关系
private val blockManagerIdByExecutor = new mutable.HashMap[String, BlockManagerId]
// 维护 BlockId 与 HashSet[BlockManagerId] 的关系, 因为数据块可能有副本
private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
HashMap[executorID, BlockManagerId]
HashMap[BlockManagerId, BlockManagerInfo]
JHashMap[BlockId, BlockStatus]
spark shuffle
对spark任务划分阶段,遇到宽依赖会断开,所以在stage 与 stage 之间会产生shuffle,大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。
负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。而随着Spark的版本的发展,ShuffleManager也在不断迭代。
ShuffleManager 大概有两个: HashShuffleManager 和 SortShuffleManager。
历史:
- 在spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager;
- 在spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager;
- 在spark 2.0以后,抛弃了 HashShuffleManager。
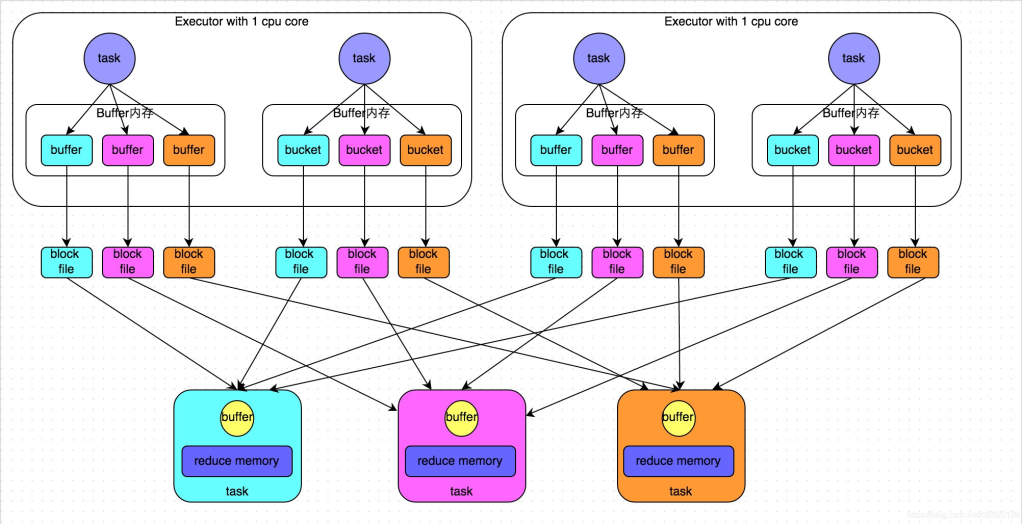
HashShuffleManager
优化前,spark 1.2以前:
上游 stage 有 2个 Executor,每个Executor 有 2 个 task。
下游 stage 有 3个task。
shuffle write阶段:
将相当于mapreduce的shuffle write,按照key的hash 分桶,写出中间文件。上游的每个task写自己的文件。中间文件个数 = maptask的个数 * reducetask的个数
假设上游 stage 有 10 个Executor,每个 Executor有 5 个task,下游stage 有 4 个task,写出的中间文件数 = (10 * 5) * 4 = 200 个,由此可见,shuffle write操作所产生的磁盘文件的数量是极其惊人的
shuffle read 阶段:
就相当于mapreduce 的 shuffle read, 每个reducetask 拉取自己的数据。
由于shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle write阶段占用大量的内存空间,会导致频繁的GC,容易导致OOM;也会产生大量的小文件,写入过程中会产生大量的磁盘IO,性能受到影响。适合小数据集的处理。
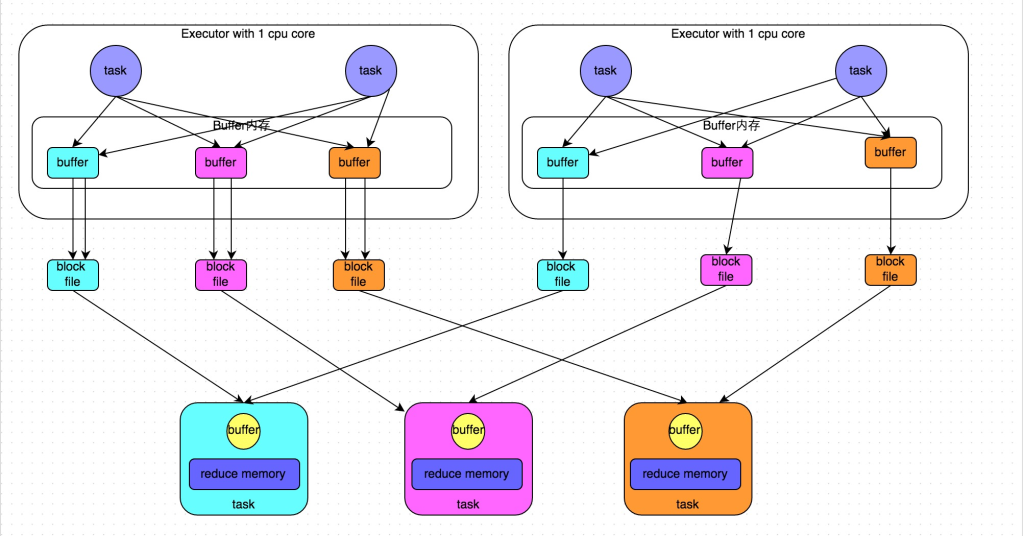
HashShuffleManager 优化
开启consolidate机制。设置参数:spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制。
conf.set("spark.shuffle.manager", "hash")
conf.set("spark.shuffle.consolidateFiles", "true")生成小文件的个数变成上游的CPU核数 * 下游task的个数。
优化后的HashShuffleManager,虽然比优化前减少了很多小文件,但在处理大量数据时,还是会产生很多的小文件。
SortShuffleManager
Spark在引入Sort-Based Shuffle以前,比较适用于中小规模的大数据处理。为了让Spark在更大规模的集群上更高性能处理更大规模的数据,于是就引入了SortShuffleManager。
SortShuffleManager不会为每个Reducer中的Task生成一个单独的文件,相反,会把上游中每个mapTask所有的输出数据Data只写到一个文件中。并使用了Index文件存储具体 mapTask 输出数据在该文件的位置。
因此 上游 中的每一个mapTask中产生两个文件:Data文件 和 Index 文件,其中Data文件是存储当前Task的Shuffle输出的,而Index文件中存储了data文件中的数据通过partitioner的分类索引。
