
yarn概述
诞生背景
早期hadoop1.x版本中的时候是没有yarn这个组件的,只有hdfs和mapreduce
hdfs负责数据分布式存储,mapreduce负责数据分布式计算,但是也限制了对于数据计算只能用mapreduce,扩展性不好。在hadoop2.0中引入了yarn
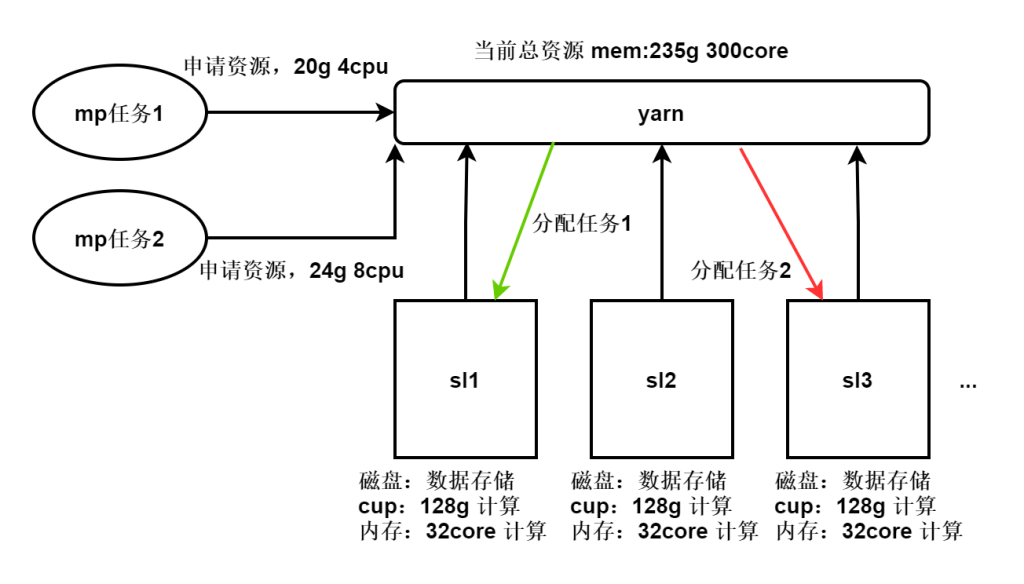
yarn是一个资源调度平台,负责为运算程序提供服务器计算资源,MR就是运行在其上的。
yarn架构
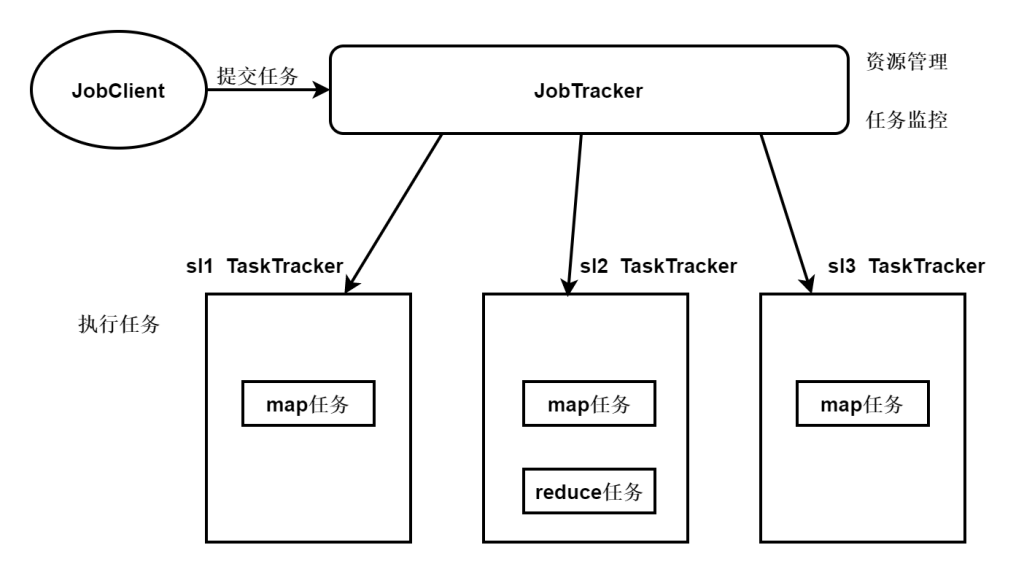
MR1 架构
JobClient
主要负责提交任务,提交给JobTracker。用户编写的 MapReduce 程序通过 JobClient 提交给 JobTracker。
JobTracker
主要负责资源管理和任务监控,并且监控所有TaskTracker与作业的健康情况,一旦有失败情况发生,就会将相应的任务分配到其他结点上去执行。
TaskTracker
会周期性地将本结点的资源使用情况和任务进度汇报给 JobTracker,与此同时会接收 JobTracker 发送过来的命令并执行操作。
Task
分为 Map Task 和 Reduce Task两种,由 TaskTracker 启动,分别执行 Map 和 Reduce 任务。一般来讲,每个结点可以运行多个 Map 和 Reduce 任务。
MR1 框架不足
- JobTracker是集群事务的集中处理点,存在单点故障。
- JobTracker 即要做资源管理,又要做任务调度。导致JobTracker任务多时内存开销大,集群上限4000节点。
- 不支持其他计算框架。
YARN架构
yarn 也是 master/ slave 结构。
yarn 主要由ResourceManager、NodeManager等几个组件构成。
YARN通过将资源管理和应用程序管理两部分分剥离开,分别由ResouceManager和ApplicationMaster负责。
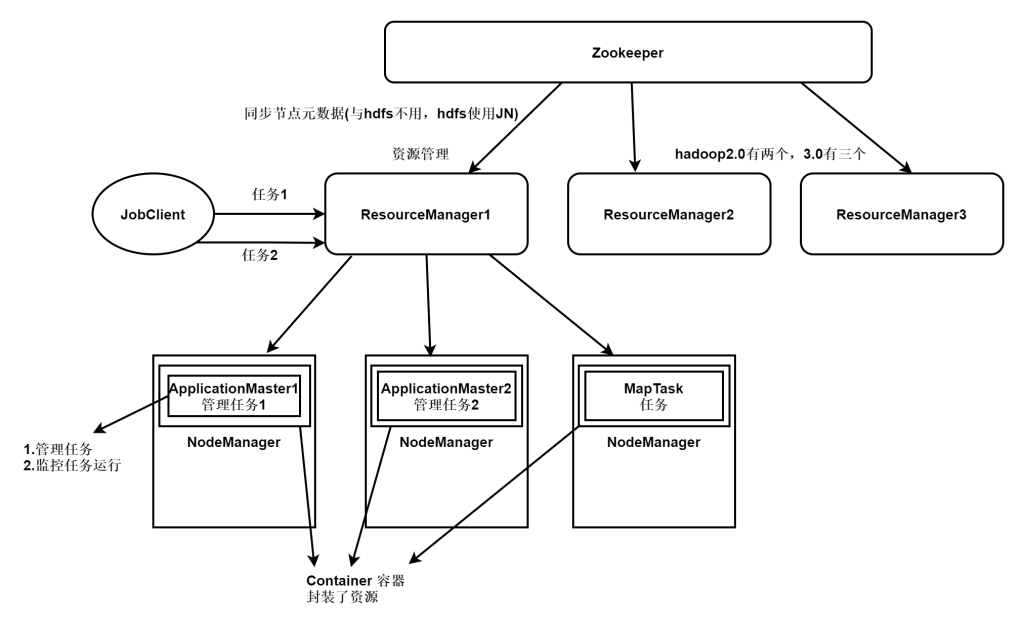
ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。
它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM),通俗讲是用于管理NodeManager节点的资源,包括cpu、内存等。
ApplicationMaster(AM)
ApplicationMaster 管理在YARN内运行的每个应用程序实例。
每个应用程序对应一个ApplicationMaster。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配),通俗讲是管理发起的任务,随着任务创建而创建,任务的完成而结束。
NodeManager(NM)
NM是每个节点上的资源和任务管理器。
一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
搭建resourcemanager
yarn-env.sh
设置内存占比,yarn的内存为256M
source /etc/profile
JAVA=$JAVA_HOME/bin/java
JAVA_HEAP_MAX=-Xmx256m
YARN_HEAPSIZE=256
export YARN_RESOURCEMANAGER_HEAPSIZE=256yarn-site.xml
<!-- RM1 configs start -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>nn1:8032</value>
<description>ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>nn1</value>
<description>ResourceManager主机名</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>nn1:8030</value>
<description>ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>nn1:8089</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>nn1:8088</value>
<description>ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>nn1:8031</value>
<description>ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>nn1:8033</value>