写出文件数 = maptask的个数 * 2 (index 和 data )
SortShuffle 的产生的中间文件的多少与 上个stage 的 maptask 数量有关。
shuffle read 阶段:
下游的Stage中的Task就是根据这个Index文件获取自己所要抓取的上游Stage中的mapShuffleMapTask产生的数据的;
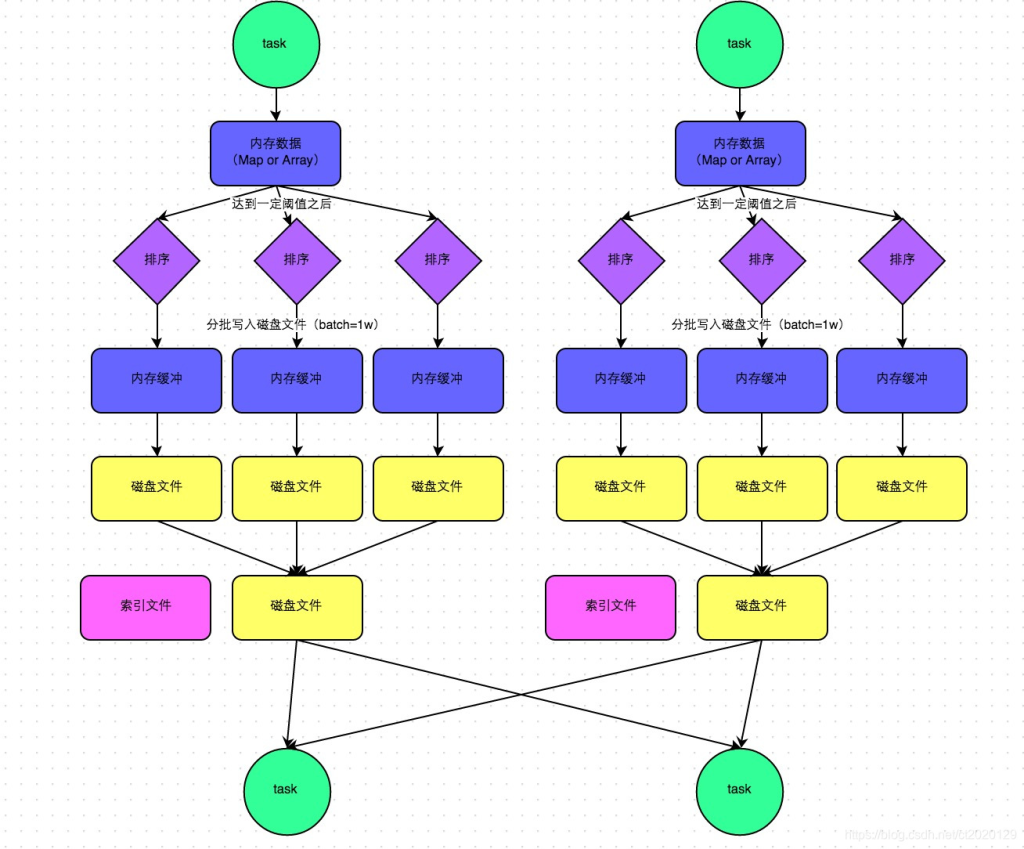
bypass机制(不排序机制)
此时task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
触发bypass机制的条件:
shuffle map task的数量小于(上游分区rdd个数)spark.shuffle.sort.bypassMergeThreshold参数的值(默认200)或者不是聚合类的shuffle算子(比如groupByKey)
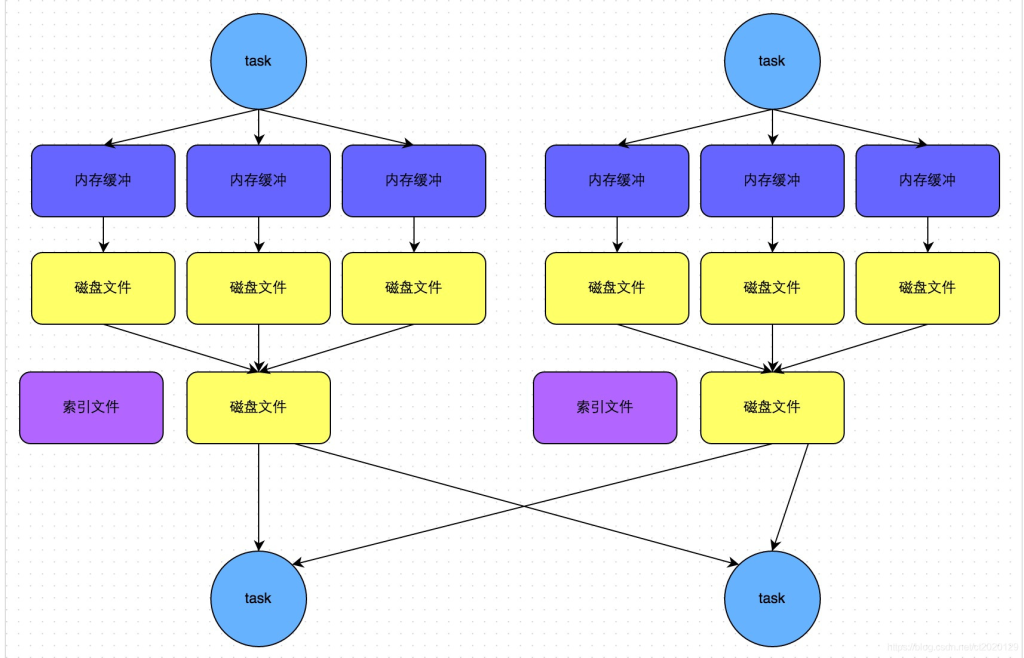
bypass机制与普通SortShuffleManager运行机制的不同在于:
第一,磁盘写机制不同; 第二,不会进行排序。 也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
spark mapjoin 练习
spark 使用的pom
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.scope>compile</project.build.scope>
<!-- scope关键字是jar包的一个作用域,provided编译时候可以使用,运行和打包不行
runtime编译时候可以使用,运行可以使用,打包不行
compile编译,运行,打包-->
<spark.version>3.1.2</spark.version>
<!-- <project.build.scope>provided</project.build.scope>-->
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- spark 操作 hbase用到的-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- <dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-cli</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
</exclusion>
</exclusions>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<!-- sparkSQL编程-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- sparkSQL-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.spark-project.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<scope>compile</scope>
<version>1.2.1.spark2</version>
</dependency>
<!-- 访问spark thriftserver 用的-->
<!-- <dependency>-->
<!-- <groupId>org.apache.hive</groupId>-->
<!-- <artifactId>hive-jdbc</artifactId>-->
<!-- <exclusions>-->
<!-- <exclusion>-->
<!-- <groupId>org.apache.hive</groupId>-->
<!-- <artifactId>hive-exec</artifactId>-->
<!-- </exclusion>-->
<!-- </exclusions>-->
<!-- <version>3.1.2</version>-->
<!-- <scope>${project.build.scope}</scope>-->
<!-- </dependency>-->
<!-- sparkStreaming直连kafka操作-->
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.10.2.2</version>
<scope>${project.build.scope}</scope>
<exclusions>
<exclusion>
<artifactId>kafka-clients</artifactId>
<groupId>org.apache.kafka</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- sparkStreaming操作-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>5.6.11</version>
<exclusions>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>pentaho-aggdesigner-algorithm</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</exclusion>
<exclusion>
<groupId>cascading</groupId>
<artifactId>cascading-hadoop</artifactId>
</exclusion>
<exclusion>
<groupId>cascading</groupId>
<artifactId>cascading-local</artifactId>
</exclusion>
</exclusions>
<!-- -Xms256m -Xmx512m -Xss10m
-->
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.9.2</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>JsoupXpath</artifactId>
<version>0.3.2</version>
<scope>compile</scope>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<directory>src/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptors>
<descriptor>src/resources/assembly.xml</descriptor>
</descriptors>
<!-- <archive>-->
<!-- <manifest>-->
<!-- <mainClass>${package.main.class}</mainClass>-->
<!-- </manifest>-->
<!-- </archive>-->
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12</version>
<configuration>
<skip>true</skip>
<forkMode>once</forkMode>
<excludes>
<exclude>**/**</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>读取orc工具类
package com.lmk;
import org.apache.hadoop.hive.ql.io.orc.OrcSerde;
import org.apache.hadoop.hive.ql.io.orc.OrcStruct;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils;
import org.apache.hadoop.io.Writable;
import java.util.ArrayList;
import java.util.List;
/**
* orcUtil工具类, 读写orc文件
* 应用步骤:<br/>
* 读orc:<br/>
* setOrcTypeReadSchema()<br/>
* getOrcData()<br/>
*
* 写orc:<br/>
* setOrcTypeWriteSchema()<br/>
* addAttr()<br/>
* serialize()<br/>
*
* @Date 2019年6月5日
*/
public class OrcUtil {
/**
* 读取orc文件的inspector对象
*/