<description>ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等</description>
</property>
<!-- RM1 configs end -->
<!-- RM2 configs start -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>nn2:8032</value>
<description>ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>nn2</value>
<description>ResourceManager主机名</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>nn2:8030</value>
<description>ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资>源等。</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>nn2:8089</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>nn2:8088</value>
<description>ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>nn2:8031</value>
<description>ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>nn2:8033</value>
<description>ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等</description>
</property>
<!-- RM2 configs end -->
<!-- RM3 configs start -->
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>nn3:8032</value>
<description>ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>nn3</value>
<description>ResourceManager主机名</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>nn3:8030</value>
<description>ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm3</name>
<value>nn3:8089</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>nn3:8088</value>
<description>ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>nn3:8031</value>
<description>ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm3</name>
<value>nn3:8033</value>
<description>ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等</description>
</property>分发配置文件到每个机器中,在nn1、nn2和nn3上启动resourceManager
yarn-daemon.sh start resourcemanager三台resourceManager启动之后,使用浏览器进入nn1:8088,所有的resourceManager都是active状态,说明active没有人进行选举。
配置resourceManager的HA
yarn-site.xml
<!-- yarn ha start -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>是否开启yarn ha</description>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
<description>ha状态切换为自动切换</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
<description>RMs的逻辑id列表</description>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>nn1:2181,nn2:2181,nn3:2181</value>