StructObjectInspector inspectorR = null;
/**
* 写orc文件的inspector对象
*/
StructObjectInspector inspectorW = null;
/**
* 存储一行的数据
*/
List<Object> realRow = null;
/**
* orc文件序列化对象
*/
OrcSerde serde = null;
/**
* 设置读orc的inspector对象
*/
public void setOrcTypeReadSchema(String schema){
// 根据orc文件的结构,获取对应的typeinfo对象
TypeInfo typeinfo = TypeInfoUtils.getTypeInfoFromTypeString(schema);
// 通过typeinfo对象获取具体的inspector对象
inspectorR = (StructObjectInspector) OrcStruct.createObjectInspector(typeinfo);
}
/**
* 设置写orc的inspector对象
*/
public void setOrcTypeWriteSchema(String schema){
// 根据orc文件的结构,获取对应的typeinfo对象
TypeInfo typeinfo = TypeInfoUtils.getTypeInfoFromTypeString(schema);
// 根据typeinfo 获取写orc文件的inspector对象
inspectorW = (StructObjectInspector) TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(typeinfo);
}
/**
* 获取指定orc格式文件字段的值
* @param orcStruct orc文件数据
* @param filedName 字段名称
* @return 指定字段的值
*/
public String getOrcData(OrcStruct orcStruct, String filedName){
// 根据字段名称,获取对应的 StructField对象
StructField fieldRef = inspectorR.getStructFieldRef(filedName);
// 通过 对应的 StructField对象,从orcData 里面,取出 对应字段的值
Object obj = inspectorR.getStructFieldData(orcStruct, fieldRef);
String filedData = null;
if (obj != null) {
filedData = String.valueOf(obj);
filedData = "".equals(filedData) || "null".equals(filedData) ? null : filedData;
}
return filedData;
}
/**
* 写orc时,添加要写入orc文件的字段可变数组
* @param objs 可变数组
* @return
*/
public OrcUtil addAttr(Object... objs){
if(realRow == null){
realRow = new ArrayList<Object>();
}
for(Object obj : objs){
realRow.add(obj);
}
return this;
}
/**
* 将 这一行的数据 序列化成 orc文件格式
*/
public Writable serialize() {
// 每次new新的
serde = new OrcSerde();
Writable w = serde.serialize(realRow, inspectorW);
// 序列化后重新创建接收数据的列表对象
realRow = new ArrayList<Object>();
return w;
}
}
代码实现
package com.lmk.spark
import com.lmk.OrcUtil
import org.apache.hadoop.hive.ql.io.orc.{OrcNewInputFormat, OrcStruct}
import org.apache.hadoop.io.NullWritable
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* file1
* broadcast(file1) smill data
* file2
* join file1 in any executor
* 1. 读取表的orc文件
* 2. mapjoin
*/
object MapJoinTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("MapJoinTest")
val sc = new SparkContext(conf)
val map: Map[String, String] = sc.textFile("data/sku_info.txt")
.map(x => {
val strs = x.split("\t")
(strs(0), strs(1))
}).collect().toMap
// 广播变量
// 1. 不能广播RDD,必须收回数据才能广播除去
// 2. 广播的数据必须序列化才可以传输
val bs = sc.broadcast(map)
// mr --> longWritable value --> text
// mr --> textInputFormat
// mr --> ORCInputFormat
// mr --> InputFormat --> FileInputFormat 这里的实现就是上面的textInputFormat和ORCInputFormat
// spark没有自己的读取方式,使用mr原生的InputFormat
val rdd: RDD[(NullWritable, OrcStruct)] = sc.newAPIHadoopFile[NullWritable, OrcStruct, OrcNewInputFormat]("data/order_detail_orc.orc", classOf[OrcNewInputFormat], classOf[NullWritable], classOf[OrcStruct])
rdd.map(_._2).mapPartitions(it => {
// 每个partition 公用一个util和广播变量,比map高效
val util = new OrcUtil
util.setOrcTypeReadSchema("struct<order_detail_id:string,order_id:string,sku_id:string,create_date:string,price:string,sku_num:string>")
val map = bs.value
it.map(x => {
val order_detail_id = util.getOrcData(x, "order_detail_id")
val order_id = util.getOrcData(x, "order_id")
val sku_id = util.getOrcData(x, "sku_id")
val create_date = util.getOrcData(x, "create_date")
val price = util.getOrcData(x, "price")
val sku_num = util.getOrcData(x, "sku_num")
val sku_name = map.getOrElse(sku_id, "unknow")
(order_detail_id, order_id, sku_name, create_date, price, sku_num)
})
}).foreach(println)
}
}
运行结果
可以看到将id替换成了名称
输出文件格式ORC和SNAPPY压缩
// foreach 换掉
}).mapPartitions(it => {
val util = new OrcUtil
util.setOrcTypeWriteSchema("struct<order_detail_id:string,order_id:string,sku_name:string,create_date:string,price:string,sku_num:string>")
it.map(x => {
util.addAttr(x._1, x._2, x._3, x._4, x._5, x._6)
val writable = util.serialize()
(NullWritable.get(), writable)
})
})
// 配置snappy压缩
val config = new Configuration()