<description>ha状态的存储地址</description>
</property>
<!-- yarn ha end -->
<!-- 元数据存储共享 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>pseudo-yarn-rm-cluster</value>
<description>集群的Id</description>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
<description>默认值为false,也就是说resourcemanager挂了相应的正在运行的任务在rm恢复后不能重新启动</description>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
<description>配置RM状态信息存储方式3有两种,一种是FileSystemRMStateStore,另一种是MemoryRMStateStore,还有一种目前较为主流的是zkstore</description>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>nn1:2181,nn2:2181,nn3:2181</value>
<description>当使用ZK存储时,指定在ZK上的存储地址。</description>
</property>
<!-- 元数据存储共享 -->将修改后的文件分发到其他服务器
在nn1、nn2和nn3上重启resourceManager
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh start resourcemanager重启之后查看zookeeper,可以发现多了两个节点

搭建Nodemanager
三台resourcemanager启动成功,但是没有工作节点
yarn-site.xml
<!-- nodeManager基础配置 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/yarn/local</value>
<description>中间结果存放位置,存放执行Container所需的数据如可执行程序或jar包,配置文件等和运行过程中产生的临时数据</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/yarn/logs</value>
<description>Container运行日志存放地址(可配置多个目录)</description>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:9103</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序</description>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:8042</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:8040</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!-- nodeManager基础配置 -->将修改好的文件进行分发,启动三个机器的所有nodemanager
yarn --workers --daemon start nodemanagernodemanager默认会和datanode启动到一台节点,也就是workers文件中配置的服务器
这是nodemanager的节点资源情况需要按照实际服务器资源进行配置
资源规划:
- nodemanager最多在s1申请内存 1.5,nodemanager最多在nn2申请内存 1.5G,nodemanager最多在nn3申请内存 1.5G 共计4.5G
- nodemanager最多在s1申请cpu 1核,nodemanager最多在nn2申请cpu 1核,nodemanager最多在nn1申请cpu 1核
- 共计3核,但是一个cpu是可以同时运行多个任务的,所以在hadoop中可以将一个物理cpu和分成多个虚拟cpu,暂定为pcore:vcore=1:3 即一个物理cpu核=3个虚拟cpu核 共计9个vcore
yarn-site.xml
<!-- nodeMananger资源限定 start -->
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
<description>单个任务可申请的最小虚拟CPU个数</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>3</value>
<description>单个任务可申请的最大虚拟CPU个数,此参数对应yarn.nodemanager.resource.cpu-vcores,建议最大为一个物理CPU的数量</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1024</value>
<description>单个任务可申请的最多物理内存量</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>3</value>
<description>该节点上YARN可使用的虚拟CPU个数,一个物理CPU对应3个虚拟CPU</description>
</property>
<!-- 重要开始 end -->
<!-- 关闭内存检测 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>虚拟内存检测,默认是True</description>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
<description>物理内存检测,默认是True</description>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/share/hadoop/common/*,
$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
$HADOOP_COMMON_HOME/share/hadoop/hdfs/*,
$HADOOP_COMMON_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_COMMON_HOME/share/hadoop/mapreduce/*,
$HADOOP_COMMON_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_COMMON_HOME/share/hadoop/yarn/*,
$HADOOP_COMMON_HOME/share/hadoop/yarn/lib/*
</value>
</property>
<!-- nodeMananger资源限定 start -->配置完分发文件,重启整个yarn集群。
stop-yarn.sh
start-yarn.sh
#hadoop集群整体启动
start-all.sh
#停止
stop-all.sh实际在公司需要留一部分资源给系统和其他组件,不会全部都占
假设一台服务器,内存128G,16个pcore,需要安装DataNode和NodeManager, 具体如何设置参数?
- 装完CentOS,消耗内存1G
- 系统预留20%,防止全部使用导致系统夯住或者OOM机制事件, 或者给未来部署其他组件预留空间。此时余下128*80%=102G
- DataNode设定2G,NodeManager设定4G,则剩余102-2-4=96G
资源调度器
假设很多部门都在用yarn框架作为资源调度,那么yarn的资源怎么进行合理的分配
调度器种类
- 先进先出调度器(FIFO)
- 容量调度器(默认)(Capacity Scheduler)
- 公平调度器(Fair Scheduler)
在hadoop3.x版本中默认调度器是容量调度器,CDH版本中调度器是公平调度器
FIFO调度器
这个策略没啥好讲的,提交一个任务进入队列,调度器根据优先级和到达先后进行排序,一次给每一个应用分配资源,直到没有资源为止。没有人会在生产环境用这个策略,性能太差了。
- 优点
- 简单,直接就可以用,不需要额外的配置。早些版本的yarn用FIFO作为默认调度策略,较新版本的yarn用Capacity作为默认调度策略。
- 缺点
- 小应用可能被饿死。大应用进入队列后占用了大量的资源,小应用迟迟得不到资源就卡住了
- 低优先级的任务可能被饿死。当队列内的资源没有剩余时,如果不断有优先级高的任务进入,低优先级的任务不断被往后挤,永远得不到资源
容量调度器
很机智的策略,为了让小任务也能够调度得到资源,划分了多个队列,每个队列内部仍然是FIFO,但是因为划分了不同的资源区,所以可以将小任务提交到资源较少的队列,将大任务提交到资源较多的队列中。
但是这样也可能带来资源的浪费,所以可以配置弹性资源,capacity策略允许队列在空闲时将资源提供给其他队列使用,以此提高资源利用率。
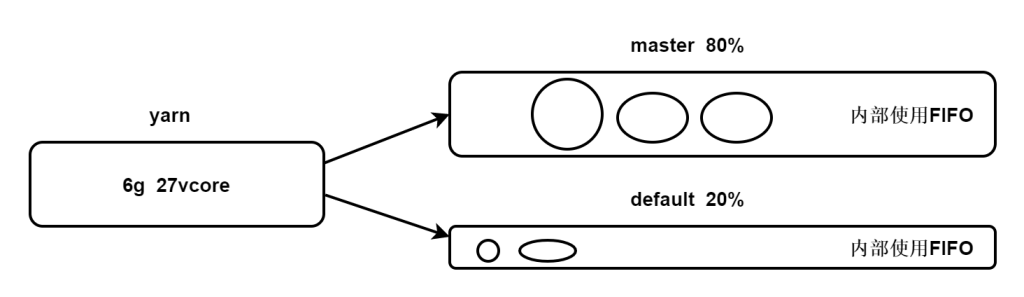
capacity-scheduler.xml
<!--配置root队列下两个子队列 master占比80 default占比20-->
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>master,default</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.master.capacity</name>