config.set(CompressionKind.SNAPPY.name(), classOf[SnappyCodec].getName)
// 如果文件存在会报错
rdd2.saveAsNewAPIHadoopFile("data/res", classOf[NullWritable], classOf[Writable], classOf[OrcNewOutputFormat],config)隐式转换删除存在文件
package com.lmk.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
object Utils {
implicit def stingUtils(path: String): StingUtils = new StingUtils(path)
}
class StingUtils(path: String) {
def delete = {
val config = new Configuration()
// getLocal 加上就是操作本地的,不加就操作hdfs
val fs = FileSystem.getLocal(config)
if (fs.exists(new Path(path))) {
fs.delete(new Path(path), true)
}
}
}调用隐式转换
val outputPath = "data/res"
outputPath.delete短命令实现
当我们在命令行中执行脚本的时候,一般需要先打个jar包。然后使用以下语句
spark-submit
--master
--executor-memory
--executor-cores
--total-executor-cores
# 指定类来运行
--class com.lmk.spark.mapjoin
spark.jar
inpath outpath短命令就是使用main_class 指向要使用的类,这样默认就知道要执行指定的类。
修改MapJoinTest,并在上面添加class MapJoinTest
解注,并修改pom中下面的部分
<archive>
<manifest>
<mainClass>com.lmk.spark.Start</mainClass>
</manifest>
</archive>start代码如下:
package com.lmk.spark
import org.apache.hadoop.util.ProgramDriver
// 执行spark-submit **.jar mjt 不用指定--class 默认启动Start
object Start {
def main(args: Array[String]): Unit = {
val driver = new ProgramDriver
driver.addClass("mjt", classOf[MapJoinTest], "This is map join with broadcast var")
// ..可以加其他类
driver.run(args)
}
}spark序列化
由于大多数Spark计算的内存性质,Spark程序可能会受到集群中任何资源(CPU,网络带宽或内存)的瓶颈。通常,如果内存资源足够,则瓶颈是网络带宽。
数据序列化,这对于良好的网络性能至关重要。
在Spark的架构中,在网络中传递的或者缓存在内存、硬盘中的对象需要进行序列化操作。比如:
- 分发给Executor上的Task
- 广播变量
- Shuffle过程中的数据缓存
等操作,序列化起到了重要的作用,将对象序列化为慢速格式或占用大量字节的格式将大大减慢计算速度。通常,这是优化Spark应用程序的第一件事。
spark 序列化分两种:一种是Java 序列化; 另一种是 Kryo 序列化。
JAVA序列化
定义UserInfo类
package com.lmk;
import org.apache.hadoop.io.Text;
import java.io.Serializable;
/**
* 想要序列化两种方式
* java 好用直接 implements Serializable,但是性能不高,而且如果内部有hadoop的类型,是不能序列化的
* spark kryo
*/
public class UserInfo implements Serializable {
private String name = "lmk"; // java实现了序列化
private int age = 10; // java实现了序列化
// transient 就是不序列化
// static修饰的是类的状态,而不是对象状态,所以不存在序列化问题;