<value>80</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>20</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.master.maximum-capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
</property>
</configuration>配置完成后进行分发,重启yarn。
提交任务到default队列
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount -Dmapreduce.job.queuename=default /word/words.txt /wcresult1配置队列中任务优先级,优先级根据数字从大到小,如下面5最大。
yarn-site.xml
<property>
<name>yarn.cluster.max-application-priority</name>
<value>5</value>
</property>分发文件并重启
提交任务运行时,发现优先级越高的任务会越早分配资源。
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi -Dmapreduce.job.queuename=master -Dmapreduce.job.priority=5 5 2000000公平调度器
公平调度器是由facebook发明的,原理和容量调度器差不多,但是单个队列中的任务是可以并行执行的 所以公司中使用公平调度器的方式最多
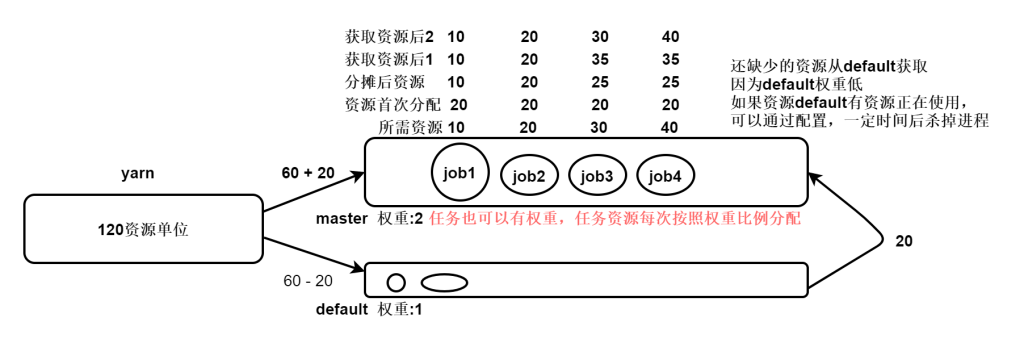
yarn-site.xml
<!-- scheduler begin -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>调度器实现类</description>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>fair-scheduler.xml</value>
<description>自定义XML配置文件所在位置,该文件主要用于描述各个队列的属性,比如资源量、权重等</description>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
<description>是否支持抢占</description>
</property>
<property>
<name>yarn.scheduler.fair.sizebasedweight</name>
<value>false</value>
<description>在一个队列内部分配资源时,默认情况下,采用公平轮询的方法将资源分配各各个应用程序,而该参数则提供了外一种资源分配方式:按照应用程序资源需求数目分配资源,即需求资源数量越多,分配的资源越多。默认情况下,该参数值为false</description>
</property>
<property>
<name>yarn.scheduler.increment-allocation-mb</name>
<value>256</value>
<description>内存规整化单位,默认是1024,这意味着,如果一个Container请求资源是700mB,则将被调度器规整化为 (700mB / 256mb) * 256mb=768mb</description>
</property>
<property>
<name>yarn.scheduler.assignmultiple</name>
<value>true</value>
<description>是否启动批量分配功能。当一个节点出现大量资源时,可以一次分配完成,也可以多次分配完成。默认情况下,参数值为false</description>
</property>
<property>
<name>yarn.scheduler.fair.max.assign</name>
<value>10</value>
<description>如果开启批量分配功能,可指定一次分配的container数目。默认情况下,该参数值为-1,表示不限制</description>
</property>
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
<description>如果提交的队列名不存在,Scheduler会自动创建一个该队列,默认开启</description>
</property>
<!-- scheduler end -->新增fair-scheduler.xml
<?xml version="1.0"?>
<allocations>