static private Text addr = new Text("beijing"); // 没有实现java的 Serializable接口
public UserInfo() {
}
@Override
public String toString() {
return "UserInfo{" +
"name='" + name + '\'' +
", age=" + age +
", addr=" + addr +
'}';
}
}package com.lmk.spark
import com.lmk.UserInfo
import org.apache.spark.{SparkConf, SparkContext}
object TestSeria {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestSeria")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val arr = Array(1,2,3,4,5,6,7,8,9)
val rdd = sc.makeRDD(arr, 3)
val user = new UserInfo
val bs = sc.broadcast(user)
rdd.map(x => (x, bs.value)).groupByKey().collect().foreach(println)
}
}java 序列化弊端
- 如果引入第三方类对象作为属性,如果对象没有实现序列化,那这个类也不能序列化;
- 用 transient 修饰 的属性,反序列化后数据丢失;
- Java序列化很灵活(支持所有对象的序列化)但性能较差,同时序列化后占用的字节数也较多(包含了序列化版本号、类名等信息)。
Kryo 序列化
Spark 也推荐用 Kryo序列化机制。Kryo序列化机制比Java序列化机制性能提高10倍左右,Spark之所以没有默认使用Kryo作为序列化类库,是因为它不支持所有对象的序列化,同时Kryo需要用户在使用前注册需要序列化的类型,不够方便。
开启序列化
spark 默认序列化方式 是 用java序列化
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// classOf[KryoSerializer].getName 一样效果
// 这样配置相当于所有的序列化类都加载配置序列化参数
当开启序列化后,需要配置 【spark.kryo.registrationRequired】属性为true,默认是false,如果是false,Kryo序列化时性能有所下降。
方式1
// 开启Kryo序列化
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 要求主动注册
conf.set("spark.kryo.registrationRequired", "true")
// 方案1:
val classes: Array[Class[_]] = Array[Class[_]](
classOf[UserInfo],
classOf[Text],
Class.forName("scala.reflect.ClassTag$GenericClassTag"),
classOf[Array[UserInfo]]
)
//将上面的类注册
conf.registerKryoClasses(classes)方式2
封装一个自定义注册类,然后把自定义注册类注册给Kryo。
自定义注册类
class MyRegistrator extends KryoRegistrator {
override def registerClasses(kryo: Kryo): Unit = {
kryo.register(classOf[UserInfo])
kryo.register(classOf[Text])
kryo.register(Class.forName("scala.reflect.ClassTag$GenericClassTag"))
kryo.register(classOf[Array[UserInfo]])
}
}配置自定义注册类
// 开启Kryo序列化
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 要求主动注册
conf.set("spark.kryo.registrationRequired", "true")
// 设置注册类
conf.set("spark.kryo.registrator",classOf[MyRegistrator].getName)GC对spark性能的影响分析
垃圾收集 Garbage Collection 通常被称为“GC”,回收没用的对象以释放空间。
GC 主要回收的是虚拟机堆内存的空间,因为new 的对象主要是在堆内存。
垃圾收集的算法
标记-清除算法
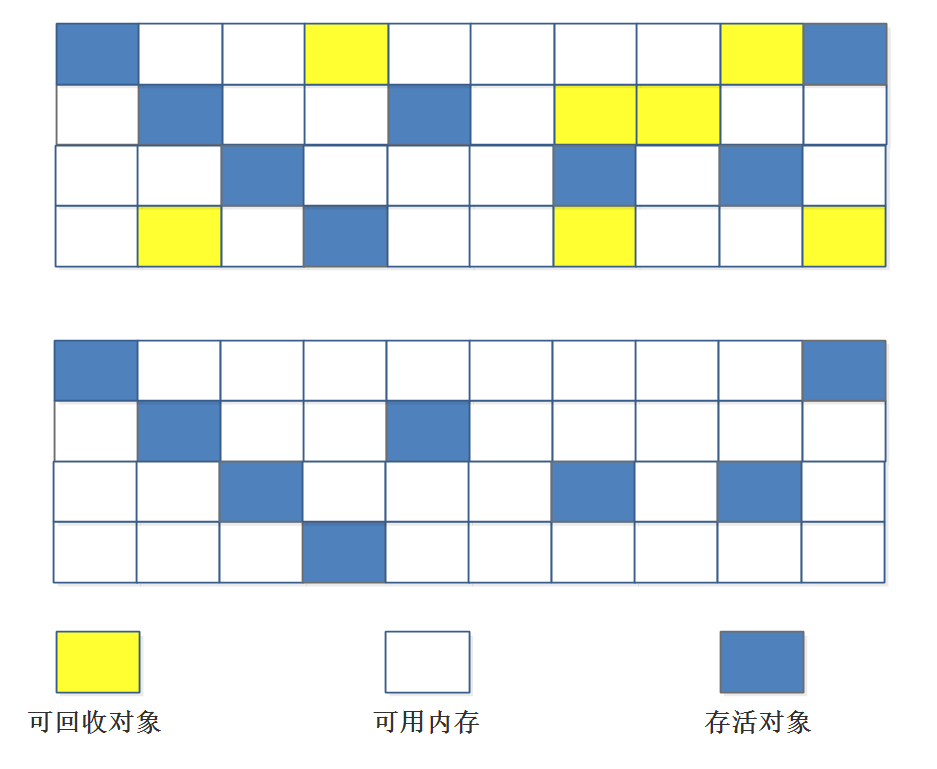
“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。之所以说它是最基础的收集算法,是因为后续的收集算法都是基于这种思路并对其缺点进行改进而得到的。
它的主要缺点有两个:一个是效率问题,标记和清除过程的效率都不高;另外一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
复制算法
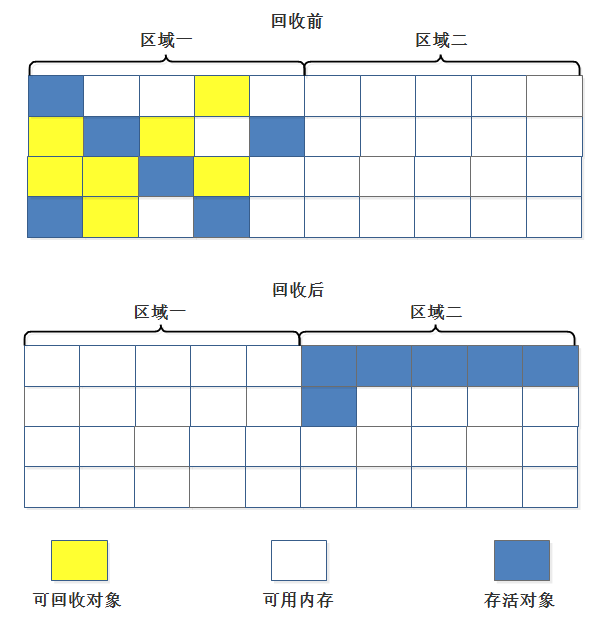
“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
这样使得每次都是对其中的一块进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,缺点:这种算法持续复制长生存期的对象则导致效率降低。
标记-整理算法
复制收集算法在对象存活率较高时就要执行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
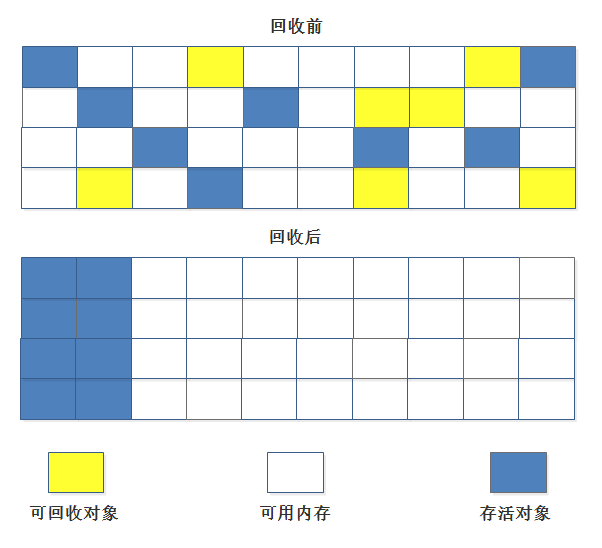
分代收集算法
GC分代的基本假设:绝大部分对象的生命周期都非常短暂,存活时间短。
“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或“标记-整理”算法来进行回收。
JVM的minor gc与full gc
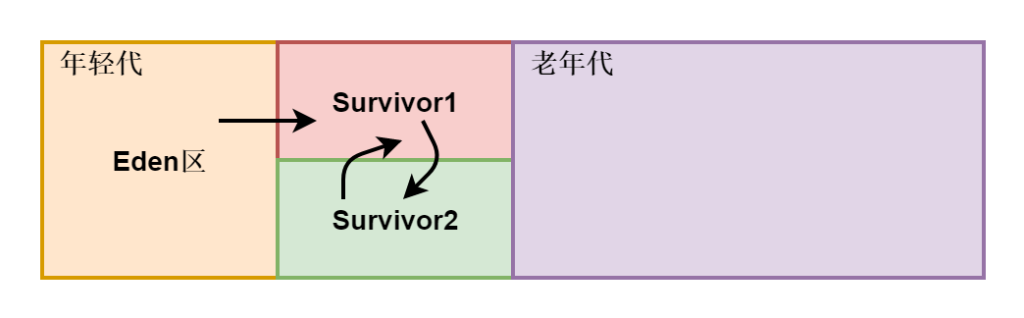
- 年轻代:存放岁数比较年轻的对象。分为 Eden区 和 Survivor区。
- Eden区:开始对象分配的地方;
- Survivor区:是经过minor gc 后存活对象的存储区域,一般这个区域要比Eden区小。分为两个区:from 和 to。
- 老年代:存放存活时间长的对象和年轻代存不下的对象,这个区域要比年轻代大的多。
对象分配
一般对象分配:当有新对象产生时,JVM会把对象分配到Eden区,Survivor区作为备用;
大对象分配:大对象是指需要连续空间的java对象,如很长的数组、字符串。这样的大对象不会分配在年轻代,直接进入老年代。
minor gc(年轻代 gc)
minor gc 是指 年轻代的垃圾收集动作。因为年轻代中的对象基本都是朝生夕死的(80%以上),所以Minor gc 会非常频繁,回收速度也比较快。
触发条件:Eden区满了。
操作方法:
- 第一次minor gc,通过复制算法,将Eden区存活的对象复制到 Survivor from 区,对象年龄设为1;
- 以后的minor gc,通过复制算法,将Eden区 和 Survivor from 区 存活的对象 复制到 Survivor to 区,然后 再将 to 区 变成新的 from 区,同时对象的年龄+1,一旦某个对象达到了指定的次数,就会把该对象移到老年代。
full gc(老年代 gc)
full gc 是指 老年代的垃圾收集动作。因为老年代中的对象大多是存活时间长的对象,老年代回收要用 标记整理或标记清除算法,回收速度很慢。
触发条件:老年代满了。
操作方法:通过标记整理或标记清除算法,扫描老年代的每个对象,并回收不可达的对象。
频繁GC的影响及优化方法
task运行期间动态创建的对象使用的Jvm堆内存的情况

给spark任务分配的内存少了,会频繁发生minor gc,如果存活时间长的对象特别多,就会发生full gc。
当频繁的new对象时,导致很快进入老年代,这样也可能发生full gc。
频繁gc 会影响 工作任务线程的正常执行,从而降低spark 应用程序的性能。
优化方案
- 优化代码,避免频繁new 同一个对象,导致的频繁gc。
- 调节可用存储内存和执行内存的比例,以减少gc 发生的频率。
- 对应存储内存,可以考虑存储序列化后的对象,调节序列化级别为MEMORY_DISK_SER或MEMORY_ONLY_SER,这样占用内存空间小。
- 还可以使用Kryo序列化类库,进行序列化,因为kryo序列化方法可以进一步的降低RDD的parition的内存占用量。