<queue name="master">
<minResources>512 mb,1 vcores</minResources>
<maxResources>6140 mb,3 vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<weight>2.0</weight>
<schedulingPolicy>fair</schedulingPolicy>
<!--可向队列中提交应用程序的用户或用户组列表,默认情况下为“*”,表示任何用户均可以向该队列提交应用程序。-->
<aclSubmitApps>master</aclSubmitApps>
<!--一个队列的管理员可管理该队列中的资源和应用程序,比如可杀死任意应用程序-->
<aclAdministerApps>master</aclAdministerApps>
</queue>
<queue name="default">
<weight>1.0</weight>
<aclSubmitApps>*</aclSubmitApps>
<aclAdministerApps>*</aclAdministerApps>
</queue>
<!-- user节点只有一个子节点 -->
<user name="root">
<aclSubmitApps>*</aclSubmitApps>
<aclAdministerApps>*</aclAdministerApps>
<maxRunningApps>10</maxRunningApps>
</user>
<!-- 用户的maxRunningJobs属性的默认值 -->
<userMaxAppsDefault>50</userMaxAppsDefault>
<!-- 队列的schedulingMode属性的默认值 默认是fair-->
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<!-- 如果一个队列在该段时间内使用的资源量低于fair共享资源量,则开始抢占其他队列的资源。-->
<fairSharePreemptionTimeout>60</fairSharePreemptionTimeout>
<!-- 如果一个队列在该段时间内使用的资源量低于最小共享资源量,则开始抢占其他队列的资源。 -->
<defaultMinSharePreemptionTimeout>60</defaultMinSharePreemptionTimeout>
<queuePlacementPolicy>
<rule name="specified" create="false" />
<rule name="user" create="false" />
<rule name="reject" />
</queuePlacementPolicy>
</allocations>分发文件重启yarn
提交任务到yarn
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount /word/words.txt /wcres将任务提交到指定队列
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount -Dmapreduce.job.queuename=master /word/words.txt /wcres任务提交流程
ResourceManager(RM),resourcescheduler(资源调度器) + applicationmanager
ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM),通俗讲是用于管理NodeManager节点的资源,包括cup、内存等。
Scheduler(调度器)
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序;在资源紧张的情况下,可以kill掉优先级低的,来运行优先级高的任务。
Applications Manager(应用程序管理器)
负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
ApplicationMaster(AM)
ApplicationMaster 管理在YARN内运行的每个应用程序实例。每个应用程序对应一个ApplicationMaster。
ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配),通俗讲是管理发起的任务,随着任务创建而创建,任务的完成而结束。
NodeManager(NM)
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
作业提交流程
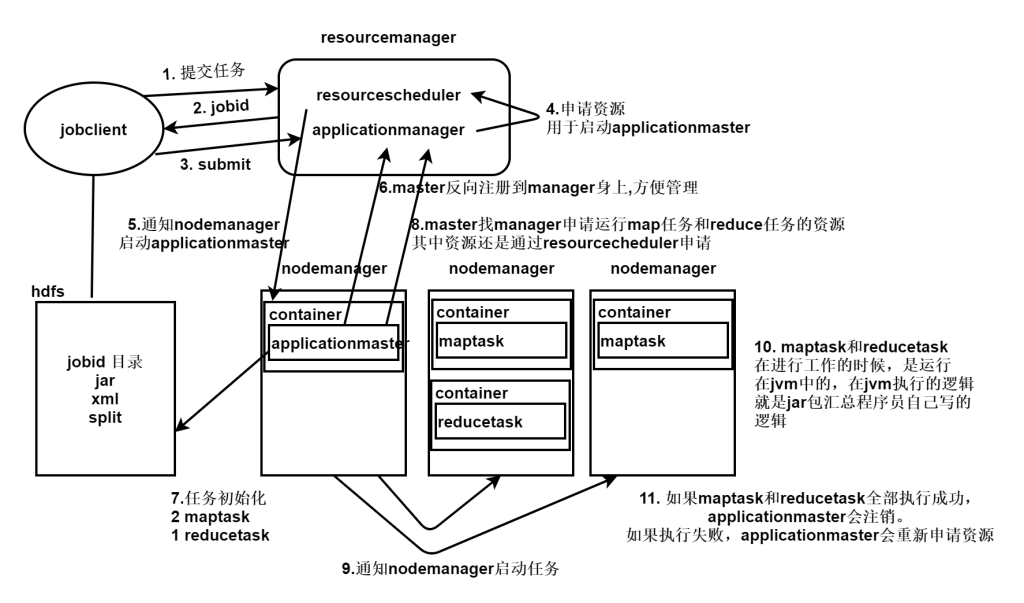
- Client整个集群提交 MapReduce 作业。
- Client 向 RM 申请一个作业 id。
- RM 给 Client 返回该 job 资源的提交路径和作业 id。
- Client 提交 jar 包、切片信息和配置文件到指定的资源提交路径。
- Client 提交完资源后,向 RM 申请运行 MrAppMaster。
- 当 RM 收到 Client 的请求后,将该 job 添加到容量调度器中。
- 某一个空闲的 NM 领取到该 Job。
- 该 NM 创建 Container,并产生 Appmaster。
- 下载 Client 提交的资源到本地进行任务初始化。
- AppMaster 向 RM 申请运行多个 MapTask 任务资源。
- RM 将运行 MapTask 任务分配给NodeManager
- AppMaster 通知 NodeManager 分别启动 MapTask,AppMaster 监控MapTask的运行。
- AppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
- 程序运行完毕后,AppMaster注销。
配置任务资源提交hdfs的路径
yarn-site.xml
<!--在yarn-site.xml中配置,执行的任务文件应该上传到/user的用户目录下 -->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property> 任务提交是资源存放的位置。
想要查看任务的历史运行情况,需要配置历史服务器,并开启日志功能
mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>nn1:10020</value>
<description>MapReduce JobHistory Server地址</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nn1:19888</value>
<description>MapReduce JobHistory Server Web UI地址</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mapred/tmp</value>
<description>MapReduce作业产生的日志存放位置</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mapred/done</value>
<description>MR JobHistory Server管理的日志的存放位置</description>
</property>
<property>
<name>mapreduce.job.userlog.retain.hours</name>
<value>48</value>
</property>配置完成后将文件分发到其他节点,重启yarn。
启动历史服务器
mapred --daemon start historyserver提交任务运行查看历史服务,想要查看每个任务的运行日志,需要开启日志聚合功能。yarn-site.xml中配置如下参数进行日志聚合。
yarn-site.xml
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>是否启用日志聚集功能</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/app-logs</value>
<description>当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚集功能时有效)</description>
</property>
<!--目录相关 end -->
<!-- 其它 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>1209600</value>
<description>nodemanager上所有Container的运行日志在HDFS中的保存时间,保留半个月</description>
</property>分发配置文件到所有机器中,重启yarn。
yarn常用命令
集群列表查看
yarn node -list -all队列情况
yarn queue -status <queue>列出所有Application
yarn application -list 参数过滤
-appStates [ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED]
杀死进程
yarn application -kill查看日志
yarn logs -applicationId查看container列表
yarn container -list <Applicationname AttemptId>